這次要介紹的是昨天在最後賣關子的 XPATH定位功能。
昨天提到不用複製貼上的方法主要是因為它複製的是絕對路徑,只要前面的節點結構有動到就不能用了。
而第二種方法就是用相對路徑來尋找元素,等等會先實作幾個例子,再講解 XPATH 的寫法。
以iT邦幫忙頁面為例,如果要找"技術問答"這個按鈕有幾種方式

可以用class名稱找
//a[@class = 'menu__item-link menu__item-link--pl']
要確認有沒有定位到元素,只要在網頁開發工具下 ctrl+f,用下面的搜尋欄尋找即可。
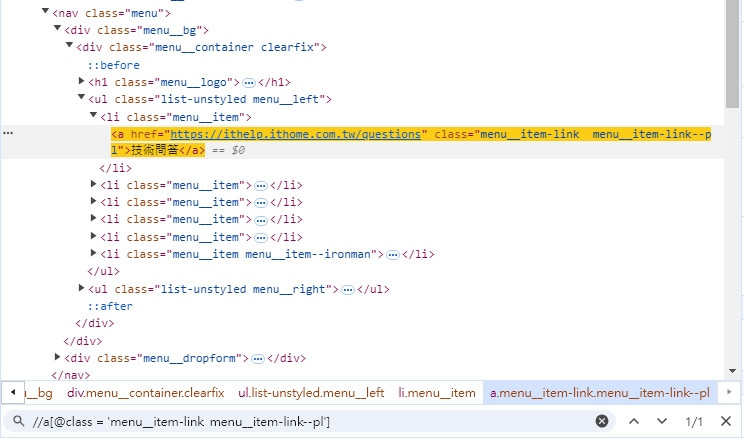
右下方顯示1/1,代表定位成功
不過這個 class的名稱有點太長,若是在確認不會跟其他 class 重複的情況下,可以只抓部分的文字名稱,具體方法如下:
//a[contains(@class, 'menu__item-link--pl')]
以這個元素為例,同樣也可以用文字的方式來抓這個 element。這個時候就會用到text(),它比較特殊的部分是它不是屬性所以前面不用加'@'
//a[text()='技術問答']
上文中提到的 contains 在 text 裡也可以使用,以"聊天室"為例
//a[contains(text(), '聊天')]
以剛剛提到的 contains 在 text 的運用,尋找"iT 徵才"
//a[contains(text(), '徵才')]
會發現找到3個元素,而我們只想找到 iT 徵才這個元素,這個時候就可以用 and。
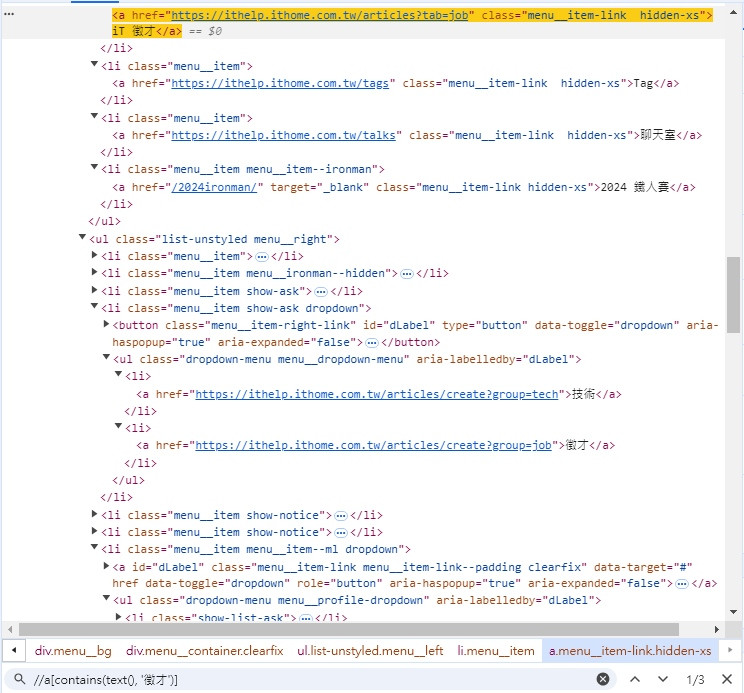
觀察這三個元素
<a href="https://ithelp.ithome.com.tw/articles?tab=job" class="menu__item-link hidden-xs">iT 徵才</a>
上面這個是目標元素,下面兩個是我們要排除的
<a href="https://ithelp.ithome.com.tw/articles/create?group=job">徵才</a>
<a href="https://ithelp.ithome.com.tw/articles/create?group=job">徵才</a>
可以發現其他兩個元素只有連結跟文字而已,這個時候我們就可以使用 and ,把 class的條件一併包進來。
//a[contains(text(), '徵才') and contains(@class, 'hidden-xs')]
可以看到成功定位出我們要的元素。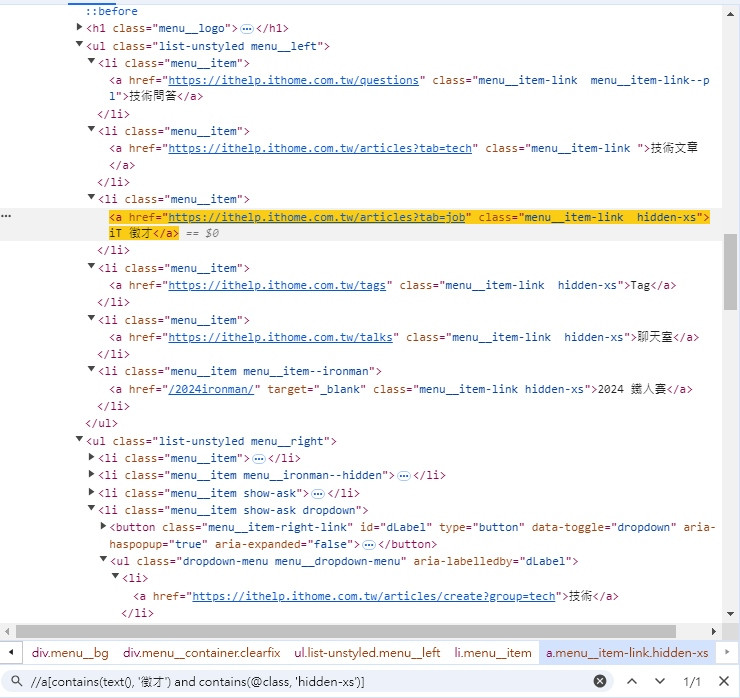
現在以技術問答的文章為例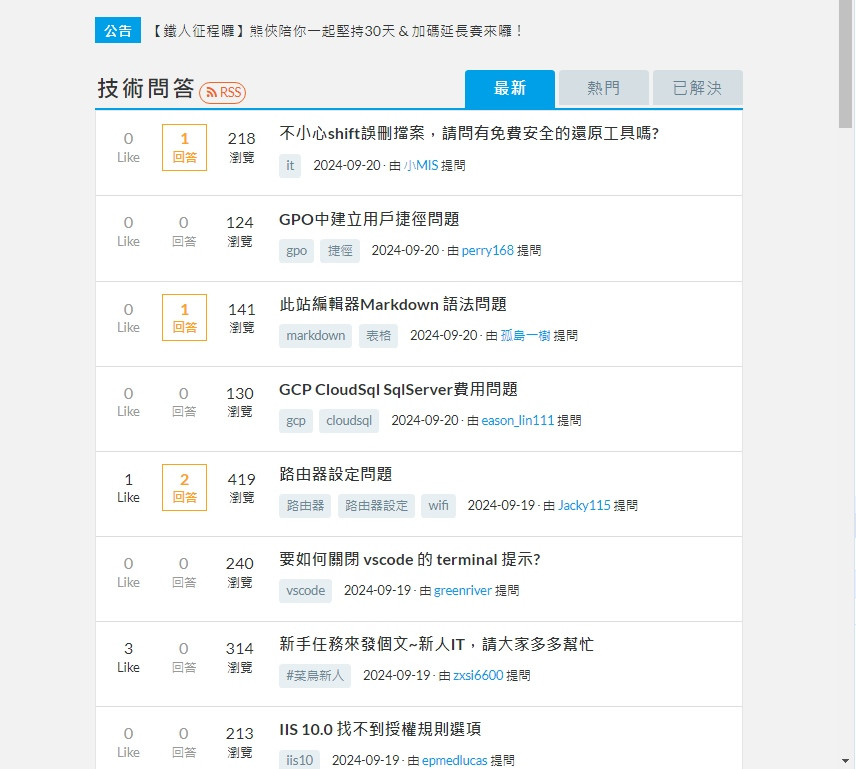
如果要選擇第一個文章,或是要選擇特定的文章,就可以用 index 的方式定位。
透過網頁開發工具,可以觀察到每一篇文章的元素都一樣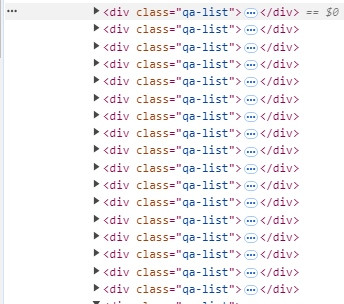
以class定位,可以把所有文章都定位到。
//div[@class='qa-list']
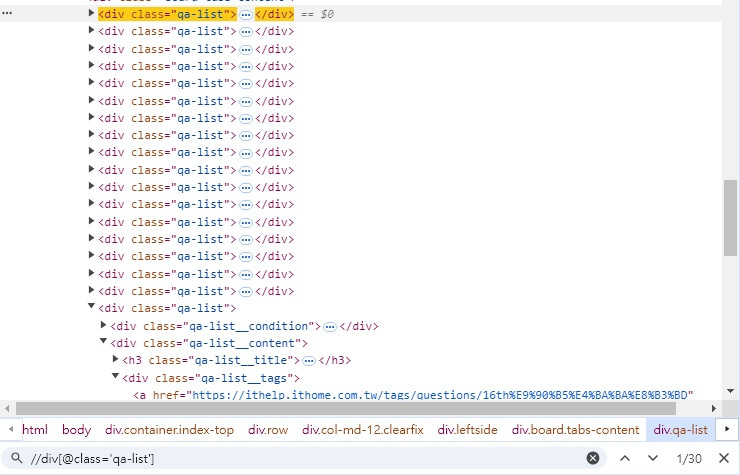
如果要定位到第一個文章,可以用以下的作法
(//div[@class='qa-list'])[1]
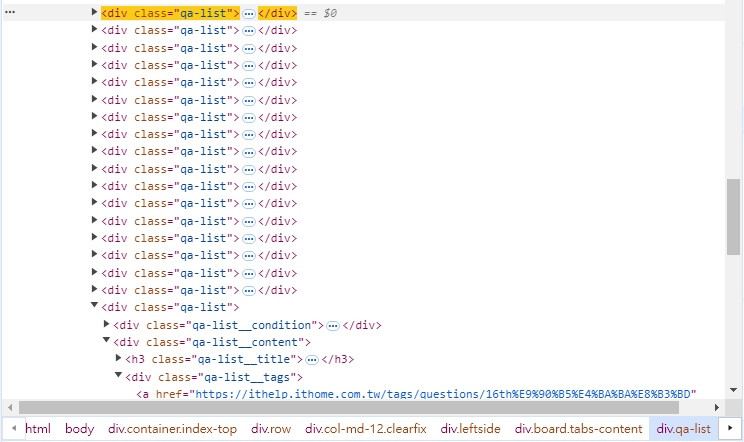
如果要定位的是第十個文章
(//div[@class='qa-list'])[10]
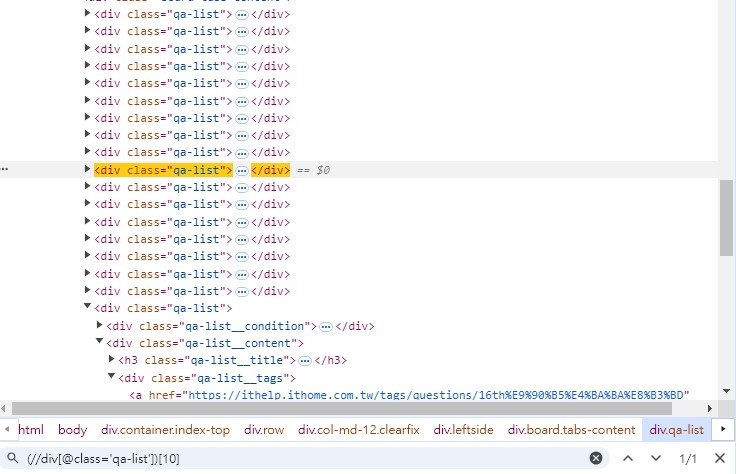
這邊要注意的是 index 的頭是由1開始,跟前幾天提到的 for 迴圈或其他程式語言的 index 從0開始不一樣。
從上面幾個例子可以看出, XPATH 基本上是由標籤名稱與標籤內的屬性和屬性的值來尋找,通常以目標元素那一層的標籤開始定位,整體寫法可以整理成如下:
//標籤名稱[@屬性='屬性的值']
今天提到了基本的 XPATH 定位方法,其實還有更進階的查找方法,後面如果會遇到再另行補充。
明天預計會介紹Selenium的各個網頁的基本操作(點擊、輸入等)。

