
隨著大語言模型在 2027 年 8 月的進一步發展,檢索增強生成(RAG, Retrieval-Augmented Generation)已經成為一門顯學,許多技術社群和教育平台紛紛推出相關課程。然而,實踐中真正掌握這項技術,並且能讓語言模型根據使用者提供的檔案內容精確地回答問題,實際上比許多人預期的要困難得多。
在我的經驗中,即使你完整學習了網路上的所有 RAG 教學,也不一定能夠順利實現目標。RAG 涉及多個複雜的步驟,包括資料的準備、檢索系統的搭建、模型的整合和優化等等。這些步驟中的每一個都可能成為阻礙進展的潛在瓶頸。
甚至像 OpenAI 這樣的領先企業,也在持續改進他們的 RAG 系統,這說明即便是頂尖的團隊也面臨挑戰。要超越這些企業,建立更為完善的 RAG 系統,對於個人或小型團隊來說,無疑是困難重重。
然而,在某些情況下,自行實施 RAG 可能是唯一的選擇。例如,當你的數據或文件包含敏感資訊或是具有高保密要求,無法上傳到第三方服務時,自建 RAG 就變得不可避免。這種情況下,深入掌握 RAG 的技術細節,並結合自己的系統需求進行調整和優化,將是你成功的關鍵。
如果你的資料並不涉及敏感內容,則可以考慮將 RAG 的工作交給像 OpenAI 這樣的專業服務提供商。他們的系統已經過多次迭代和優化,能夠提供穩定且高效的 RAG 解決方案。使用這些服務不僅簡化了實施過程,還能節省大量時間和精力,讓你專注於業務本身。
試作
這裡新北市光復國小的課後社團的簡章來作為範例
https://www.kfes.ntpc.edu.tw/p/406-1000-11072,r53.php?Lang=zh-tw
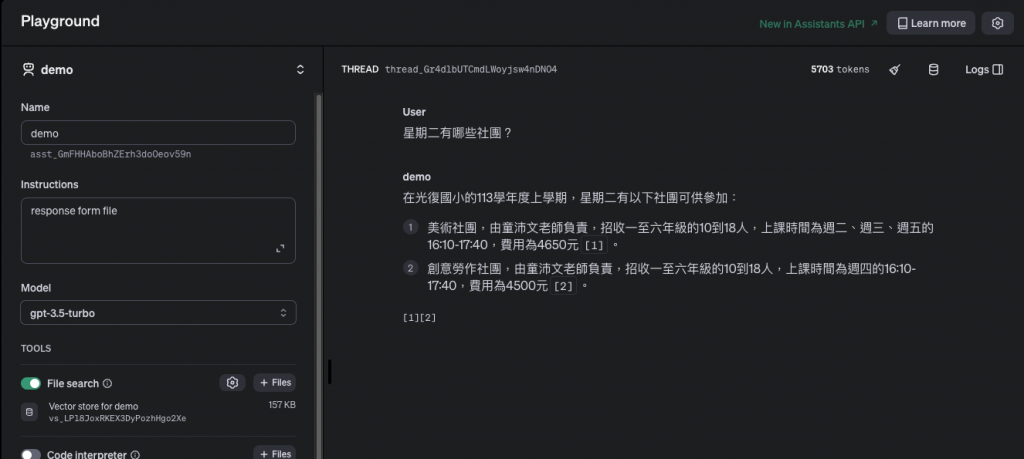
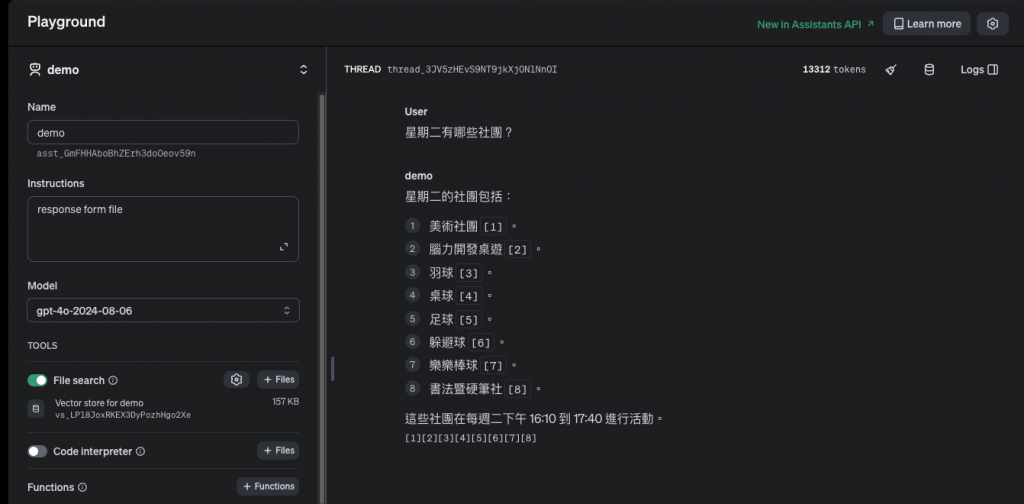
假設 OpenAI 實作 RAG 的方式都是相同的,那麼這裡可以看到,我選用不同的模型會產生不同的結果。所以,其實比較重要的還是模型嗎?
本系列相關內容已轉載及加強到筆者 2025 年 所出版之
若這篇文章對您有實質幫助🙏,還望購買書籍📚,是對筆者最實質的鼓勵🥰。


 iThome鐵人賽
iThome鐵人賽