Spring AI 的設計上並沒將 RAG 當成一個流程,他的概念反而比較像是一個個外掛模塊,今天凱文大叔介紹一下怎麼實作Advanced RAG中的 Re-ranking
在Advanced RAG 的技巧中,主要分為檢索前優化、檢索優化與檢索後優化
-檢索前優化:前面做過的關鍵字(Keyword)與摘要(Summary)就是這個部分的優化,這裡用的技巧主要讓分塊的內容能包含更多資訊,想辦法讓分塊被索引到時能帶出更多本文內容
-檢索優化:基本上檢索就是靠 Embedding,我們前面換 Embedding 模型就是其中一種優化方式,另外若能搭配關鍵字搜索將兩者結果做一個整合,就是 Hybrid Search 的原理
-檢索後優化:這裡的優化主要在強調檢索後所做的動作,其中最有效的方法就是 Re-ranking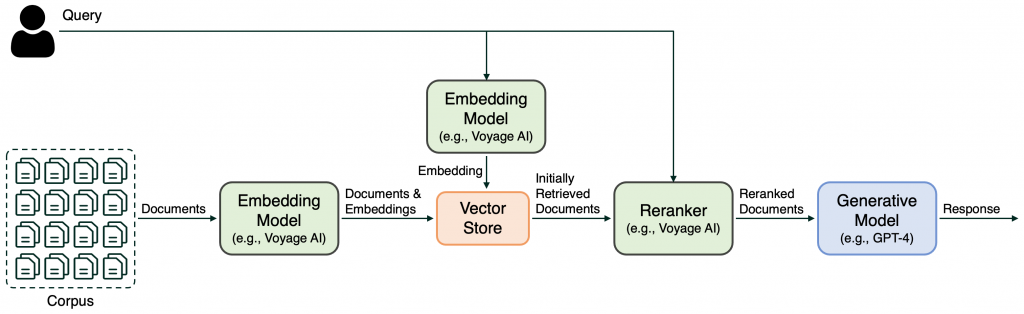
Voyage AI 的介紹指出 Re-ranker 將查詢內容與相近查詢得到的結果,進行更為精準的比較,並重新排列相關性分數.(除了這些以外 Re-ranker 也比較貴XD)
Re-ranker 雖然準但有個致命的缺點就是速度慢,所以如上圖的做法,我們會將近似查詢的結果再交由 Re-ranker 處理,這樣才不用全部用 Re-ranker 模型跑,只需將篩選過的資料重排,再挑出前幾個交給 LLM 生成資料
很可惜的是 Spring AI 在 ETL 以及近似查詢的部分都做得還不錯(雖然有 Bug 但整體寫起來容易上手),但似乎完全沒考慮查到的資料還能進行優化的動作,程式就直接將結果組成 prompt 了,下面是 RAG 的原始碼片段
public AdvisedRequest adviseRequest(AdvisedRequest request, Map<String, Object> context) {
// 1. Advise the system text.
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.withQuery(request.userText())
.withFilterExpression(doGetFilterExpression(context));
// 2. Search for similar documents in the vector store.
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
context.put(RETRIEVED_DOCUMENTS, documents);
// 3. Create the context from the documents.
String documentContext = documents.stream()
.map(Content::getContent)
.collect(Collectors.joining(System.lineSeparator()));
// 4. Advise the user parameters.
Map<String, Object> advisedUserParams = new HashMap<>(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request)
.withUserText(advisedUserText)
.withUserParams(advisedUserParams)
.build();
return advisedRequest;
}
檢索後優化就需要在第 2 步跟第 3 步之間進行處理,雖然我們也可以不管它,另外寫個 Advisor 覆蓋前面的資料,不過第 3 步會花上不少時間,尤其我們要做 Re-ranker 時通常會拿更多的 Embedding 資料來處理,如果這些資料要先組成字串就非常浪費時間跟記憶體了
所以跟之前改 Bug 一樣,我們直接把 QuestionAnswerAdvisor.java 複製出來改寫成有 Re-ranker 的 RAG 吧
public class RerankRAGAdvisor implements RequestResponseAdvisor {
private static final String DEFAULT_USER_TEXT_ADVISE = """
Context information is below.
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
""";
private final VectorStore vectorStore;
private final String userTextAdvise;
private final SearchRequest searchRequest;
public static final String RETRIEVED_DOCUMENTS = "qa_retrieved_documents";
public static final String FILTER_EXPRESSION = "qa_filter_expression";
/**
* 下面由凱文大叔改寫,歡迎複製修改
*/
private final RestClient restClient;
private String apiKey= System.getenv("VOYAGE_KEY");
// 由Re-ranking API 取回的資料
@JsonInclude(Include.NON_NULL)
public record RerankList(
@JsonProperty("object") String object,
@JsonProperty("data") List<Rerank> data,
@JsonProperty("model") String model,
@JsonProperty("usage") Usage usage) {
}
@JsonInclude(Include.NON_NULL)
public record Rerank(
@JsonProperty("index") Integer index,
@JsonProperty("relevance_score") float relevanceScore,
@JsonProperty("document") String document) {
}
//Re-ranking API,因為沒其他地方要用,加上 Spring AI 有計畫在下個版本加入 Re-ranking,所以只簡單用個函式呼叫
public ResponseEntity<RerankList> rerankDocuments(String query, List<Document> documents) {
String url = "https://api.voyageai.com/v1/rerank";
String bearerStr = "Bearer "+this.apiKey;
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("query", query); //User 查詢資料
requestBody.put("model", "rerank-1"); //Voyage 這個 Re-rank 模型支援多語系
requestBody.put("top_k", 5); //重排後取幾筆
requestBody.put("return_documents",true); //重排的內容是否包含 context
requestBody.put("documents", documents.stream().map(Document::getContent).toList());
//需要重排的內容list
return restClient.post()
.uri(url)
.contentType(MediaType.APPLICATION_JSON)
.header("Authorization",bearerStr)
.body(requestBody)
.retrieve()
.toEntity(new ParameterizedTypeReference<>() {
});
}
//建構子加上RestClient,用來呼叫API
public RerankRAGAdvisor(RestClient restClient, VectorStore vectorStore) {
this(restClient, vectorStore, SearchRequest.defaults(), DEFAULT_USER_TEXT_ADVISE);
}
public RerankRAGAdvisor(RestClient restClient, VectorStore vectorStore, SearchRequest searchRequest) {
this(restClient, vectorStore, searchRequest, DEFAULT_USER_TEXT_ADVISE);
}
public RerankRAGAdvisor(RestClient restClient, VectorStore vectorStore, SearchRequest searchRequest, String userTextAdvise) {
Assert.notNull(restClient, "The restClient must not be null!");
Assert.notNull(vectorStore, "The vectorStore must not be null!");
Assert.notNull(searchRequest, "The searchRequest must not be null!");
Assert.hasText(userTextAdvise, "The userTextAdvise must not be empty!");
this.restClient = restClient;
this.vectorStore = vectorStore;
this.searchRequest = searchRequest;
this.userTextAdvise = userTextAdvise;
}
@Override
public AdvisedRequest adviseRequest(AdvisedRequest request, Map<String, Object> context) {
// 1. Advise the system text.
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.withQuery(request.userText())
.withTopK(100) //第一次近似搜尋取回的結果,個人覺得可以設50~100,自己比較一下成效
.withFilterExpression(doGetFilterExpression(context));
// 2. Search for similar documents in the vector store.
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
// 3. Re-ranking
List<Rerank> rerankDocs = rerankDocuments(request.userText(), documents).getBody().data();
context.put(RETRIEVED_DOCUMENTS, rerankDocs);
// 4. Create the context from the documents.
// 加入Prompt的上下文改由 Re-ranking 後的資料組成
String documentContext = rerankDocs.stream()
.map(Rerank::document)
.collect(Collectors.joining(System.lineSeparator()));
// 5. Advise the user parameters.
Map<String, Object> advisedUserParams = new HashMap<>(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request)
.withUserText(advisedUserText)
.withUserParams(advisedUserParams)
.build();
return advisedRequest;
}
//後面都保持不變
@Override
public ChatResponse adviseResponse(ChatResponse response, Map<String, Object> context) {
ChatResponse.Builder chatResponseBuilder = ChatResponse.builder().from(response);
chatResponseBuilder.withMetadata(RETRIEVED_DOCUMENTS, context.get(RETRIEVED_DOCUMENTS));
return chatResponseBuilder.build();
}
@Override
public Flux<ChatResponse> adviseResponse(Flux<ChatResponse> fluxResponse, Map<String, Object> context) {
return fluxResponse.map(cr -> {
ChatResponse.Builder chatResponseBuilder = ChatResponse.builder().from(cr);
chatResponseBuilder.withMetadata(RETRIEVED_DOCUMENTS, context.get(RETRIEVED_DOCUMENTS));
return chatResponseBuilder.build();
});
}
protected Filter.Expression doGetFilterExpression(Map<String, Object> context) {
if (!context.containsKey(FILTER_EXPRESSION)
|| !StringUtils.hasText(context.get(FILTER_EXPRESSION).toString())) {
return this.searchRequest.getFilterExpression();
}
return new FilterExpressionTextParser().parse(context.get(FILTER_EXPRESSION).toString());
}
}

