意思是不知道可能沒關係,但查了就順便寫(?
上一篇在測試 kubectl.kubernetes.io/last-applied-configuration 標籤和 apply 指令的時候,本來是打算做個 Demo 演示 last-applied-configuration 的行為,但卻發現比想像中來得不容易...
原先以為他是一個聰明的防呆機制,像這樣:
kubectl apply 指令做更新本來的猜想:replicas 還是等於 3,超級讚!!!
實際上:replicas=1
... (´・_・`)
但是我沒有死心!
打算再試試其他情境:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx-app
template:
metadata:
labels:
app: nginx-app
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
env:
- name: DB_NAME
value: db.name
kubectl apply 指令做更新本來的猜想:env 會是原本的 DB_NAME + 新設定
實際上:DB_NAME 消失,只剩下新設定的變數
好啊都這樣啊都不要試啊 (;´༎ຶД༎ຶ`)
這時候我冒出了大大的問號:
kubectl apply 到底是怎麼工作的?!在前一篇稍微提到,kubectl apply 的管轄範疇只包含 last-applied-configurationannotation 中有值的參數,但是 replicas 並不在其中,那它歸誰管?
從官方文件找到了答案:Horizontal Pod Autoscaling
Pod 的水平擴展由 HorizontalPodAutoscaler 負責管理。
HorizontalPodAutoscaler 是以 Kubernetes API + controller 實作出來,運行在 Control Plane 上的機制。它會基於監控到的各種指標,如:CPU使用率、記憶體使用率,或其他自定義指標。根據 CPU 使用量、Memory 使用量或其他自行定義的指標,去調整服務規模。
喔... 所以資源擴縮還真的不歸kubectl apply管...
apply 的意思是:我只關心我管理的內容要跟文件配置一致(但其他的我不管)
也就容易造成 yaml 檔設定不完全時,執行結果不如預期的狀況。
kubectl apply 到底在幹嘛?在 Kubernetes 中,kubectl apply 其實有兩種配置邏輯:
Server-Side Apply 和 Client-Side Apply
kubectl apply 預設的運作方式。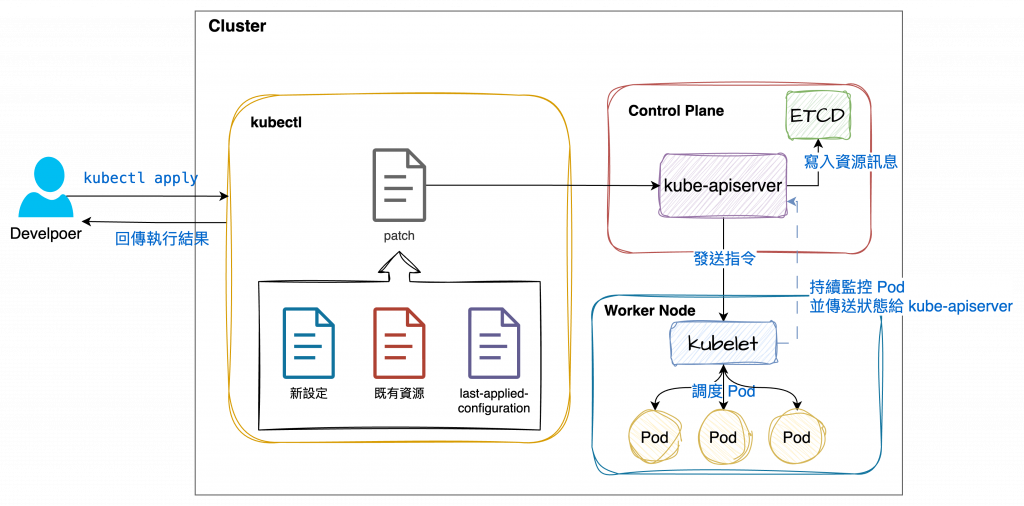
kubectl 會先讀取 Kubernetes Cluster 中的現有資源狀態last-applied-configuration 的內容)進行比較,生成一個patch
patch 發送給 Kubernetes API Server (kube-apiserver)進行資源更新使用 patch 的情況下,會執行合併
在這個情況下,是針對已經存在的Deployment 做 apply,卻又沒有設定 replicas 的時候,的確是會保留原先設定的。
詳細示例可以參考官方文件:Declarative Management of Kubernetes Objects Using Configuration Files
基本邏輯大概是這樣:
last-applied-configuration 不存在於配置文件中,做刪除last-applied-configuration者,不做異動官方文件:Server-Side Apply
功能和 Client-Side Apply 基本上相同,但 Server-Side Apply 是宣告式配置,從 Kubernetes v1.16 開始成為 stable功能。
顧名思義,Server-Side Apply 是把合併邏輯從 client 轉移到 server 端,它會追蹤所有欄位設定的管理元件(也就是它知道所有設定是由哪些資源或 Controller 控制)。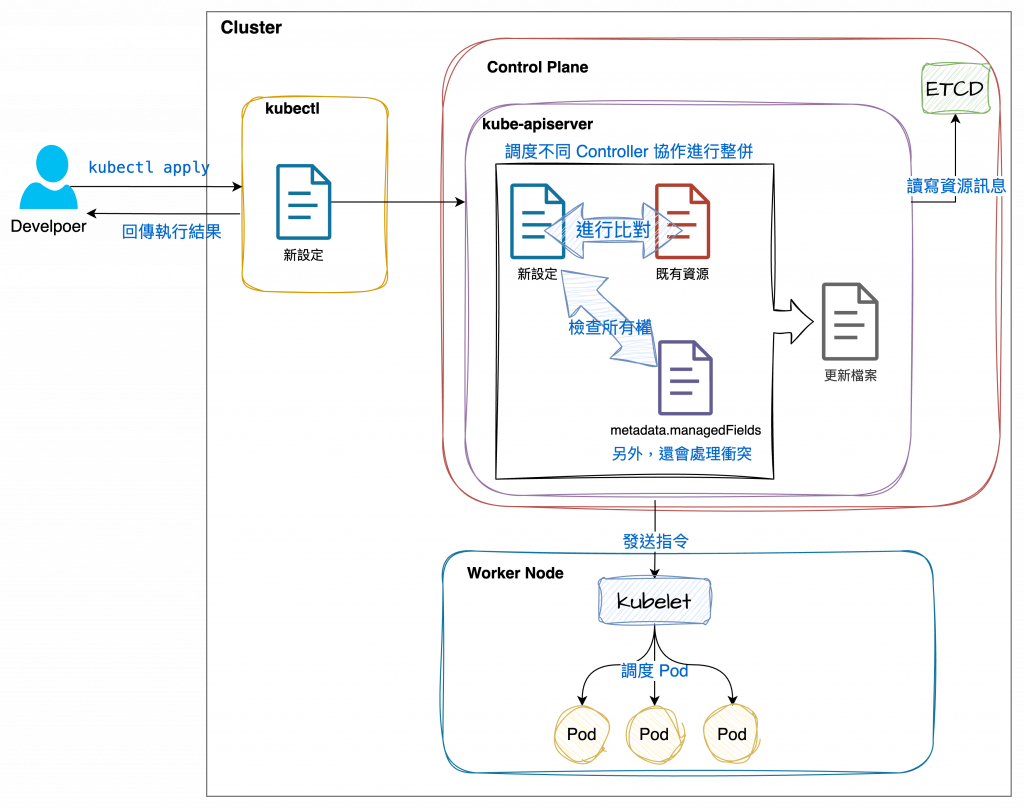
與 Client-Side Apply 不同,Server-Side Apply 不是將資訊儲存在 last-applied-configuration,而是 metadata.managedFields。
可參閱相關文件:object-meta
metadata:
creationTimestamp: "2022-12-04T07:59:24Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
f:a: {}
f:b: {}
manager: kubectl
operation: Apply
time: "2022-12-04T07:59:24Z"
而相較於 Client-Side Apply,它可以做到更精確的更新:它只更新實際變化的欄位,而不是整個元件,還加強了權限的控管和追溯機制,降低了錯誤覆蓋設定的可能性,可以理解成強化版的 Client-Side Apply。
如果要使用 Server-Side Apply 做更新,使用這個指令:
kubectl apply --server-side -f <yaml file>
Client-Side Apply 的合併規則合是基於 Kubernetes 的 strategic merge patch,不同的設定類型都分别有各自不同的合併策略,規則也十分複雜(比較容易產生衝突或 bug)。
Server-Side Apply 則改善了這個問題,它定義了更準確的權限規範和合併規則,讓不同 Controller 協作時不容易發生衝突,處理的顆粒度也更細。

