「...我帶著山羊在山上時,想著這點,白晝似乎永無止境,但在夜幕降臨前,時間又像靜止不動,然後又是早晨......我領會羊的智慧。...」
-- <地海孤雛>,娥蘇拉.勒瑰恩著,段宗忱譯
雖然這個題目不在先前的列表裡面,但是仔細想想,在 DeltaPathogen 專案裡面,最不熟悉的的確是這些資料工程與機器學習實踐的交會區域。與其他元件比較的話就清楚多了。就說整個遊戲引擎吧,雖然是使用 Rust 這個陌生語言,但是至少也不脫通用程式設計的範疇,語法、語意、標準函式庫有點概念之後,加減可以做得出來;再說遊戲伺服器,雖然定義抽象定義的差強人意,但也一路隨著需求擴充起來,沒有什麼問題;再說深度學習,pytorch 實在太好用,而且再加上一切使用菜市場組合(損失函數全用經典款、優化器只用 adam、殘差塊全用經典款、...),幾乎是 ChatGPT 直接吐出來的 pytorch 就能用(AI 最懂 AI(???));AlphaZero 需要的蒙地卡羅,則是樹的資料結構活用,雖然我的系統先於訓練架構讓這件事情有點困難(請參考 Day14~Day16),但也沒有狀態機克服不了的事情。
所以反倒是,收集資料之後,手動迭代、手動部署、手動收集、手動思考(?),這些需要很零碎的投入。老樣子,我也一樣是不學無術,一樣是沒有好的答案,一樣只能提供這個專案中的軌跡。以下我會展開一些我使用過的 script,展示一下我的機器學習工作流程。
由於 share 資料夾內只有各個世代的實驗總結,因此以下的資料都只在我本地端存在。在 github 上撈不到是正常的,但可參考
share/template的歷史變化,大致上可以對照趨勢。
由於是手忙腳亂的開始,還看不出什麼架構。當時的構想是模擬、訓練、驗證對局是三個平衡且分立的階段。現在就比較傾向於將模擬和驗證整合在一起,有提供產出資料集路徑作為參數的時候就請它模擬,而沒有提供的時候就請它驗證遊玩。
首次看到 driver.sh,這裡是在 play 階段第一次出現
#/bin/bash
TRIAL=1000
PE_ROOT=/home/alankao/PathogenEngine/examples
THIS_ROOT=$MNT/$(hostname)_$(date --utc +%Y%m%d%H%M%S)
###
### MNT 是因為這些都會在容器環境之中,而我一般來說使用
### docker run -u alankao -w /home/alankao/PathogenEngine -v $(pwd)/share:/mnt -it pathogen:base-cpu bash
### 指令將相關的資料夾掛載進去。
###
mkdir -p $THIS_ROOT
ITER=0;
###
### 維護一個迴圈執行 TRIAL 次數。使用 `shuf` 增加多樣性是當時的作法。
###
for I in $(ls $MNT/setups | shuf); do
echo $ITER;
###
### 這時候的 coord_server 一次只吃一個設置盤面,所以需要這個迴圈來包裝。
###
RUST_BACKTRACE=1 cargo run --release --example coord_server -- \
--load $MNT/setups/$I \
--save $THIS_ROOT/$I
ITER=$(($ITER + 1));
sleep 1
if [ $ITER -ge $BATCH ]; then
exit 0
fi
done &
sleep 1
###
### 這個一秒的延遲有時也不夠用,因為 cargo 偵測到程式碼改動會自動編譯,編個兩三秒也是很正常的,
### 所以的確不太理想,蠻常需要自己調整,比方說下面的 coord_client 打起來發現伺服器不存在而死亡,
### 然後 coord_server 才姍姍來遲。
###
python $PE_ROOT/coord_clients/main.py -t Reinforcement -s Doctor -b $BATCH --dataset "$THIS_ROOT/dataset" &
python $PE_ROOT/coord_clients/main.py -t Reinforcement -s Plague -b $BATCH --dataset "$THIS_ROOT/dataset"
wait
find $THIS_ROOT -type f -size 0 -name '*.log' -delete
###
### 前幾日提過我有給代理人模擬的時候下**延遲開始模擬的手數**的參數,這其實和我後來的殘局譜概念類似,
### 就是覺得越靠近終盤,應該有越容易判斷的盤面,所以從那時開始模擬收集資料再加以訓練,應該可以讓結果比較穩定。
### 但缺點就是,有時候遊戲還沒有到延遲手數,就結束了(比方說設定 10,而疫病方在 Phase::Main(19) 結束遊戲,雙方都還沒數到 10。),
### 這時就會有空的資料集檔案輸出,很礙眼,所以這裡用 `find` 簡單刪去。
###
### 為什麼不在程式裡面自己決定如果沒資料就別寫檔案出來?Well,可是我一定是先 open 起來放著看要不要寫入的...
### 是可以改啦,但就是也沒那麼困擾。
###
# Use this to check the dataset size easily
# SUM=0; for S in $(find -name '*Doctor*.log' -exec bash -c 'echo $(($(ls -l {} | awk '"'{print \$5}'"')/4096))' \;); do SUM=$(($S+$SUM)); done; echo
$SUM
###
### 這個可能也蠻瞎的,但就是持續用了好一陣子的功能。因為盤面資料加上模擬資料的大小沒有那麼剛好,所以我把它 padding 到 4096 個 byte 去,希望它這樣對硬碟讀寫比較友善(其實也沒有驗證實際上有沒有)。
### 由於有時候會 Ctrl+C 中斷模擬,收集到的資料就有可能還沒 padding 或者處在資料寫了一部份的狀況,這時候用 bash 內建的除法其實還看不出來有沒有整除,但總之可以估計目前收集了幾筆資料。
###
其實我每個階段的資料夾(可參考
share/template的結構)裡面都會存在幾個 `driver.sh,其中略有不同。為什麼沒有參數化?可能還沒有完全走到那一步,而且過程中也一直在調整。
上述腳本在後來的模擬與驗證遊玩階段都還有持續被應用,也有小幅的改變。
按照本地端的紀錄,這個在 8/12 開始第一次使用,8/24 就沒有再出現了,但期間都是靠這一套來驅動驗證遊玩。
#!/bin/bash
ROOT=/home/alankao/PathogenEngine
MNT=/mnt/20240818_gen4
PLAY_ROOT=$MNT/play
TRAIN_ROOT=$MNT/train
NUM_REPEAT=10
function play_single()
{
REC=$PLAY_ROOT/records/$(echo d-$D_CONFIG-p-$P_CONFIG | sed -e 's/\//#/g')
###
### 這裡是想要呈現對戰組合的觀念。雖然在[對偶網路]()一文當中已經提及我無暇顧及多種版本,但當時還沒有足夠深刻的體悟。
### 但有一點很雷,就是這裡是使用 `D_CONFIG` 這樣的全域變數,而非函數傳入值。後來出了點小烏龍。
###
NUM_SETUP=$(ls $PLAY_ROOT/setups | wc -l)
NUM_BATCH=$(($NUM_SETUP * $NUM_REPEAT))
mkdir -p $REC
for i in $(seq 1 $1); do
find $PLAY_ROOT/setups -name '*.sgf' -exec bash -c 'cargo run --example coord_server --release -- --load {} --save '"$REC"'/$(basename {})'".$i"' && sleep 1' \; ;
###
### 拼湊這種複雜的 shell 指令,其實也花了一點力氣才讓單引號和雙引號不至於打架。
###
done &
if [ $2 == "random" ]; then
python $ROOT/examples/coord_clients/main.py -t Query -s Plague -b $NUM_BATCH --seed $4
else
python $ROOT/examples/coord_clients/main.py -t ReinforcementPlay -s Plague -m $2 -b $NUM_BATCH | $PLAY_ROOT/stat.awk | tee $REC/p.log
fi &
###
### 我有點懷念這個功能,就是將 random 直接代換成 Query player。還有,將結果 pipe 給 `stat.awk`,
### 是因為我在遊玩過程中有些統計數據,希望可以加總起來呈現一些比率之用。這些數據我後來就沒有追蹤了...
###
if [ $3 == "random" ]; then
python $ROOT/examples/coord_clients/main.py -t Query -s Doctor -b $NUM_BATCH --seed $4
else
python $ROOT/examples/coord_clients/main.py -t ReinforcementPlay -s Doctor -m $3 -b $NUM_BATCH | $PLAY_ROOT/stat.awk | tee $REC/d.log
fi &
wait
echo $REC
python $PLAY_ROOT/stat.py $REC
echo "==="
}
SEED=6533
P_CONFIG=random
D_CONFIG=random
play_single $NUM_REPEAT $P_CONFIG $D_CONFIG $SEED
###
### 這個迴圈算是很認真展開的了,有讓蠻多個不同 epoch 的模型參戰
###
for i in $(seq 1 23) $(seq 24 12 60) $(seq 72 24 120); do
P_CONFIG=$TRAIN_ROOT/general.pth.$i
D_CONFIG=random
play_single $NUM_REPEAT $P_CONFIG $D_CONFIG $SEED
P_CONFIG=random
D_CONFIG=$TRAIN_ROOT/general.pth.$i
play_single $NUM_REPEAT $P_CONFIG $D_CONFIG $SEED
P_CONFIG=$TRAIN_ROOT/general.pth.$i
D_CONFIG=$TRAIN_ROOT/general.pth.$i
play_single $NUM_REPEAT $P_CONFIG $D_CONFIG $SEED
done
訓練的部份一直都蠻簡潔的,八月中以前甚至也沒有用腳本紀錄下來,而是在 shell 直接 Ctrl+R 就可以修修改改。
#!/bin/bash
TRIAL_ROOT=/mnt/20240822_gen6
pushd examples/coord_clients
python reinforcement_trainer.py -d $TRIAL_ROOT/simulation/plague.train.bin \
-t $TRIAL_ROOT/simulation/plague.eval.bin \
-m $TRIAL_ROOT/train/plague-trial2.pth -n $TRIAL_ROOT/train/runs/gen6-trial2
popd
一般來說都是用 nvidia-container 來訓練,讓它待在 PathogenEngine 專案的根目錄,這樣 pushd 就有地方可以去。-d 和 -t 準備兩個資料集,然後 -m 載入從哪個 model 開始這一輪的訓練。不存在的話會自動生成一個隨機的。之後每個 epoch 就會像 .pth.x 加上 x 後綴數字。-n 是輸出 tensorboard 可以吃的資料格式。
隨著系列文展開,發現訓練進度不利,而開發導入的殘局譜蒐集機制搭配的腳本,
#/bin/bash
BATCH=1000
TSUME_SET=20
BATCH_RATIO=1
SIM_ROOT=$PE_ROOT/../share/20240910_gen15/simulation/tsume
SETUP_ROOT=$SIM_ROOT/setups
###
### 大致上類似模擬腳本的結構
###
function sim_r2r()
{
THIS_ROOT=$SIM_ROOT/$(date +%Y%m%d%H%M%S)
mkdir -p $THIS_ROOT
RUST_BACKTRACE=1 cargo run --release --example coord_server -- \
--load-dir $SETUP_ROOT \
--save-dir $THIS_ROOT \
--batch $BATCH &
sleep 3
nc -vz 127.0.0.1 3698 & nc -vz 127.0.0.1 6241
###
### 使用 [Day8]() 文章中最後提及的手法,高速收集隨機局譜。
###
wait
sleep 3
}
function prepare_setup(){
if [ -d $1 ]; then
return
fi
mkdir -p $1
###
### 如果存在就不做以下的設置開局,如果不存在則創立一個然後以 `setup_generator` 生成指定數量的設置開局譜
###
pushd $PE_ROOT
for _ in $(seq 1 $(($BATCH/$BATCH_RATIO))); do id=$(uuidgen);
RUST_BACKTRACE=1 cargo run --release --example setup_generator -- \
--mode sgf --seed "$(echo $id | sed -e 's/-//g')" --save "$1/$id.sgf";
done
popd
}
prepare_setup $SETUP_ROOT 2>/dev/null
for i in $(seq 1 $TSUME_SET); do
sim_r2r
done
###
### 生成設置 + 對局,所以以下就可以接殘局譜的生成了。
###
cargo run --release --example tsume_generator -- -l $SIM_ROOT --dataset extra_tsume.raw.bin
昨日所謂意料之外的展開,
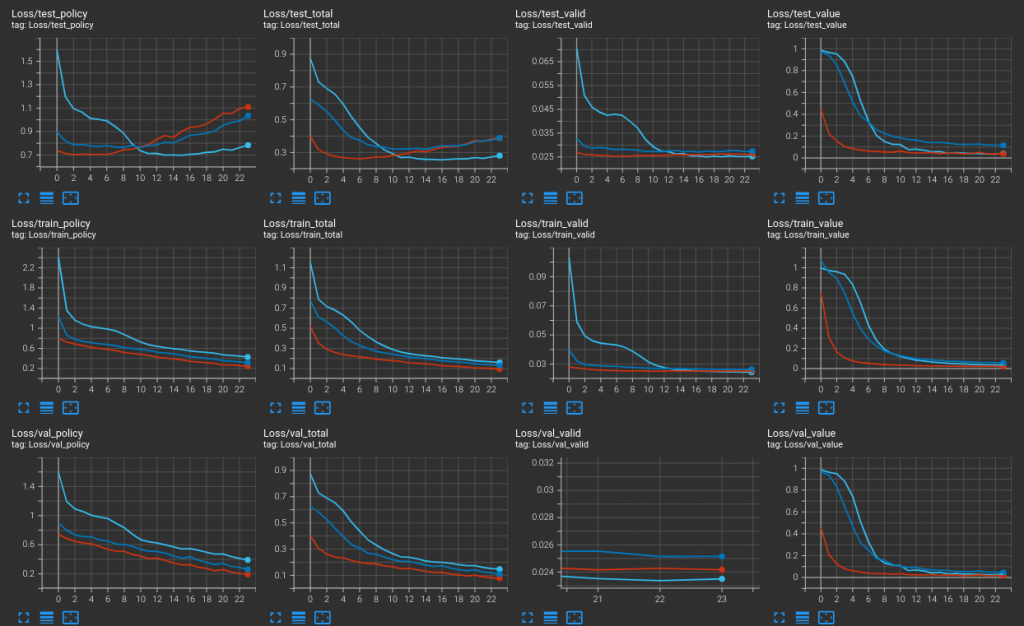
是在說這條淺藍色的訓練曲線。它在 test(上排項目)當中的表現比紅色的好,這令我有點意外。它原本只是作為一個參照。
簡單來說紅色和淺藍所使用的資料集(訓練與驗證)還有所有參數都一樣,但起始點不同:紅色是以前天我說看起來「享有紀錄族譜的榮耀感」的最新模型(第十八世代的第一批訓練)開始的,它的實戰看起來還不錯;淺藍色則是再回溯,是從殘局譜訓練的模型(第十六世代的第二批訓練)開始的。
單以 AlphaZero/AlphaGo 的精神來看,參考書上說前者比起初代的後者省略了驗證遊玩,單是不斷對局不斷訓練之後,就能夠慢慢變強,但書中因為認為驗證遊玩的過程有助於收斂,所以還是將 AlphaGo 的這個方法加入。但,按照我這裡所經歷的,真的是鬆懈不得。前天之前都曾設想過一些接下來可能的發展,但也沒有想到有一種發展竟然是這樣。但從實績看來,它的確能夠以 60% 勝率擊敗醫療方的 Random,是目前為止收集到的最高。
所以目前我在用這個版本的代理人自我對戰中,但是訓練出來的資料又應該從哪裡開始訓練呢?是否又應該從第十六世代開始?或是往前從根源開始?或是從現在的第十九世代開始?
茫然,但也只能趁現在盡快進行網頁對局的設計。


 iThome鐵人賽
iThome鐵人賽