前篇提到了許多處理複雜規模數據集的ML模型,而這篇選擇與辨識敏感數據相關者,看看他們各自的能力:
一種監督學習模型,用於分類和回歸問題,目標是找到一條最佳的超平面(Hyperplane),以最大化不同類別之間的間隔(margin) ; SVM 特別適合於高維空間的數據,在小樣本數據也表現良好(可使用核函數(kernel function)來處理非線性分類問題)。
[ wikipedia圖示概念 ]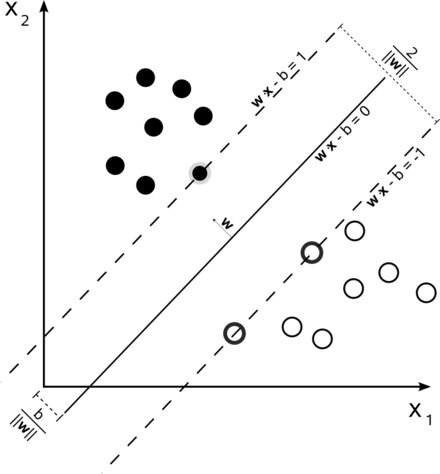
優勢:處理高維數據、分類精度高。
適用:具多個特徵的數據集,能有效區分敏感數據與非敏感數據。
隨機森林是集成學習的方法,它通過組合多個決策樹來進行分類(輸出類別是由個別樹輸出的類別眾數而定),能夠處理數據中的不平衡。
先來看一下決策樹是什麼:
決策樹(Decision Tree) 是一種常用的機器學習模型,以樹狀結構表示,對於每個節點,計算吉尼係數以評估當前節點的純度,用來評估資料的凌亂程度,而剪枝✂️(Pruning)是用來防止決策樹過擬合的一種技術,通過去除不重要的分支來簡化樹的結構。
[ wikipedia把決策樹的聚合構建為隨機森林的原理示意圖 ]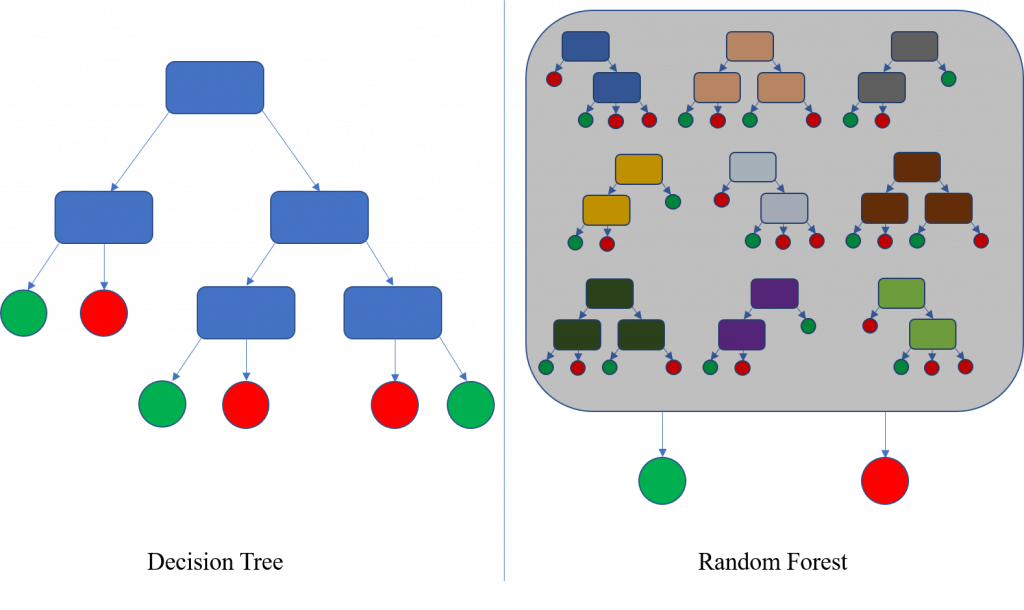
優勢:良好準確性、抗過擬合能力強。
適用:處理大規模數據集可以自動選擇重要特徵,對於敏感資料分類效果很好。
使用多層的神經網絡來學習數據中的特徵和模式,這些神經網絡通常被稱為「深度神經網絡」,它們有多個隱藏層,這些層次可以讓模型學習到數據的複雜結構。
其中選出較相關的神經網絡架構,遞迴神經網絡(RNN):
RNN 用於處理序列數據,即具有時間或順序關係的數據,通過「循環連接」允許訊息在序列的不同時間步驟之間傳遞,但他也有一個致命缺點:梯度消失(一種在訓練時因為梯度歸零而發現訓練無效的情況)。
所以研究者們提出了改進版本,長短期記憶(LSTM):
簡單看一下上述概念各自的架構(取自“Understanding LSTM Networks”):
[ The repeating module in a standard RNN contains a single layer ]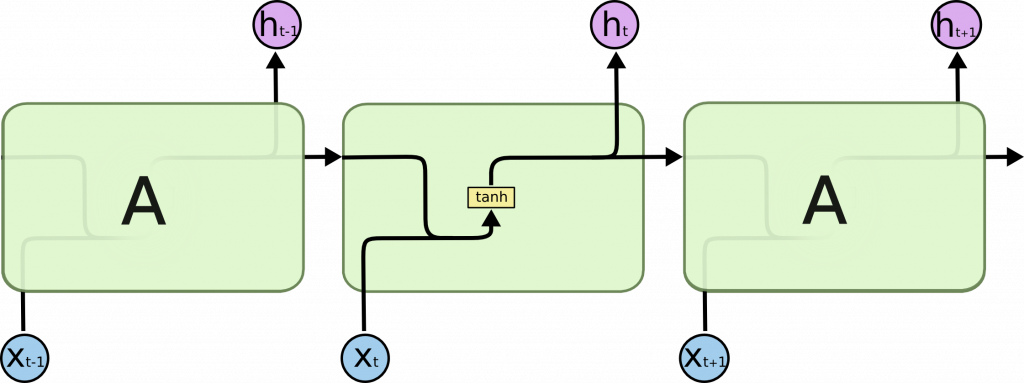
[ The repeating module in an LSTM contains four interacting layers ]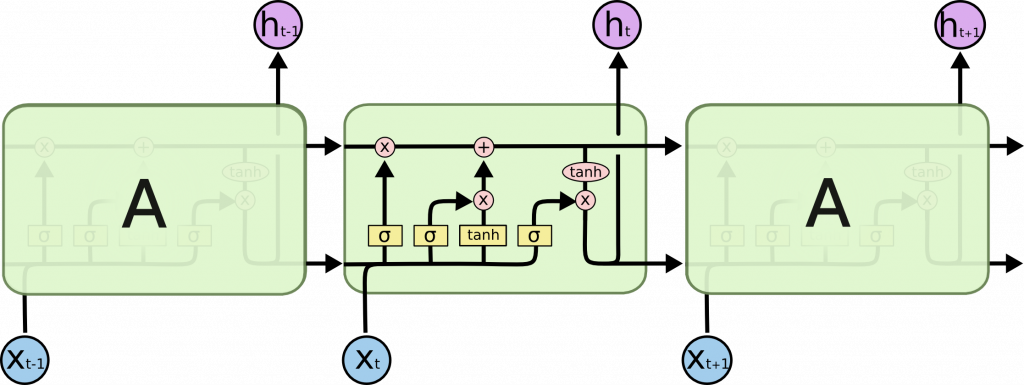
LSTM用於處理序列數據,它的主要特點是能夠記住長期依賴(long-term dependencies)關係,在處理長序列時比傳統的RNN更有效,通過使用三個門(輸入門、遺忘門和輸出門)來控制訊息流動,從而選擇性記住或遺忘訊息。
優勢:強大記憶力和靈活的門控機制,不僅能夠辨識敏感訊息,還能在數據生成和預測方面提供幫助。
適用:NLP、監控數據流,對敏感訊息的位置和具長度變化的情況特別有用。


 iThome鐵人賽
iThome鐵人賽