在今天的學習中,我將學習爬蟲的詳細工作流程,並試著以自己的方式理解並做出新的概念陳述。
以下是今天要學習的小章節:
以上是本日要學習的幾個小章節,那就馬上開始今天的學習了!
HTTP請求機制
我們在前一天的內容中其實就有大概講過HTTP的概念了,這邊就再稍微簡單的提一下。
簡單來說,HTTP就是一種用來在客戶端和服務器之間進行數據通訊的協議;
而HTTP請求/響應機制,就是前面所提到的,當用戶端發出請求後,
伺服器端會做出接收的動作,並針對你的要求做出回應,
也就是上述所說的「響應機制」。
(響應機制會在第三個小節詳細敘述)
而在舉實際的範例之前,我想先行跳到下一個章節,先學習POST與GET的差異,
讓我在學習請求實例時可以更好的作出解釋。
GET與POST請求:
在詳細解讀實際的程式碼之前,我想必須先熟悉在請求中
最常見的兩個語法: GET跟POST。
這兩個語法雖然都是由請求端發出,但所想獲得的目標和用途並不完全相同,
所以這邊我想著重在這兩個語法的差異來做講解:
GET:
GET主要是用來從伺服器「獲取數據」。
它的特點是它會將所有的請求參數(數據)附加在 URL 上,
並且不會修改伺服器上的資源。
而由於數據請求是直接附在URL上的,所以並不會有很好的隱私性,
換句話說,GET並不適合做為傳輸機密資料的方式。
而也因為不適合傳輸機密訊息,GET通常就只是用來獲取伺服器端的訊息,
並不會將自己的資料丟出,也因此不會對伺服器端做出修改。
*URL:
簡單來說,你可以把它想成你的目標「地址」,而在網路上,
這個東西我們稱作「網址」。
POST:
而相較於GET,POST的目的性就有所不同了。
它的主要用途是為向伺服器端「提交數據」,
且該舉動會更改接收端的數據。
先講講最不同的地方,相較於GET,POST則會將自己的請求放在請求的主體中,
而非放在URL後。
白話文一點來說,它會將自己的請求包在裡面。
因此,其相較於GET有著更好的安全性,也比較適合用來向伺服器端提交資料。
那GET適合用來做什麼用途呢?由於它具備更高的安全性,
所以常會用來作為像是填寫表單、上傳文件的主要語法。
以下我也整理了一個表格,讓大家可以更好的了解其差異:
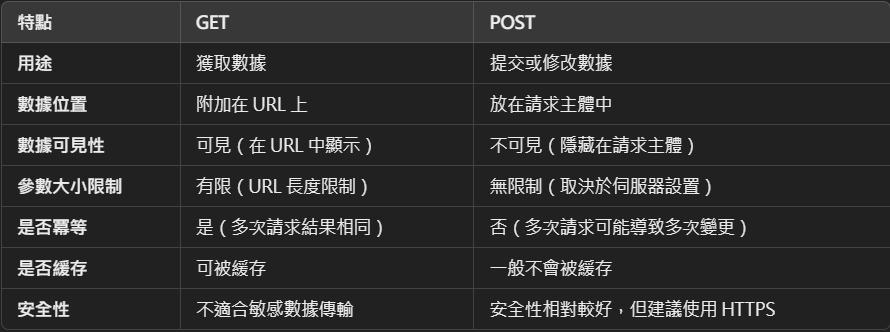
(此處只是講述概念,並不對所有差異作深入探討)
而在了解完GET和POST的差異後,我們就可以來看看實際的簡單例子:

上面這個是GET的範例。在以下,我會以分行的方式來作解釋:
GET /page.html HTTP/1.1:
在此處使用GET的方式想獲取一個
名為page.html的網頁文件(同時也是URL路徑)。
而後方的HTTP/1.1,則是HTTP協議的版本。
Host: example.com:
指定請求目標的主機名,這裡表示請求的網站是 example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124 Safari/537.36:
告訴伺服器請求來自哪種瀏覽器或應用程式。這裡顯示的是一個
常見的 User-Agent 的字符串,
表明使用的瀏覽器是 Chrome,運行於 Windows 系統上。
Accept: text/html:
表示客戶端希望接收 text/html 類型的數據,也就是 HTML 網頁。
(要記得,上述的訊息都是由客戶端輸出,並非伺服器端)
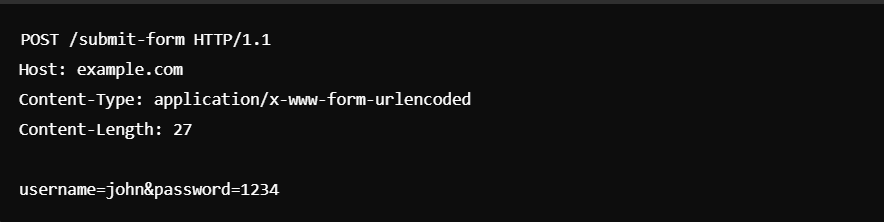
而上面這個程式碼則是POST的請求範例,
上方POST的目的是向伺服器端發送表單,
讓資料可以存儲在伺服器端。
而跟GET不同的是,它不會將查詢參數寫在URL後,
以此避免暴露隱私資料。
Content-Type: application/x-www-form-urlencoded:
這裡顯示的代表數據被編碼為鍵值對的形式,並且各對之間使用** &** 符號分隔,
鍵和值之間用** = **連接。這種格式是網頁表單提交數據時常用的格式。
像是下方的 username=john&password=1234
就表示兩個參數:username 的值是 john; 而password 的值是 1234。
*鍵值對: 簡單來說,在這裡用戶名跟密碼就是鍵,而輸入的東西就是值。
HTTP 響應:
在講完請求的部分,我們還是要聊一下伺服器回傳的部分,也就是「響應」。
以下是伺服器端響應的範例:
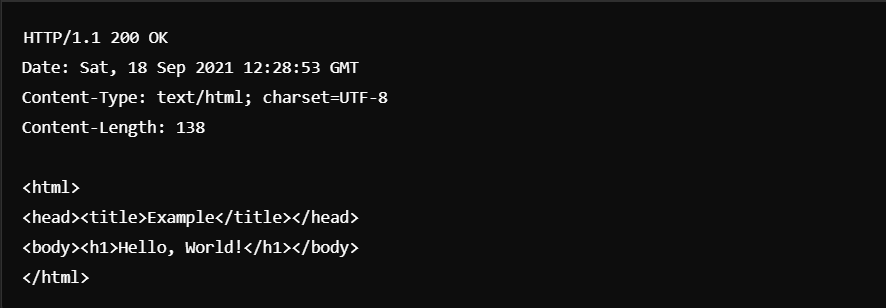
在上述的資料中,我挑幾個我一開始看不太懂的地方做講解:
200 OK: 這裡指的是HTTP的狀態碼,意思是指請求成功。常見的狀態碼還有:
302 Found:資源暫時移動到新的位置,客戶端應該使用新的 URL。
400 Bad Request:請求無效,伺服器無法理解請求。
401 Unauthorized:請求需要驗證,客戶端未提供有效的驗證憑證。
403 Forbidden:伺服器拒絕請求,客戶端無權訪問資源。
404 Not Found:請求的資源不存在。
500 Internal Server Error:伺服器內部錯誤,無法處理請求。 以上
charset=UTF-8:
UTF-8是這個HTML網頁的字符集編碼 (也是全球資訊網的最主要的編碼形式),
簡單來說,就是一種編碼形式而已,不要想得太複雜。
小結:
在今天其實原本要介紹五個小章節的,沒想到做完三個字數就爆了…,也沒辦法,
只能把其他的移到其他天了。好了講回來今天的進度,今天我重新深入學習了一次
HTTP請求以及響應的概念,其實這些東西在大一的時候就又接觸過了,
只是剛好再透過這次的機會,幫我找回以前的記憶,
現在我對於整體的概念又更熟悉了一點。
參考資料:
https://zh.wikipedia.org/zh-tw/UTF-8
https://zh.wikipedia.org/zh-tw/HTTP%E7%8A%B6%E6%80%81%E7%A0%81
https://www.cadiis.com.tw/blog/what-is-url
https://www.runoob.com/http/http-messages.html
http://support.supermap.com.cn/DataWarehouse/WebDocHelp/iServer/mergedProjects/SuperMapiServerRESTAPI/clientBuildREST/HTTP_structure.htm

