雖然主題是 Spring AI, 不過沒前端總覺得少了什麼,所以特別整理一篇前端開發類似 ChatGPT 網頁需注意的重點,先來看看成果吧
這次後端的部分使用 Day4 的程式碼,使用 Spring AI 做流式輸出有個特別的地方 Flux<String> chatModel.stream(prompt) prompt 若使用 String 則回傳得資料也會是 String 的片段,不過也因此在處理上有些莫名其妙的問題,若想使用 Event 的方式處理訊息最好使用 Prompt 物件來傳送內容,這樣回傳資料就會是 Flux<ChatResponse>,前端處理時使用 Json 比較不用處理特殊符號
LLM 輸出的內容基本都是 Markdown 格式,以使用 React 為例,輸出對話使用 MUI 的 List元件,若要能呈現 Markdown 效果還是需要另外安裝 Markdown 元件,另外要支援 code 語法還需要安裝插件
import ReactMarkdown, { Components } from 'react-markdown';
import remarkGfm from 'remark-gfm';
import remarkEmoji from 'remark-emoji';
import remarkToc from 'remark-toc';
import remarkMath from 'remark-math';
import remarkSlug from 'remark-slug';
import rehypeKatex from 'rehype-katex';
import rehypeAutolinkHeadings from 'rehype-autolink-headings';
import { Prism as SyntaxHighlighter } from 'react-syntax-highlighter';
import { atomDark } from 'react-syntax-highlighter/dist/esm/styles/prism';
const renderers: Components = {
code( {node, inline, className, children, ...props}: any ) {
const match = /language-(\w+)/.exec(className || '');
return !inline && match ? (
<SyntaxHighlighter
style={ atomDark as any}
language={match[1]}
PreTag="div"
{...props}
>
{String(children).replace(/\n$/, '')}
</SyntaxHighlighter>
) : (
<code className={className} {...props}>
{children}
</code>
);
}
};
//下方為 react 元件使用 ReactMarkdown 的方式
<ReactMarkdown
remarkPlugins={[remarkGfm, remarkEmoji, remarkToc, remarkMath, remarkSlug as any]}
rehypePlugins={[rehypeKatex, rehypeAutolinkHeadings]}
components={renderers}>
{message.text}
</ReactMarkdown>
流式輸出雖然使用 SSE 技術,不過標準 SSE 只支援 Get 方法,而 Get 方法瀏覽器又不支援傳送 Json,原本想裝微軟的 fetchEventSource,可支援 Post 也能處理 SSE,可是不知為什麼回傳的內容空白都會消失,最後還是用 fetch 加上 useState 來處理打字機效果
使用 fetch 有以下幾個步驟
a. 因為 Stream 會不斷推送資料,Reader 讀取後結果會包含 done : boolean 以及 value : Uint8Array,當 done 是 false 時表示資料還沒傳送完,可以寫一個無窮迴圈,當 done 為 true 才跳出迴圈
b. value 型態是 Uint8Array,須透過 decoder 轉回 utf8
c. 因為不是使用 Event 方式接收資料,所以可能好幾個片段一起傳送過來,這時可用下面方式取得正確內容
const jsonChunks = chunk.split('data:').filter(Boolean);
for (let jsonChunk of jsonChunks){
newTemp += jsonChunk.replace(/\n\n/g, '');
}
SSE 傳送的資料前都會有 data: 所以需要先用這個字串拆成小片段,另外內容可能包含一些空字串,所以後面可再使用 .filter(Boolean) 過濾不要的資料
最後因為每個 data 最後都是 \n\n 結尾,我們可使用 .replace(/\n\n/g, '') 去除
List 最下面可以放置一個 ListItem,搭配useState處理最新回覆的打字機效果,其他舊訊息使用陣列存放,最新回覆處理完後也要加入訊息陣列,陣列的內容需要額外加上是用戶傳送還是 LLM 回傳,透過css就能做到對話的泡泡框
setMessages([...messages, {text:newMessage, sender: 'bot'}]);
需要中斷回覆要使用 AbortController 元件,並加入傳送的封包中,只需要做一個暫停按鈕觸發 Abort 就能停止傳送資料
const controller = new AbortController();
const promptBody:PromptBody = { 'prompt': prompt };
const response = await fetch('http://localhost:8080/stream', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(promptBody),
signal: controller.signal,
});
//後面需要暫停時呼叫以下指令
controller.abort();
另外最近 OpenAI 釋出了 realtime 模型,這裡又使用另一個後端主動推送的技術 Websocket,websocket 與一般 http 傳輸最大的差別就是建立連線後雙向可全雙工傳輸資料,而 OpenAI 提供的架構中,用戶並非直接對到 API,而是需要一個中間層作為雙方的橋樑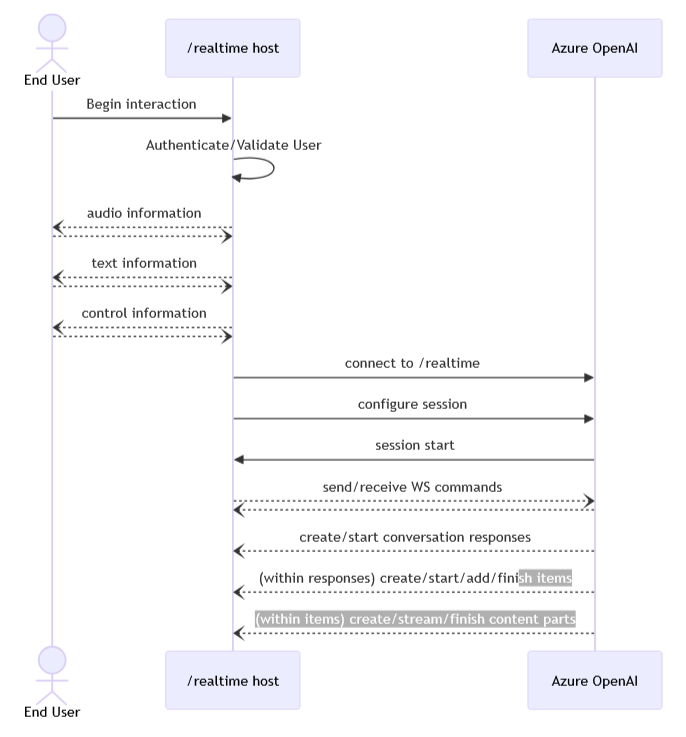
Spring 不管在 Client 或是 Server 都有套件可以處理 Websocket 內容,有機會凱文大叔再來教大家寫中間轉發 Websocket 的部分

