前一天的內容提到人工智慧中的機器學習是其核心技術之一也讓它學習如何「預測」。大家有沒有想過,人工智慧到底是怎麼做到預測未來的?不管是企業決策、投資趨勢,還是氣候變化,AI 在生活中的應用越來越多。今天,我們就來揭開 AI 預測的神秘面紗,深入了解這項技術的背後奧秘。
一、核心技術- 模型選擇(回歸 or 分類)
線性迴歸(Linear Regression):
當輸入數據和輸出之間呈線性關係的問題。(即高中數學學過的統計迴歸直線)如:預測房價與房屋面積的關係
多項式迴歸(Polynomial Regression):
當輸入數據和輸出之間是非線性的。(迴歸線為曲線)如:氣溫和季節變化之間的非線性關係
決策樹迴歸(Decision Tree Regression):
用於非線性且數據關係較複雜的問題,先將資料分類再進行預測,所以會呈現階梯狀的迴歸圖形
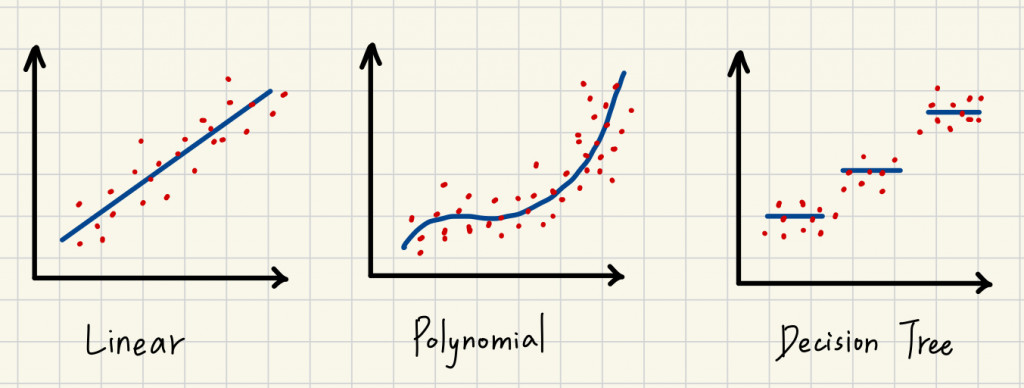
<如何選擇合適的模型>
輸入輸出關係:如果輸出是連續值,選擇迴歸模型;如果是離散的類別,則選擇分類模型。
數據特徵:如果數據是線性的,可使用線性回歸或邏輯迴歸;如果數據關係較為複雜,可以考慮使用隨機森林或神經網絡等更複雜的模型。
二、提升預測準確性:資料收集、特徵工程與模型訓練優化
資料來源:數據可以來自多種來源,如實驗結果、線上平台、傳感器或公開數據庫等,選擇可靠的來源才能保證數據的準確性。
數據清理:在實際應用中,數據往往不完整或存在噪音,因此需要進行清理。
例如:處理缺失值(填補或刪除缺失數據)、移除異常值(某些極端的數據點可能會嚴重影響模型)、標準化數據格式(如日期格式、貨幣單位一致)
資料量的重要性:擁有足夠大的數據集可以讓模型更好地學習,但更重要的是數據的「質量」,過多無用的數據可能會讓模型過擬合或變得難以處理。
特徵選擇:並不是每個特徵都對模型有幫助,如同前一天提到的非監督式學習,機器學習分類的過程中,可能造成不具重要性的特徵被過度放大以及產生無意義的分類結果。因此,特徵選擇的目的就是找出對模型預測最有幫助的那些特徵:
1.相關性分析:可以使用皮爾森相關係數等方法來分析特徵與目標變量之間的關聯度。
2.模型選擇:使用基於模型的方法來篩選特徵,如同文章前段提及的內容。
特徵創造、縮放:
我們還可以創造新的特徵或調整原本的特徵來提升模型的預測能力。
例如:將時間條件從年份轉換為星期幾或月份,可能能更好地捕捉時間對數據的影響
或者:將多個特徵之間相互作用,將特徵 A 和 B 相乘、相除,可能能捕捉到複雜的關係。
模型訓練:利用已知歷史數據學習其中的規律、反覆調整參數,提高下一次的預測準確度,如:梯度下降,使各數據點與迴歸直線的距離越來越小,即越來越精確。
模型優化:
<K折交叉驗證>
1.數據分為K個
2.每次取一個作為測試集剩下的作為訓練集
3.K次測試結果平均
三、評估分類模型表現指標:準確率、精確率、召回率
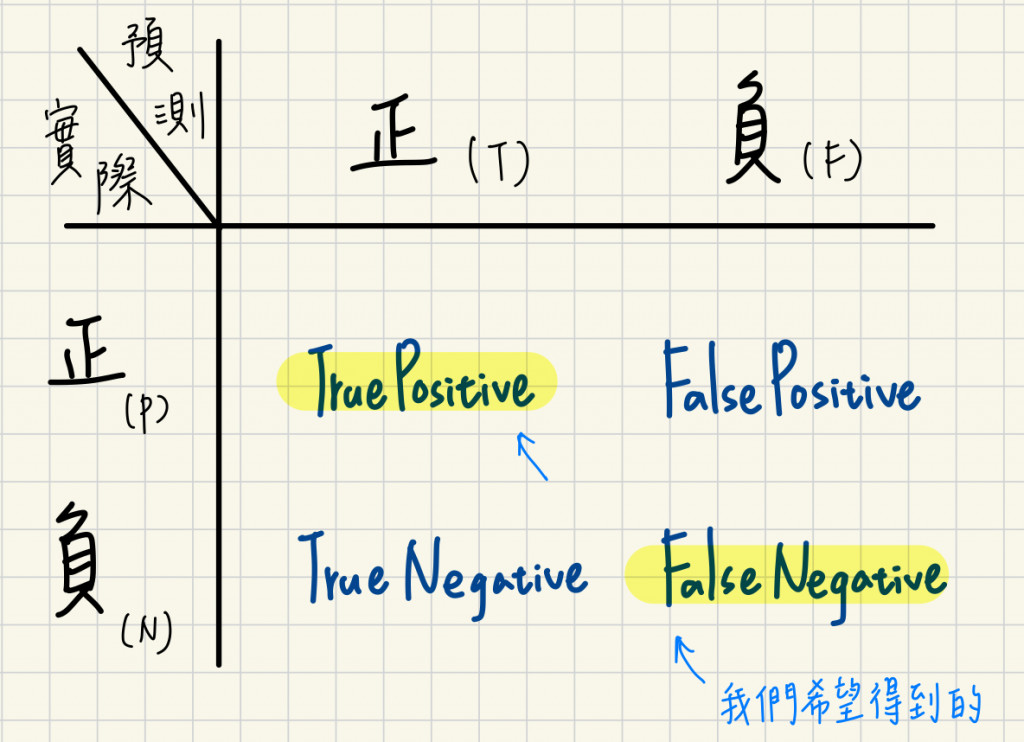
在了解評估指標之前,我們要先了解預測結果分為哪幾種:
混淆矩陣- 預測結果為正or負?實際結果為正or負?
True Positive (TP):預測為正,實際也正
True Negative (TN):預測為負,實際也負
False Positive (FP):預測為正,實際是負(誤報)
False Negative (FN):預測為負,實際是正類(漏報)
評估指標:
準確度(Accuracy)
總共答對多少 (TP+TN)/Total Sample
舉例:你做了 100 道題,結果有 90 題答對了,那你的準確度就是 90%。它代表的是你「總共」答對了多少,不管是什麼類型的題目。
精確率(Precision)
猜得有多準、不論其結果本身是對或錯 TP/(TP+FP)
舉例:想像你在挑出一堆壞蘋果,精確率就是你挑出的蘋果中,真正壞掉的有多少。如果你挑了 10 顆蘋果,其中 8 顆是壞的,剩下 2 顆其實是好的,那你的精確率就是 80%。它關心的是「你挑中的東西有多少是正確的」。
召回率(Recall)
所有「實際發生的事情」中,你能找到多少 TP/(TP+FN)
舉例:還是挑蘋果的例子,這次,你想確保你能找出所有壞掉的蘋果。假設總共有 20 顆壞蘋果,而你挑出了 15 顆,那你的召回率就是 75%。它強調的是「真正發生的事情中,你找到了多少」。
未來,隨著技術不斷進步,AI 將在各行各業的預測中發揮越來越重要的作用。了解了這些關鍵要素後,我們也能更好地掌握 AI 預測的脈絡,讓它在我們的生活中發揮更大價值。


 iThome鐵人賽
iThome鐵人賽