今天的內容會根據主要參考書的第六章篇幅來展開。
深度強化學習的蒙地卡羅樹搜尋演算法,有以下幾步:
上述還沒有定義清楚的是平衡函數和更新,兩個項目。
一個能夠平衡地選擇利用最大勝率選項和探索可能選項的方法不只這一種,書中也層提及
UCB之類的方法。我的感覺是,能夠說得出道理來就有定性的依據,定量上的差異就需要分析細微的數學特性了。
這裡我採用的是書中的 PUCT 公式,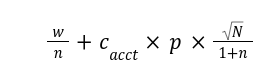
其中,
w 是總勝負值,因為從上述第三步的兩種數值來看,1 代表勝利,-1 代表失敗,而如果是價值網路估計的值,也是經過 tanh 算子處理之後輸出的結果,一樣落在這個區間內。n 是針對的子節點被造訪的次數,所以 w/n 這一項就可以看做是期望勝負值。如果每走過必勝,則這個值會是 1;反之如果每走過必敗,這個值就是 -1。這個期望勝負值也可以視作是代表值得利用與否的一個項。N 是所有的子節點被造訪的次數。這出現在分子,所以如果其他的子節點一直都在被造訪(可能是因為它們的期望勝負值不錯),那麼,較少被造訪的子節點本身就會因為相對小的 n 值在分母,而有較大的值,解讀為更加的值得探索。每個節點中需要維護的項是 w 和 n。前者就是累加價值網路判定的價值,後者則是有走到就增加 1。
更新的時機如上述,在模擬到一個終局狀況的時候,回傳確切的勝負值;或是,模擬到一個新盤面、需要幫它展開它的子節點(由可能著手衍生的後續盤面),然後回傳由模型推論而來的勝負值。
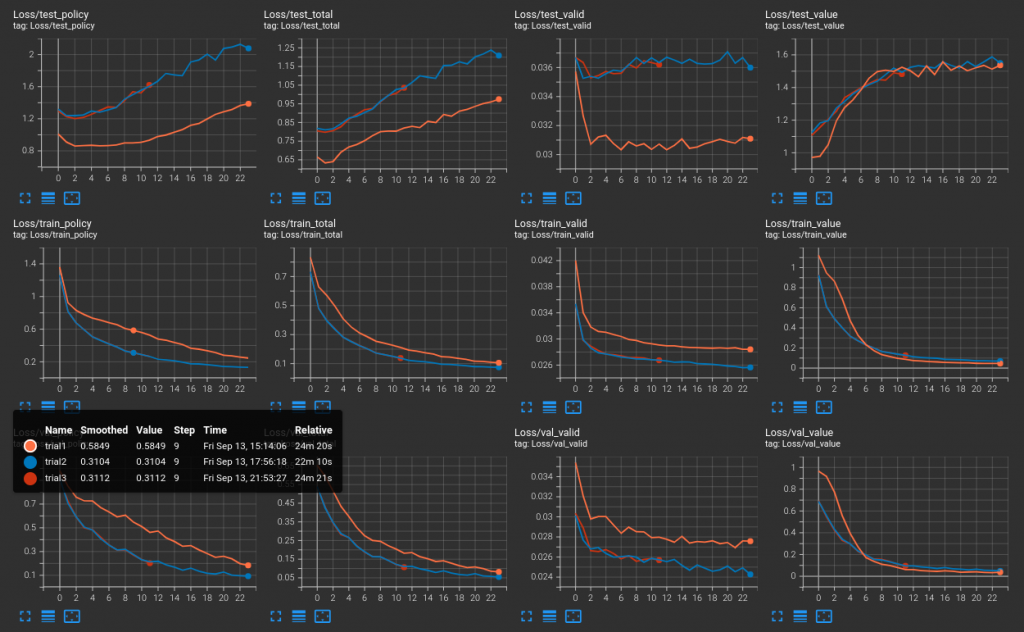
昨日的狂喜又冷卻了些。由昨天展示的模型模擬收集資料(我現在才發現,我已經提過很多次資料,但尚未介紹資料集的收集,以及它和蒙地卡羅模擬之間的關聯。這將在後續文章補述)之後,以三種模式訓練
可以看到後兩者對於驗證集的預測性不高。說老實話,策略和價值的預測性不高我可能都覺得不算非常嚴重,但是為什麼合法性,會有問題呢?這是潛在可能有 bug 的地方,因為理論上,兩套資料收集方法都是由一樣的方式取得合法著手資料。
客觀的評比的是實戰效果,第二種的實戰效果很差。所以這一輪的訓練很難說有成功之處。
這個專案過程中有無數的小決策,我未必能夠在系列文當中與讀者諸君分享。像現在下一步該如何?重新整理一次,也就是說,原本 AlphaZero 的精神是完全仰賴自我對弈資料來訓練,但我認為隨機生成的策略和價值太飄移,透過蒙地卡羅樹搜尋來積累出正確的策略或是價值預測,以至於能夠真正影響到收集的資料,需要耗費太多時間;所以,我透過殘局譜的方式,可以把它當作 bootstrap,而且實戰效果也不錯,又同昨日的展示,驗證集顯示的汎用性是有學習起來的感覺。
但是之後我可以繼續以新的盤面的殘局譜去訓練它嗎?這是不合理的,因為棋感不是只有終局前的一、兩手,而應該是全局的,所以只靠殘局訓練是不合理的;但是直接開始接回 AlphaZero 的正軌嗎?開始收集對局資料來訓練?
其實我認為眼前最嚴重的問題可能是時間。只剩下 16 天,但有兩個關鍵元件還沒打通,
而且雖然無法向讀者諸君透露細節,但是不巧,工作一件一件的襲來!太刺激啦!BTW 提到工作,昨天的目前狀況在盤點接下來有哪些主題,著實可笑,因為這個代理人是很正統的 ResNet 結構,屆時應該可以用來展示 Andes 的 AndesAIRE 當中的 NNPilot 工具,它可以降低模型佔用的空間,並且將它編譯到板子上運行!所以到時候有個延伸是把我們 SDK 補上 socket,和 host 上的伺服器連接,直接與公司的開發版對戰......要打通的事情可多了,未必會走到那條路,姑且當我說說吧。

