
我們在前一天介紹 DVC 這個強大的工具,可以用來管理資料和模型的版本,也可以使用它來追蹤實驗數據。不過,講到機器學習的實驗數據管理,也不可能不提到 TensorBoard、Weights & Biases 和 MLflow。
今天,就讓我們來看看這三個是什麼,他們之間又有什麼差別吧!
TensorBoard 是 TensorFlow 提供的可視化工具,有助於使用者追蹤深度學習模型的訓練過程。它能夠將訓練過程中的數據進行可視化,讓我們能夠更方便地測試、優化模型,以及檢查不同超參數對模型性能的影響。
TensorBoard 的官網說明他們支援以下幾個功能:
不過 Tensorboard 主要是為 local 使用而設計的,通常啟動後會在 local 的瀏覽器中使用。如果想要進行雲端協作,需要額外配置。

圖片來源:[1]
pip install tensorboard
監控模型訓練
import tensorflow as tf
from tensorflow import keras
# 載入資料集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 建立模型
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
# 編譯模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 定義 TensorBoard 的參數
log_dir = "logs/fit/" # 設定日誌儲存位置
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# 開始訓練並啟用 TensorBoard
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test), callbacks=[tensorboard_callback])
當模型訓練完成後,會將結果儲存在 logs/fit 中,我們可以使用 tensorboard --logdir=logs/fit 來啟動 TensorBoard。
此時,瀏覽器中會打開 TensorBoard,顯示訓練過程中的損失、準確率曲線以及其他指標。
雖然 TensorBoard 就已經可以滿足我們想要觀測實驗數據的需求,不過如果想要將結果部署到 cloud 上,方便團隊進行協作,或是對模型版本進行儲存和控管,甚至進行模型部署,可能要考慮使用其他工具。
接下來,讓我們來認識 Weights & Biases(W&B)。這是一個專門為 ml 專案設計的實驗追蹤平台,支援模型訓練過程的可視化,還提供模型的版本控制、資料版本控制,以及實驗結果的分享功能,方便團隊成員進行雲端協作。
W&B 的特點:
不過,WandB 的免費版本有一些限制,而且由於數據存儲在雲端,可能引起隱私問題。
pip install wandb
wandb.login(),此時會需要提供 wandb 的 API key。監控模型訓練
import wandb
import numpy as np
# 設定 config
config={
"learning_rate": 0.01,
"epochs": 10,
}
# 初始化 W&B
wandb.init(project="my-project", config=config)
# 模型訓練
for epoch in range(config.epochs):
loss = np.random.random()
accuracy = np.random.random()
wandb.log({"epoch": epoch, "loss": loss, "accuracy": accuracy})
wandb.finish()
W&B 的使用方式非常簡單,可以使用 wandb.log() 紀錄自己想要搜集的數據。
wandb.save("model.pth"),會在 local 儲存一份模型,並上傳到 W&B。可以用來保存模型訓練期間產生的結果,這個模型和本次執行的實驗是直接相關。wandb.run.log_code("."),如此一來,便可以在 UI 上進行程式碼的版本比較,如下圖所示。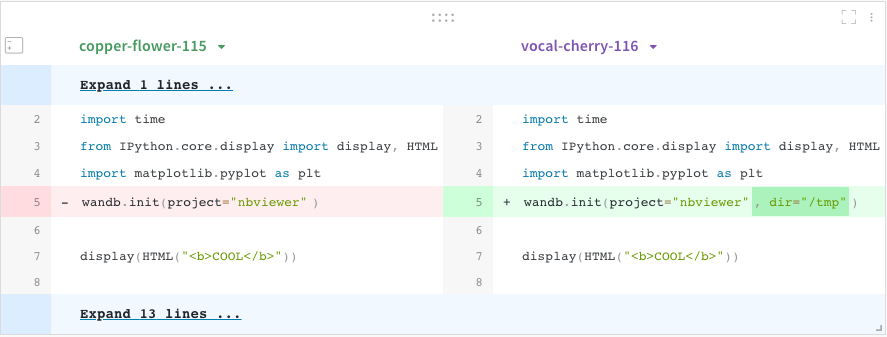
W&B 提供 artifact.add_file() 來儲存最終版本的模型和數據。這個會將檔案新增至 wandb Artifact 中。Artifact 可以獨立於特定運行存在,並可以在多個運行之間共享。支持版本控制,適合儲存想要永久存在的資產,如最終模型和資料集等。
以下是簡單的程式碼示範。
import wandb
wandb.init(project="my_project", name="model_training_run")
# 訓練模型
model = train_model()
# 創建一個 artifact
artifact = wandb.Artifact('model', type='model')
# 保存模型到 local
model.save('model.h5')
# 將模型文件添加到 artifact
artifact.add_file('model.h5')
# 記錄 artifact
wandb.log_artifact(artifact)
如果想要獲得特定的模型版本,可以使用以下程式碼:
import wandb
run = wandb.init(project="my_project", name="model_inference_run")
# 獲取最新版本的模型
artifact = run.use_artifact('model:latest')
# 下載模型文件
model_dir = artifact.download()
# 載入模型
model = load_model(f"{model_dir}/model.h5")
W&B 提供非常豐富的視覺化圖形,讓我們可以一目瞭然所有實驗的參數和結果。
line_plot:基本的 line plots,顯示 loss 和 accuracy 的變化。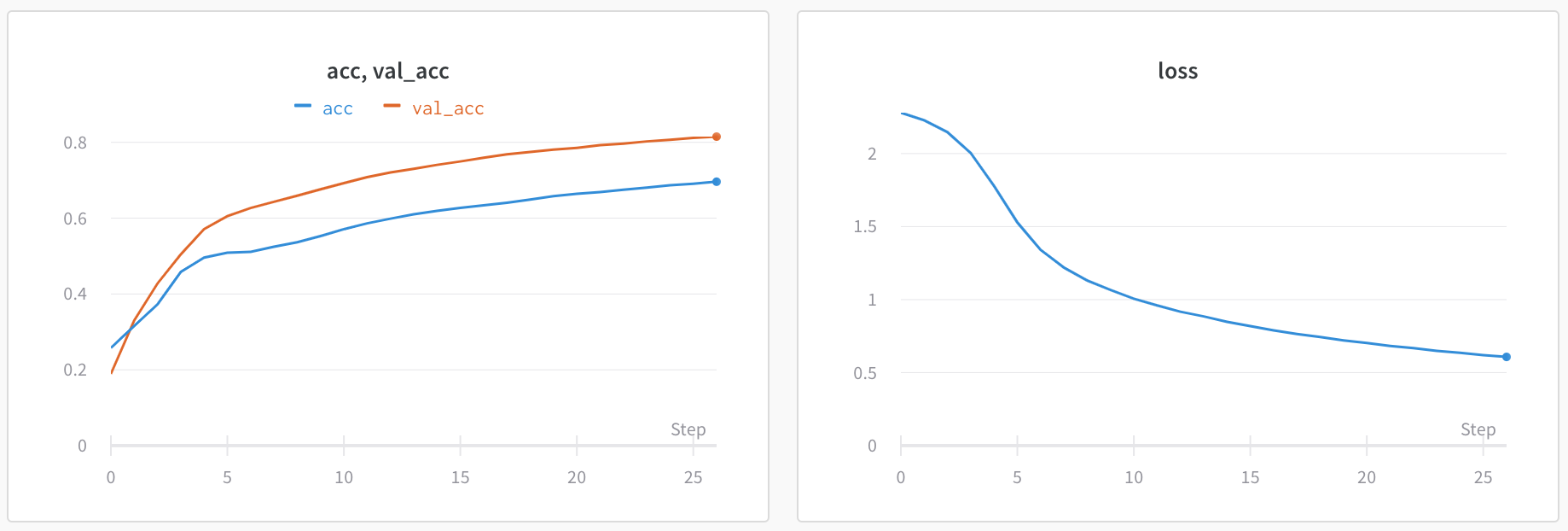
parallel_coordinates:我個人非常喜歡這個圖表,他很方便地顯示所有 hyperparamters 和模型準確率的關係。這張圖的解讀方式為,每一條線代表一組實驗和結果,準確率越高,線條越接近黃色。
我們可以很方便地看到,learning rate 越小,黃色的線段越多,代表模型的準確率越高。比起用表格呈現所有數據,這張圖可以很方便地看到每個 hyperparamters 帶來的影響。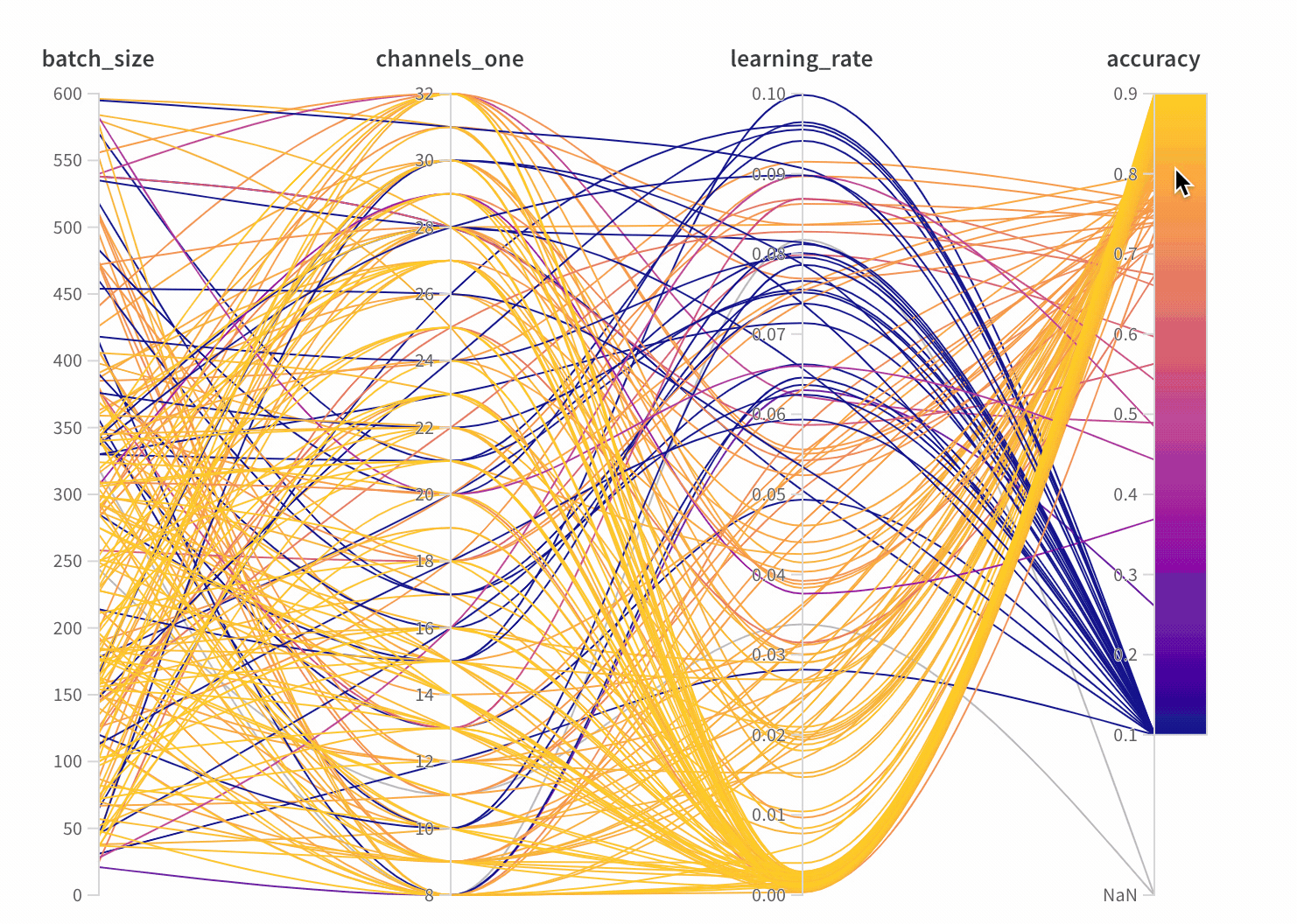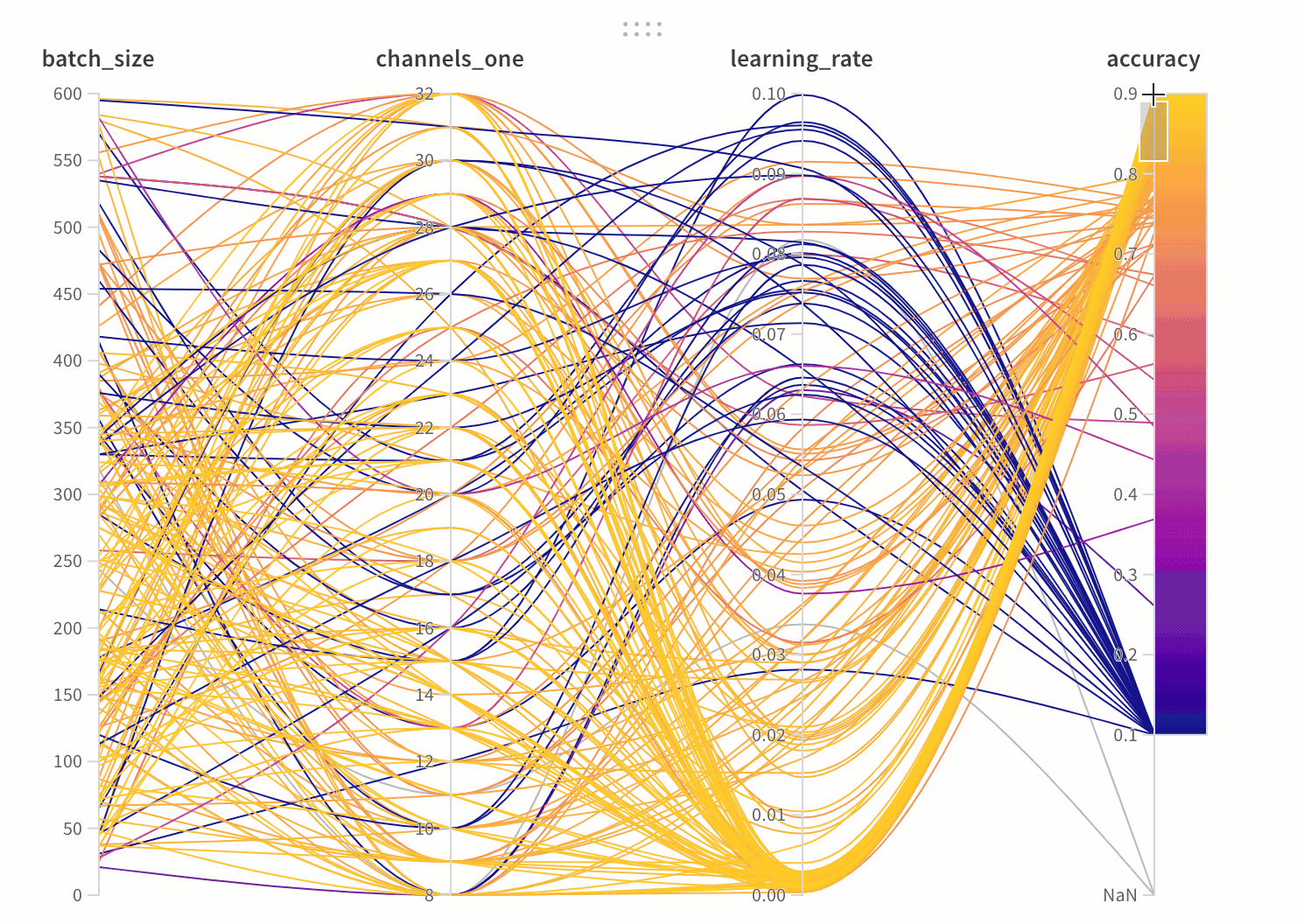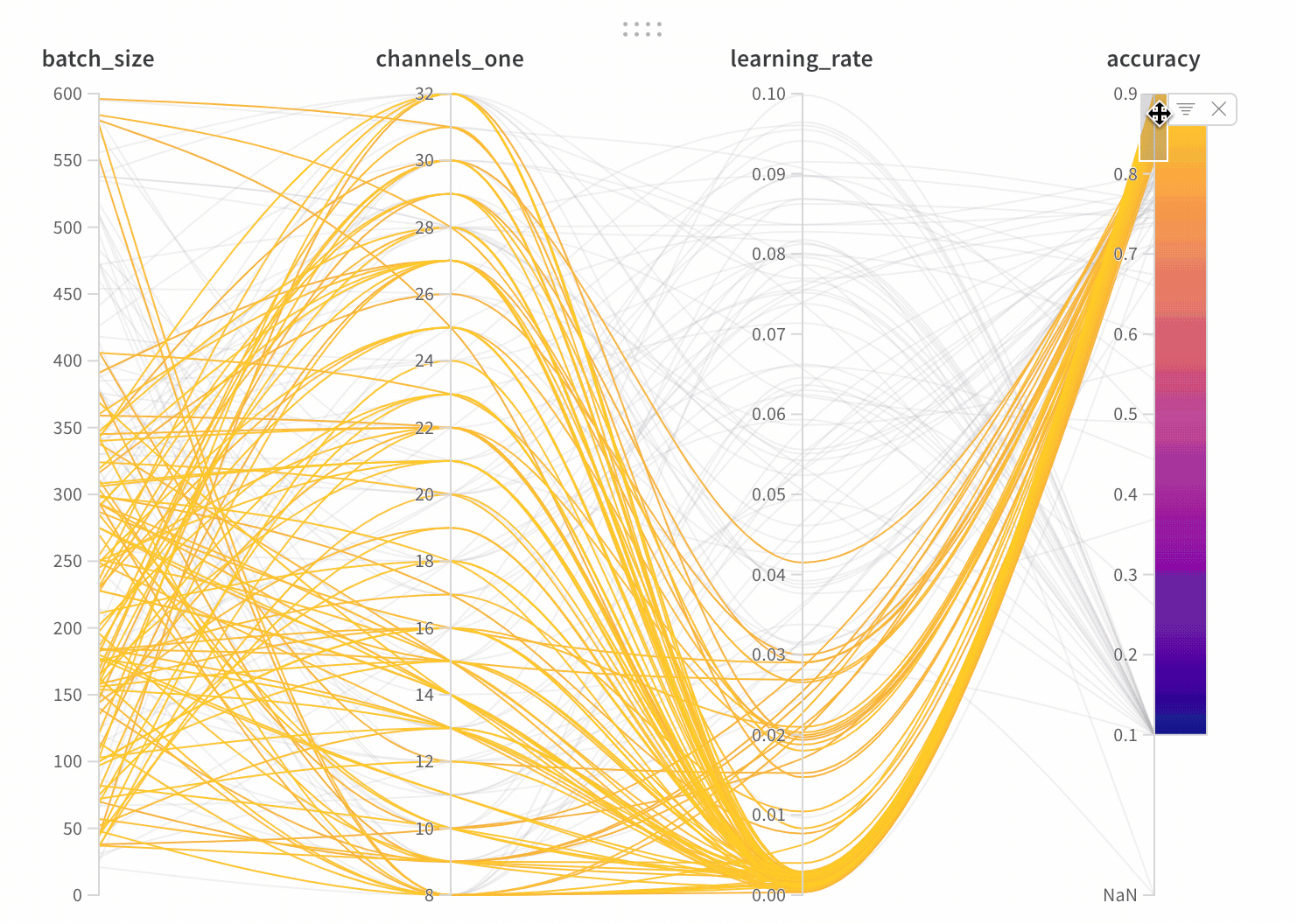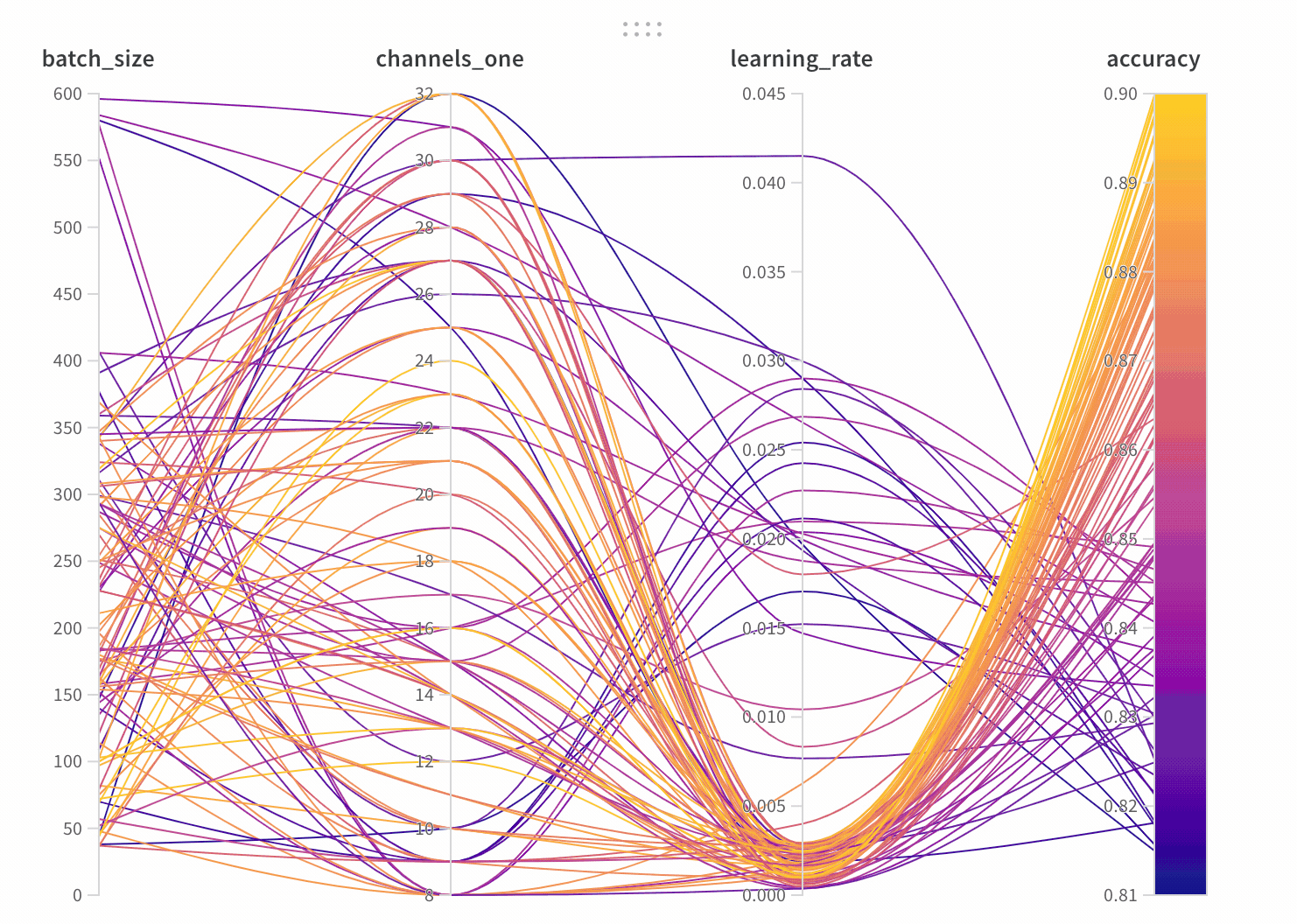
parameter-importance:可以利用這張圖看出每個 hyperparameter 的重要性(W&B 用 random forest 來計算這些重要性,將這些 hyperparameters 當作 inputs,並將 metric 當作 output,以計算每個 hyperparameters 的 feature importance values),以及他們和 metric 的 correlation。以下圖為例,metric 是 val_loss。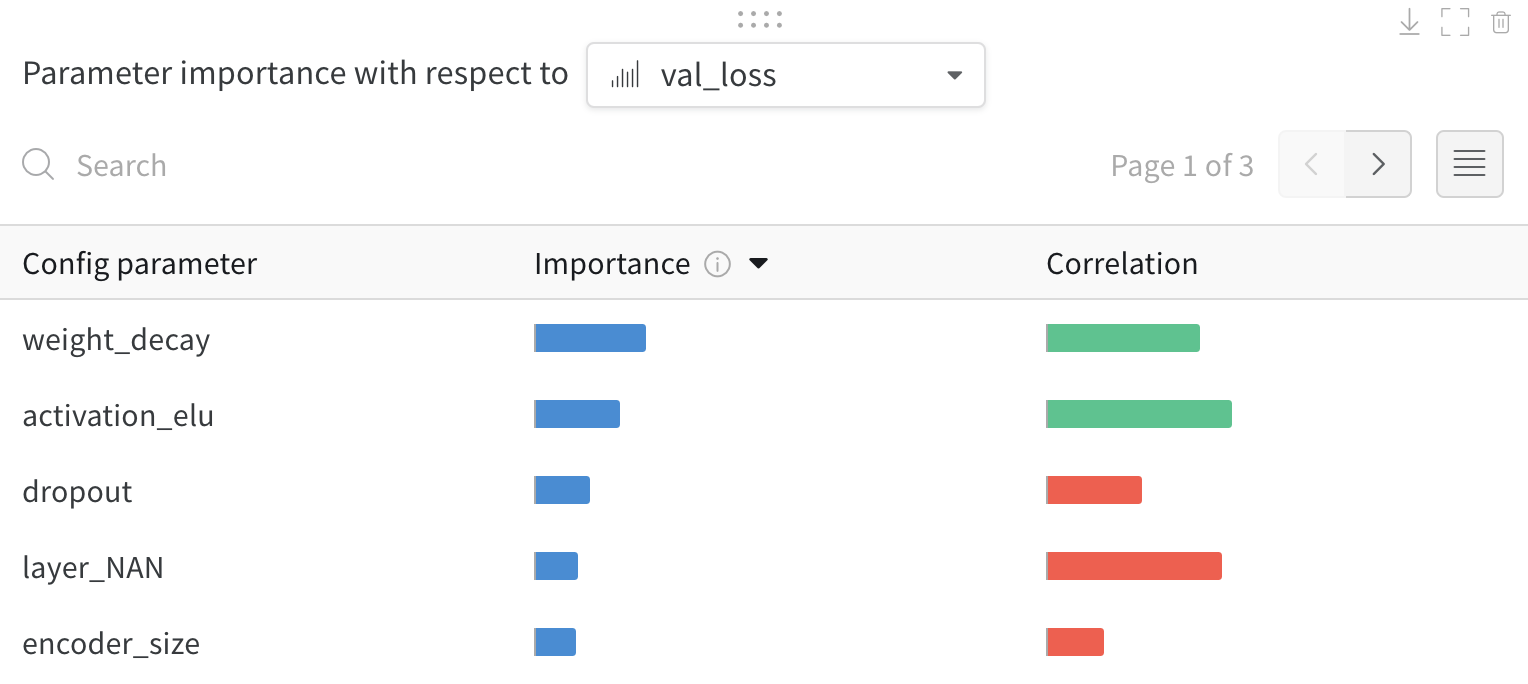
W&B 真的非常方便好用,提供多種豐富的視覺化圖形,幫助我們管理實驗數據和模型版本。
不過,W&B 本身不直接提供模型部署功能,如果需要部署模型,需要和其他部署工具一起使用,例如 MLflow、AWS SageMaker、Google Cloud AI Platform 等等。
那接下來我們就來介紹 MLflow 吧!
MLflow 是一個非常強大的 end-to-end 機器學習生命週期平台,提供實驗追蹤、模型打包和部署功能,具有以下特點:
缺點:
pip install mlflow
基本使用範例
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# 加載數據
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 啟動 MLflow 實驗
with mlflow.start_run():
# 設置參數
n_estimators = 100
max_depth = 6
# 創建和訓練模型
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
# 記錄參數和指標
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
mlflow.log_metric("score", score)
# 記錄模型
mlflow.sklearn.log_model(model, "random_forest_model")
mlflow ui,這將啟動一個Web界面,您可以在其中查看和比較不同的實驗。除了紀錄模型的實驗數據,MLflow 也可以保存並提取這些模型。
在上方的程式碼範例中,我們使用 mlflow.sklearn.log_model(model, "random_forest_model") 來紀錄模型。
接著,要使用 Model Registry,他提供一個集中的模型儲存,版本控制和階段轉換功能。
from mlflow.tracking import MlflowClient
client = MlflowClient()
# 註冊模型
model_uri = f"runs:/{run_id}/random_forest_model"
mv = client.create_model_version("RandomForestModel", model_uri, run_id)
# 將模型標示為 Production
client.transition_model_version_stage(
name="RandomForestModel",
version=mv.version,
stage="Production"
)
import mlflow
# 通過 run_id 和模型名稱加載模型
model_uri = f"runs:/{run_id}/random_forest_model"
loaded_model = mlflow.pyfunc.load_model(model_uri)
# 從已註冊的模型中加載特定版本
model_name = "random_forest_model"
model_version = 1
loaded_model = mlflow.pyfunc.load_model(
model_uri=f"models:/{model_name}/{model_version}"
)
# 使用加載的模型進行預測
predictions = loaded_model.predict(data)
也可以使用 MLflow 的 CLI 來使用模型。
# 下載模型文件到本地
mlflow models download -m "runs:/{run_id}/{model_name}" -d "./downloaded_model"
# 使用下載的模型進行預測
mlflow models predict -m "./downloaded_model" -i "./input_data.csv" -o "./predictions.csv"
MLflow 支援多種部署方式,包括在 local 部署、作為 REST API 部署,以及部署到各種 cloud platform。
import mlflow.pyfunc
# 加載模型
model_name = "RandomForestModel"
stage = "Production"
model = mlflow.pyfunc.load_model(f"models:/{model_name}/{stage}")
# 使用模型進行預測
predictions = model.predict(X_test)
MLflow 可以將模型作為 REST API 部署,使用 mlflow models serve 命令,會在 local 端啟動一個服務,監聽 1234 port。
mlflow models serve -m "models:/RandomForestModel/Production" -p 1234
此時,可以直接使用 API 來呼叫此模型。
import requests
import json
data = json.dumps({"columns": ["feature1", "feature2"], "data": [[1, 2], [3, 4]]})
response = requests.post("http://localhost:1234/invocations", data=data, headers={"Content-Type": "application/json"})
predictions = response.json()
MLflow 支持部署到多種雲平台,如 AWS SageMaker、Azure ML 等。以下是部署到 AWS SageMaker 的示例:
import mlflow.sagemaker as mfs
model_uri = "models:/RandomForestModel/Production"
mfs.deploy(app_name="random-forest-app",
model_uri=model_uri,
region_name="us-west-2",
mode="create")
以上我們介紹了三種機器學習模型的實驗管理工具,提供實驗數據的追蹤、視覺化,甚至能夠直接部署模型。
讓我們來總結一下:
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference
[1] https://www.tensorflow.org/tensorboard?hl=zh-tw
[2] https://docs.wandb.ai/
[3] https://mlflow.org/docs/latest/index.html

 iThome鐵人賽
iThome鐵人賽