
大家好!我是 2魚,歡迎來到鐵人賽第九天的資料處理小教室!還記得昨天我們學會了如何使用 MongoDB Compass 手動輸入資料嗎?今天,我們要面對一個更大的挑戰:如何處理大量的專案資料。畢竟,我們的鸚鵡食堂可不是只有幾筆資料那麼簡單!別擔心,我會和大家分享一個超級實用的技巧,讓我們能夠輕鬆地整理和匯入大量資料。準備好要成為資料管理高手了嗎?Let's dive in!
昨天,我使用 Compass 手動將部分資料鍵入資料庫中,但我們專案所需的資料量更為龐大,像是鸚鵡能食用的食物、鸚鵡種類、醫療資訊等等的。為了快速彙整資料,我決定使用 AI 來幫助我整理和擴充資料量。
初步收集資料:
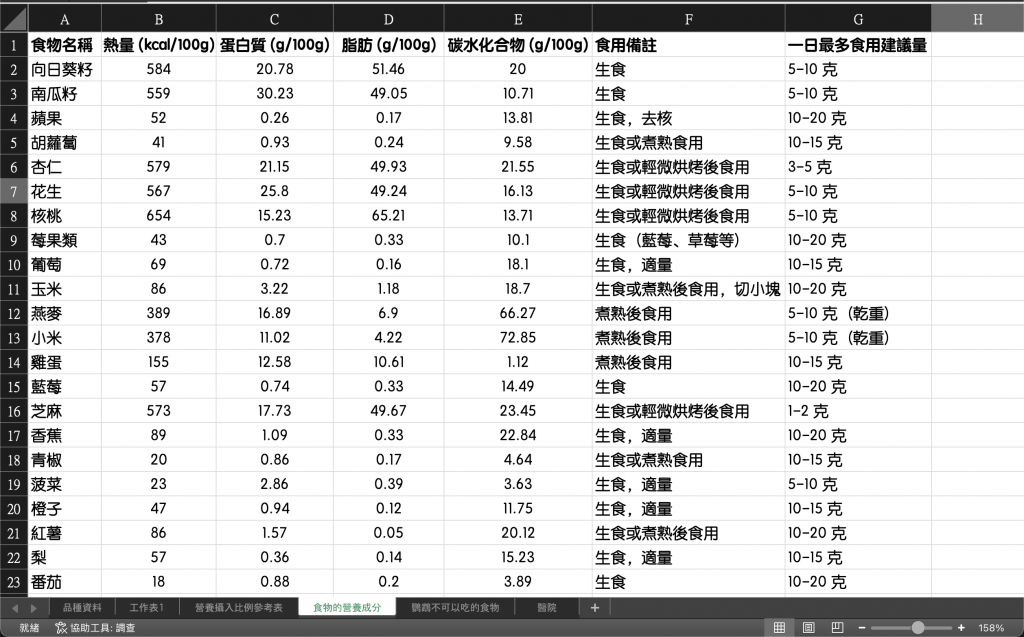
資料格式轉換:
收集到足夠的資料後,我會將這些資料複製並請 AI 幫忙將其整理成 JSON 格式,這樣就能方便地匯入 MongoDB 中使用。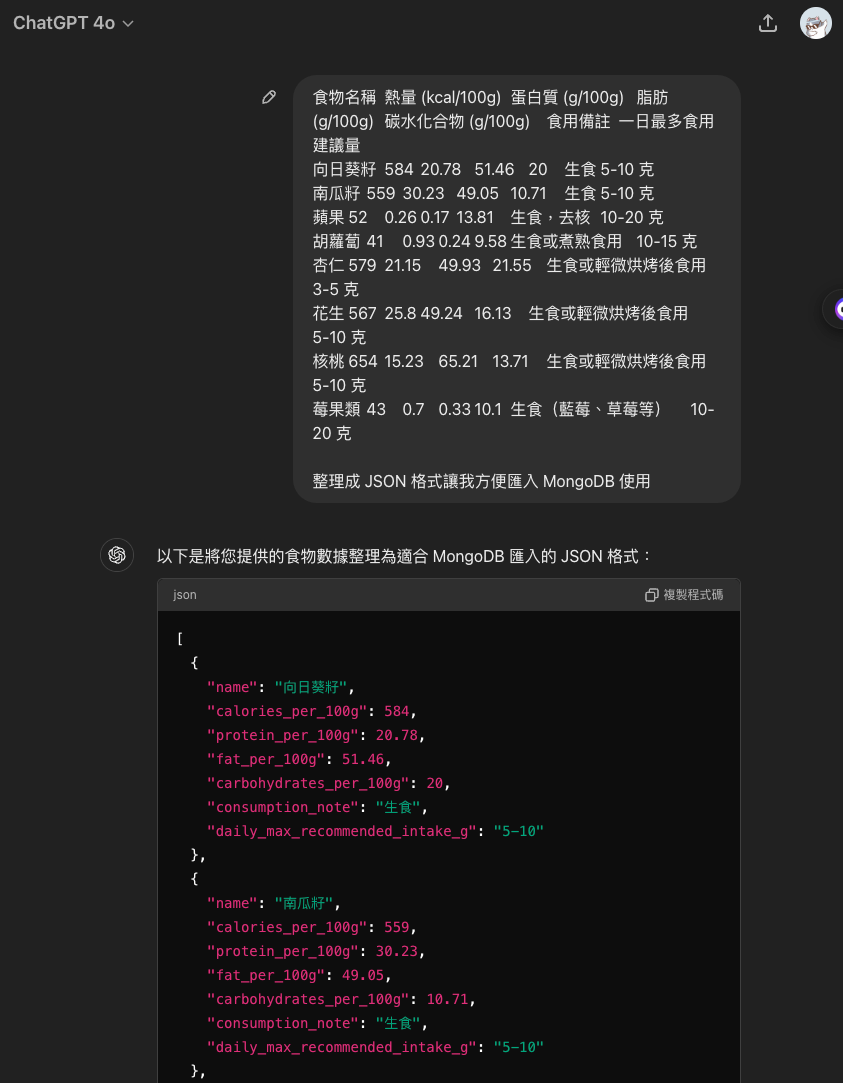
在 VS Code 中存檔:
我會打開 VS Code,按下快捷鍵 cmd + N 新增一個文字檔案。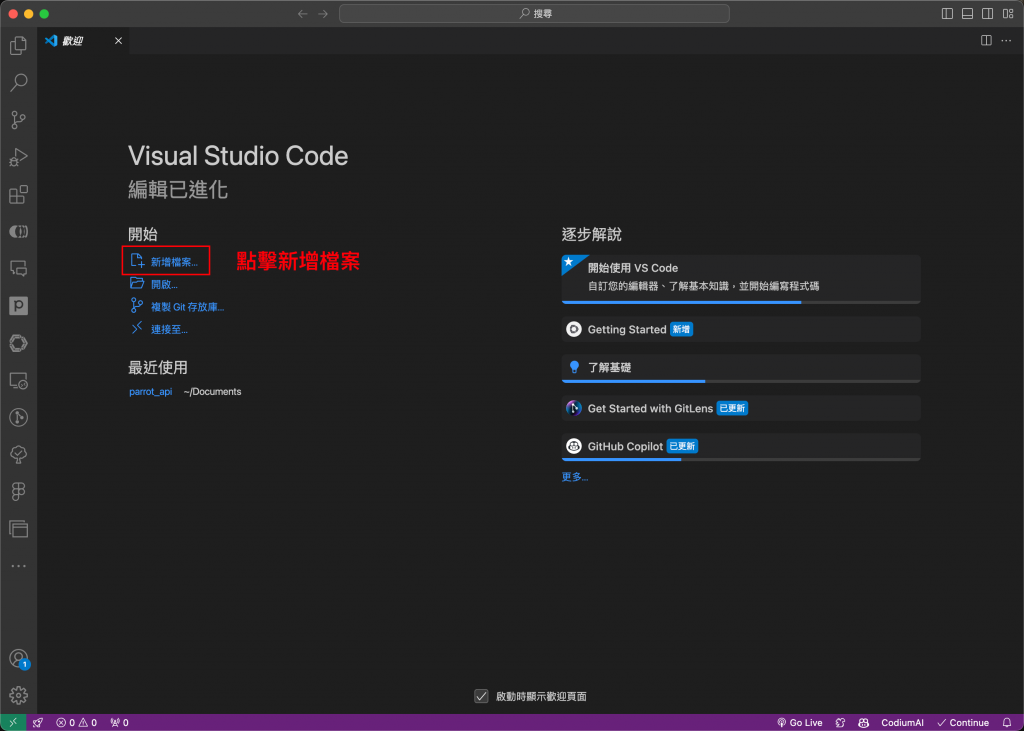

接著,將整理好的 JSON 資料貼上到這個檔案中。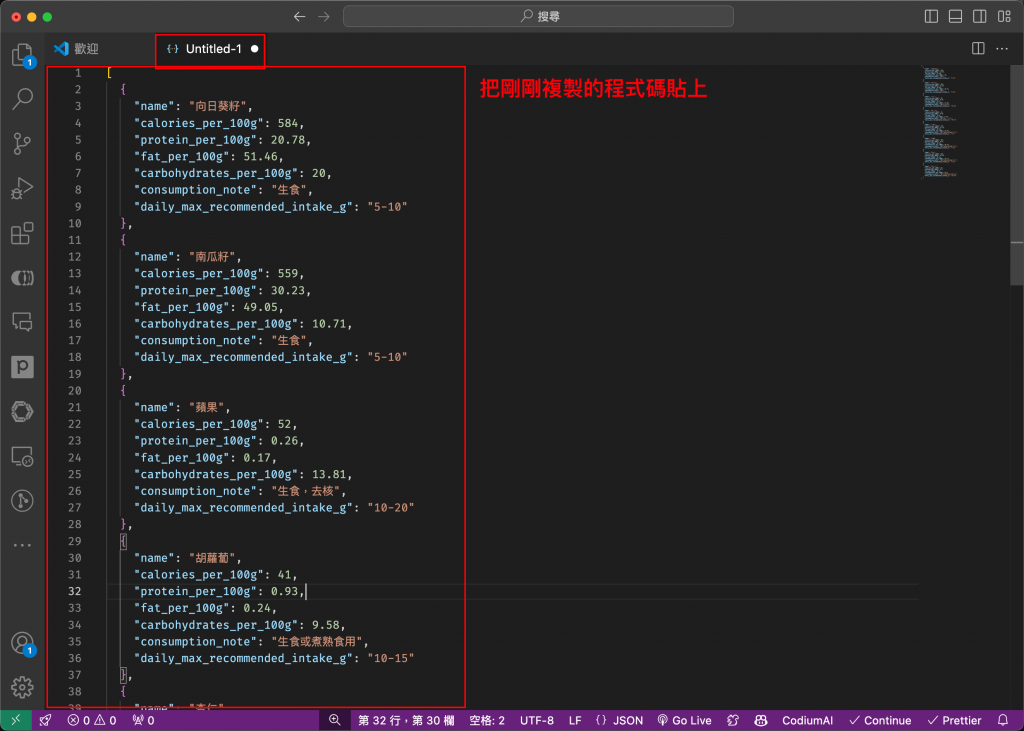
最後,將這個檔案保存到一個我可以輕鬆找到的位置。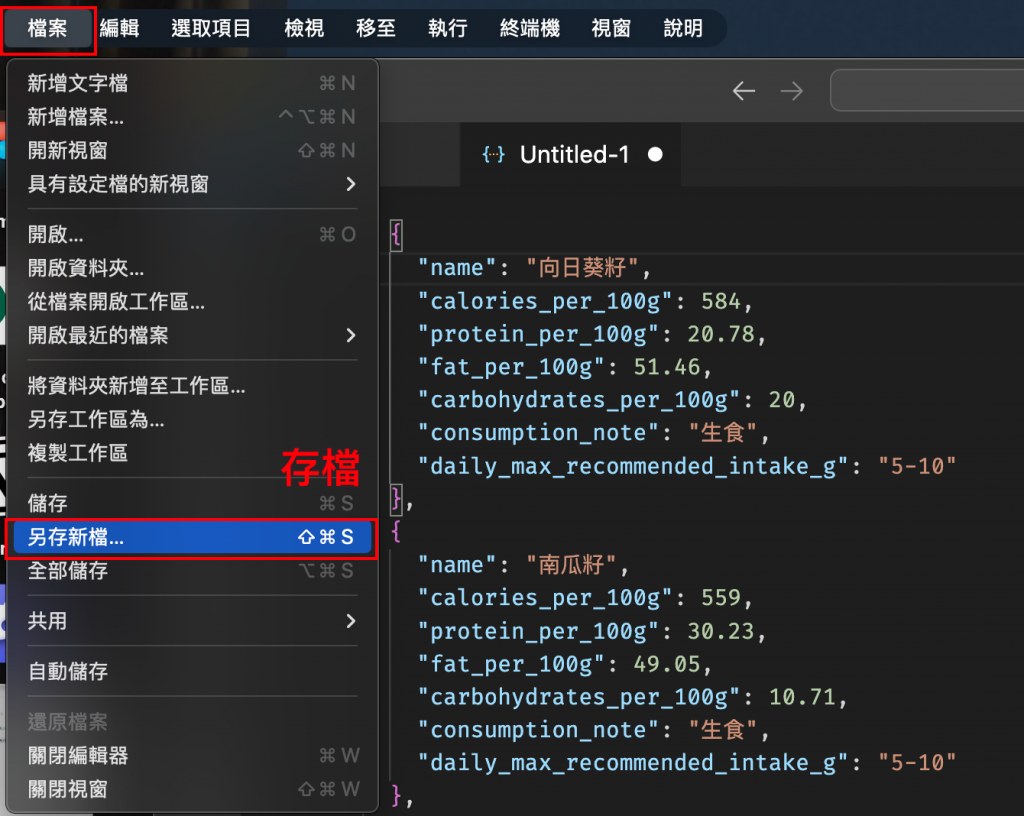
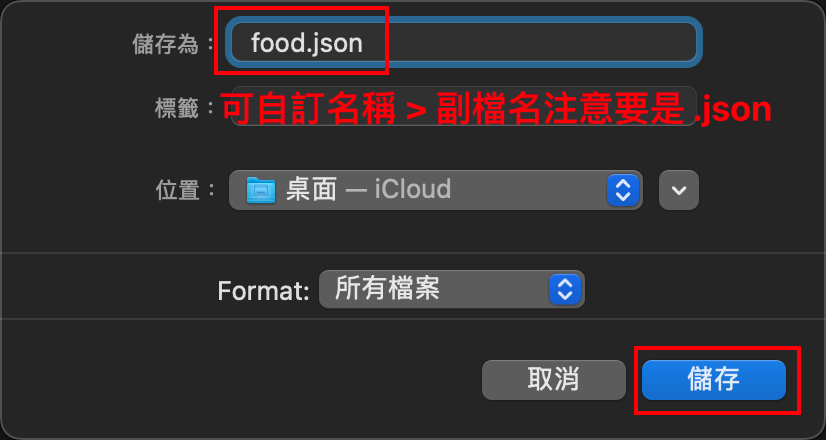
匯入資料到 MongoDB:
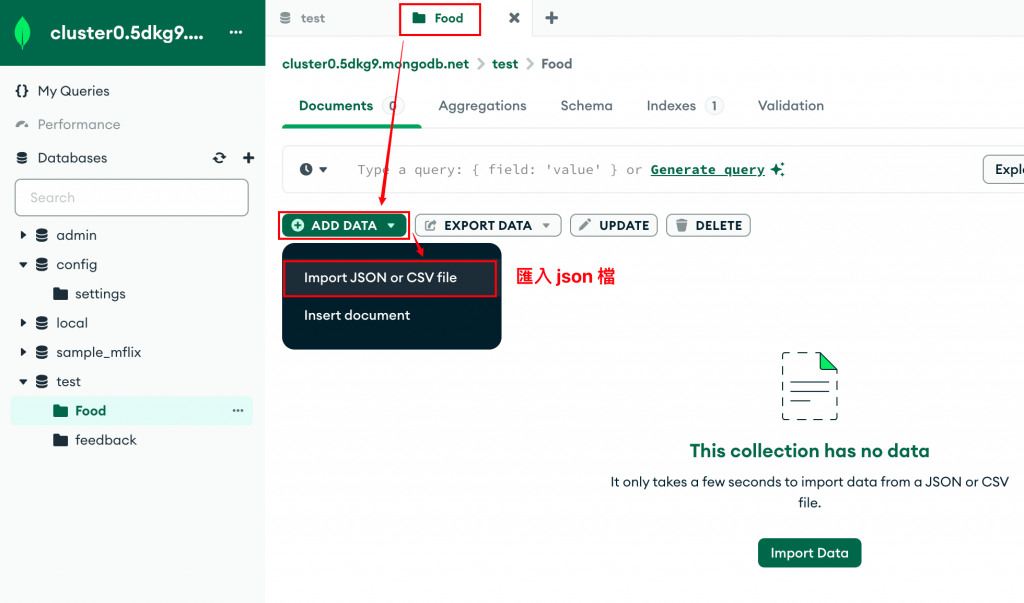
在打開 Compass 之後,我會使用匯入功能將剛剛的 JSON 檔案匯入資料庫。這次我選擇匯入鸚鵡能食用的食物資料,因此我會先在資料庫中新增一個集合(collection)。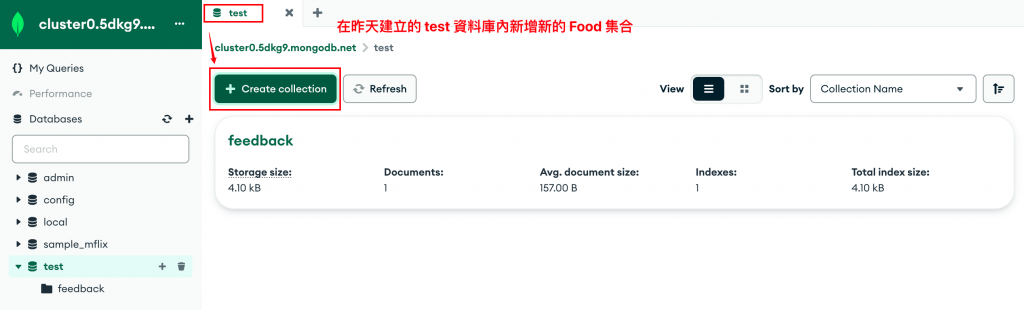
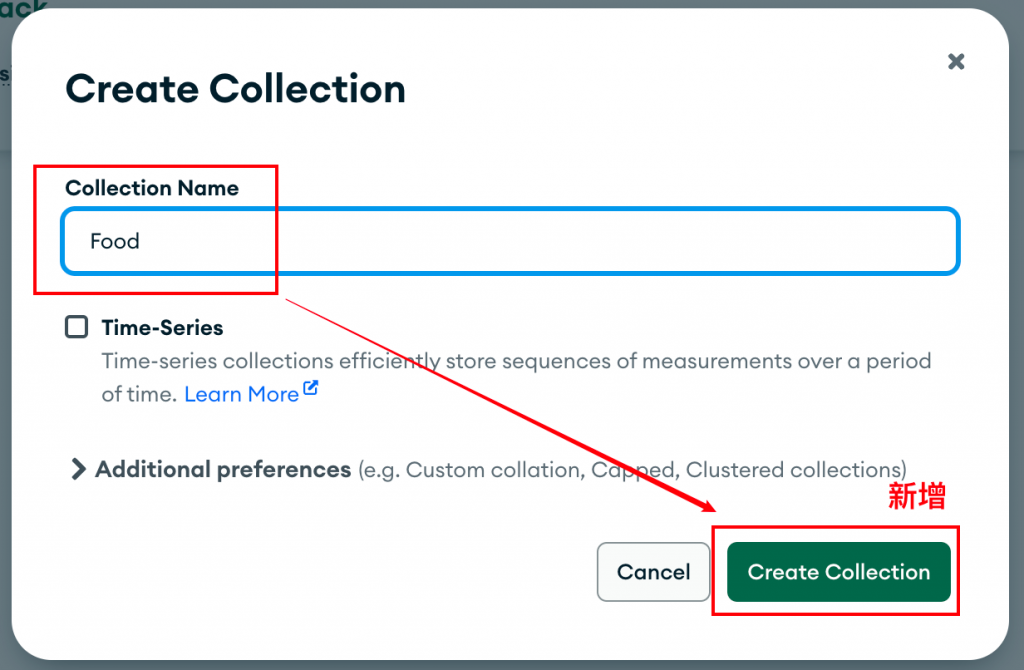
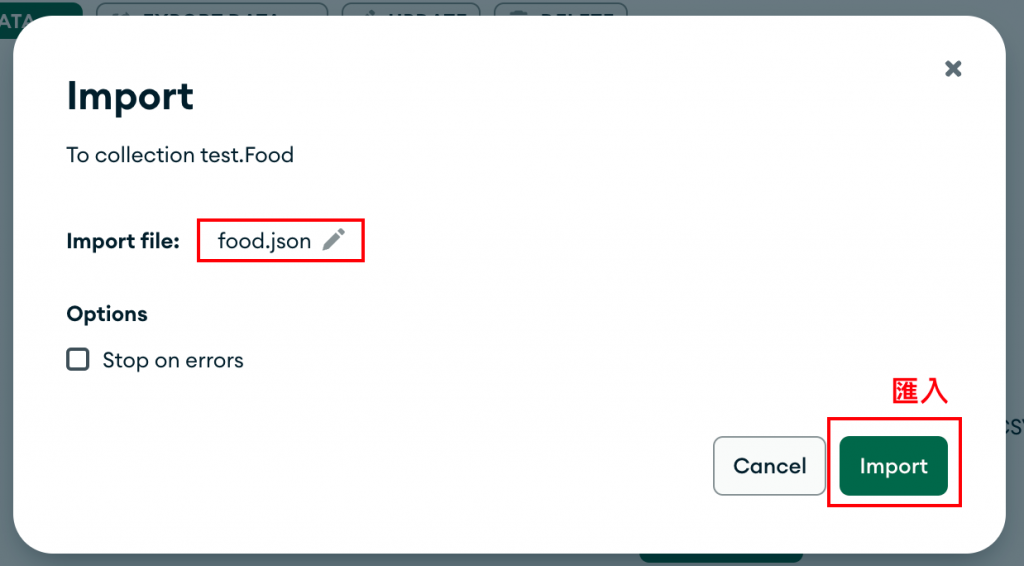
然後,我會將剛才保存的 JSON 檔案匯入到這個新的集合中。
這裡提供了一些範例的資料,大家可以將資料存到 food.json 文件,跟著一起動手試試看:
[
{
"name": "向日葵籽",
"calories_per_100g": 584,
"protein_per_100g": 20.78,
"fat_per_100g": 51.46,
"carbohydrates_per_100g": 20,
"consumption_note": "生食",
"daily_max_recommended_intake_g": "5-10"
},
{
"name": "南瓜籽",
"calories_per_100g": 559,
"protein_per_100g": 30.23,
"fat_per_100g": 49.05,
"carbohydrates_per_100g": 10.71,
"consumption_note": "生食",
"daily_max_recommended_intake_g": "5-10"
},
{
"name": "蘋果",
"calories_per_100g": 52,
"protein_per_100g": 0.26,
"fat_per_100g": 0.17,
"carbohydrates_per_100g": 13.81,
"consumption_note": "生食,去核",
"daily_max_recommended_intake_g": "10-20"
},
{
"name": "胡蘿蔔",
"calories_per_100g": 41,
"protein_per_100g": 0.93,
"fat_per_100g": 0.24,
"carbohydrates_per_100g": 9.58,
"consumption_note": "生食或煮熟食用",
"daily_max_recommended_intake_g": "10-15"
},
{
"name": "杏仁",
"calories_per_100g": 579,
"protein_per_100g": 21.15,
"fat_per_100g": 49.93,
"carbohydrates_per_100g": 21.55,
"consumption_note": "生食或輕微烘烤後食用",
"daily_max_recommended_intake_g": "3-5"
},
{
"name": "花生",
"calories_per_100g": 567,
"protein_per_100g": 25.8,
"fat_per_100g": 49.24,
"carbohydrates_per_100g": 16.13,
"consumption_note": "生食或輕微烘烤後食用",
"daily_max_recommended_intake_g": "5-10"
},
{
"name": "核桃",
"calories_per_100g": 654,
"protein_per_100g": 15.23,
"fat_per_100g": 65.21,
"carbohydrates_per_100g": 13.71,
"consumption_note": "生食或輕微烘烤後食用",
"daily_max_recommended_intake_g": "5-10"
},
{
"name": "莓果類",
"calories_per_100g": 43,
"protein_per_100g": 0.7,
"fat_per_100g": 0.33,
"carbohydrates_per_100g": 10.1,
"consumption_note": "生食(藍莓、草莓等)",
"daily_max_recommended_intake_g": "10-20"
}
]
成功匯入資料後,資料庫就會顯示這些資料,方便進行後續操作。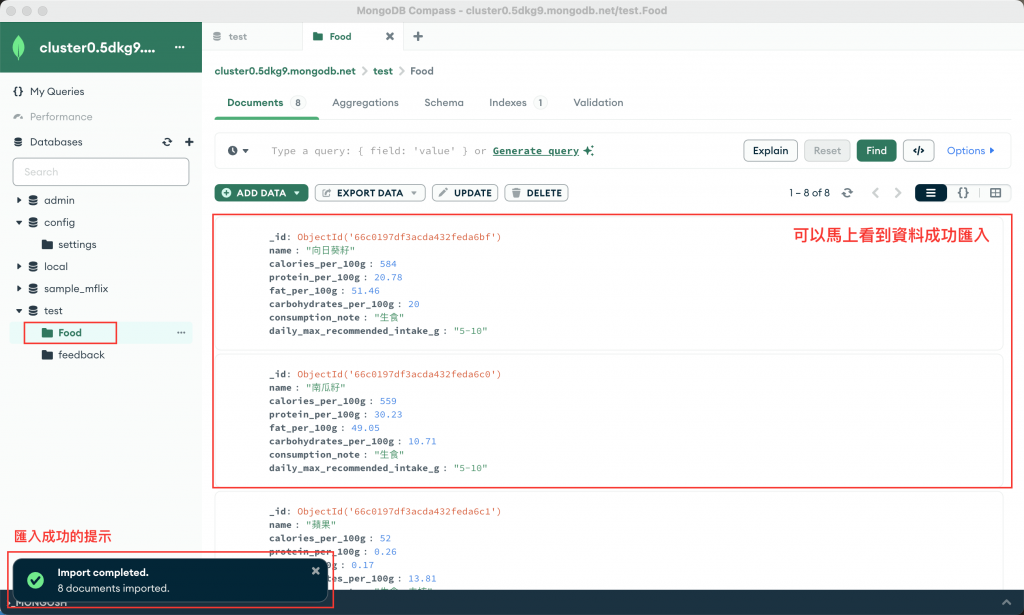
哇,今天我們學到了一個超級實用的技巧呢!透過結合 AI 的強大處理能力和我們對資料的精細把控,我們不僅能快速擴充資料量,還能保持資料的一致性與準確性。這個方法真的是處理大量資料時的救星啊!
想想看,這個流程不只適用於我們的鸚鵡食堂專案,在未來處理任何需要大量資料的專案時都能派上用場。無論是開發過程中的資料蒐集,還是後續的數據處理與分析,這個方法都能讓我們事半功倍。
如果你正在進行類似的專案,或是正為龐大的資料整理而煩惱,真的很推薦你試試看這個流程。相信我,它會讓你的工作變得更加輕鬆高效!
大家有沒有自己處理大量資料的秘訣呢?歡迎在下方留言分享喔!我們一起學習、一起成長。明天見啦,掰掰~
(對了,如果你覺得今天的內容對你有幫助,別忘了給個讚支持一下喔!這會是我繼續努力的動力呢~)
