我們在 Day 11 介紹過 Spotify 的資料延遲問題,以及他們是如何處理的。身為他們的媒體串流平台好朋友的 Netflix 也同樣遇到這個問題,不過他們舊有的處理方式跟新的改善方法都跟 Spotify 不同,所以我們也來看看這個影音串流龍頭是怎麼做的吧!
Netflix 的各項服務都仰賴他們的資料處理 pipelines,這些 pipeline 需要運行的頻率各有所異,從每個小時執行、一天運行幾次,一直到每天執行都有可能。在進行資料處理時,Netflix 會希望每次都是完整的資料,因此會延遲幾個小時,等待可能比較晚到的資料,再一起執行。
延遲數據可能來自系統重試、網路延遲、系統故障、上游工作延遲等等,這些延遲會影響到數據完整性和準確性,因此需要重新處理以確保之後資料不會有問題。
舉一個具體的例子,Netflix 會在首頁推薦一些用戶曾經觀看過的影片,詢問用戶是否要繼續觀看。假設因為資料延遲,讓用戶的觀看紀錄沒有及時傳遞成功,等到下次該用戶使用 Netflix、想要繼續觀看影片時,可能會發現播放進度的時間點不對,他已經看過那些片段了,造成不愉快的使用體驗,而這絕對是 Netflix 所不樂見的。
使用一個固定的回朔窗口(fixed lookback window)以重新處理資料:Netflix 假設大多數的延遲事件都會在某個時間窗口內抵達,例如假設所有在六點多(18:00-18:59)發生的事件,都一定會在兩小時內,也就是最晚在九點(21:00)之前抵達。因此,他們會在 21:00 重新處理發生 18:00-18:59 的所有數據。然而,這個方法有一個很明顯的問題,就是其實說不定該窗口根本沒有遲到的數據,或是比例極小,而 Netflix 卻需要消耗資源以重新處理所有數據,增加處理時間和計算成本。
增加警報:每當出現延遲數據時,就標記延遲數據出現的時間,阻止所有 pipelines,並手動干預,重新處理丟失的事件。但是這個方法非常仰賴人力的手動干預,若延遲事件頻繁發生時,重新處理數據和追趕上其他 pipelines 應有的進度的成本很高。
看起來這兩個方法都十分沒有效率,當 Netflix 蒐集的資料越來越多、data pipelines 也越來越多時,更不太可能使用上述的方法。因此,他們開發了 Psyberg——是一個增量資料處理框架,來更加有效率地處理這個問題。
Psyberg 是一個資料處理框架(processing framework),利用 Iceberg 中的 metadata 解決延遲數據處理的問題。
這句話到底是什麼意思?讓我們來一一介紹。
Iceberg 是一個表格格式(table format),專為大數據分析而設計。最初由 Netflix 開發,後來捐給 Apache。這種表格格式定義資料在儲存系統的結構跟 meta-data 格式,包含資料表的資訊,例如 snapshot 的建立時間、操作的執行類型和時間,建立、更新分區的摘要。這些資訊可以被資料處理框架使用,以有效率地管理和處理資料。
Psyberg 是一個建立在 Iceberg 之上的資料處理框架,利用 Iceberg 的 meta-data 來有效地處理資料。
簡單來說,表格格式定義了資料的結構和組織方式,而資料處理框架則提供一套工具和流程來處理和管理資料流程。
好,大概知道這兩個名詞代表的意思之後,他們又是怎麼幫助 Netflix 處理延遲資料呢?讓我們繼續看下去。
我們已經知道 Psyberg 是一種資料處理框架,他會依據 Iceberg 紀錄的 meta-data 來管理數據,因此也可以自動偵測和管理延遲到達的資料,也會知道資料是在哪一個分區。因此,無論資料多晚抵達、落在哪個分割區,都不需要人工干預,Psyberg 可以自動並有效地處理這些資料,確保系統中資料準確性。
Psyberg 怎麼這麼神奇?他究竟是看了哪些紀錄的資料呢?主要分為兩種來源:Iceberg 紀錄的 meta-data 跟 Psyberg 自身紀錄的 meta-data。
在細看他們兩種來源分別紀錄的資訊之前,我們先來認識一個名詞——ETL 處理的高水位標記(ETL Process High Watermark)。
在 ETL 過程中,「高水位標記」是一個時間戳記,用來標記數據處理 pipelines 中最後一次成功更新的時間點。它其實就是一個檢查點,用於追蹤從上次更新以來的變更,確保下一次 ETL 只會處理新的或已修改的數據,有助於避免重新處理舊數據,提高效率。
Iceberg 使用 meta-data 表來管理和追蹤數據表中的變更,其中兩個關鍵 meta-data 表是:
1. Snapshots metadata table
這個表紀錄了以下資訊:

圖片來源:[1]
這張表有助於追蹤數據的變更,以及理解自上次高水位標記以來對表執行的操作。
2. Partition metadata table
這個表紀錄了以下資訊:

圖片來源:[1]
他們會紀錄事件 landing 的時間跟 processing 的時間。而這兩個時間的差異如下圖所示,Event 2 在 6:00 就被處理(processing),但可能因為網路延遲,7:10 才抵達(landing),被視為延遲數據。藉由這種紀錄方式,Netflix 可以很有效率地找到延遲數據。
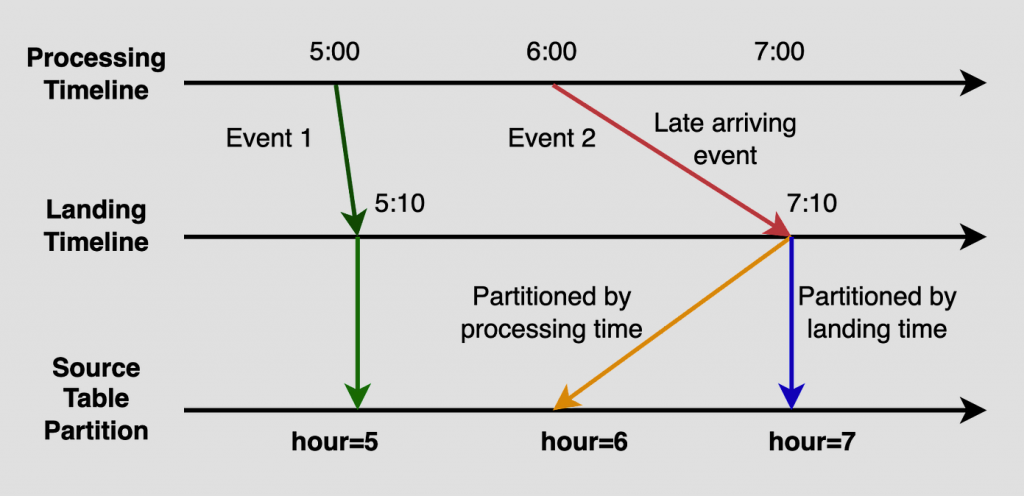
圖片來源:[1]
處了 Iceberg 的 meta-data 以外,Psyberg 也有紀錄自己的 meta-data tables,這兩張表跟 data pipeline 的資訊有關。
1. Session table
主要紀錄以下資訊:
2. High watermark table
藉由這些 meta-data,Netflix 得以有效率地追蹤所有延遲數據,也有助於確定下一次運行時,需要被處理的數。他們會更新高水位標記,確保下游系統知道數據完整且可用的時間點。
我們也對 Netflix 處理數據的方式略知一二啦,明天會來聊聊 Netflix 對數據的其他應用跟處理!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference:
[1] https://netflixtechblog.com/1-streamlining-membership-data-engineering-at-netflix-with-psyberg-f68830617dd1


 iThome鐵人賽
iThome鐵人賽