在不同的脈絡中,資料模型 ( data model )背後所呈現的意涵以及設計時的目的其實不太一樣。舉例來說,在 OLTP 的系統中,更常使用的是 3NF 的正規化設計,盡量減少不同欄位間的相依。但在 OLAP 或是數據倉儲的系統中,更多人使用的會是偏向 dimensional modeling (star schema) 的設計,方便分析人員、業務人員進行分析。
另外,在 dbt 的概念中,data transformation 的過程也被稱做 data modeling ,所以在使用 dbt 時,每寫一次 SQL ,都被稱作一個 model。但在本質上,他其實比較像是模組化,而不是資料建模。

為了方便大家理解,之後講資料建模或是資料模型時,除非有特別說明,都是以資料綱要 (schema )的設計為主。
上一篇介紹了「模型是一種以簡馭繁」。那麼商業智慧 / 資料倉儲中的資料模型就是用「資料綱要設計」的「簡」去駕馭「商業流程」與 「報表需求」的「繁」。
在資料倉儲或是 BI 系統中,不管是多複雜的報表或是分析需求,都是想透過指標去了解商業流程的表現,最後採取行動優化,或是排除日常營運中遇到的問題。但資料分析師在面對需求時,最煩瑣的事情卻是要面對一些重複的資料轉換 / 資料清洗流程,而非透過指標找出潛在的問題與機會。更重要的是很難找到方法統一這些資料處理的邏輯。
舉一個 B2B 產業的 「訂單」這個流程為例:
- 在 CRM 系統中,有一些測試用的公司,每次分析時都要排除。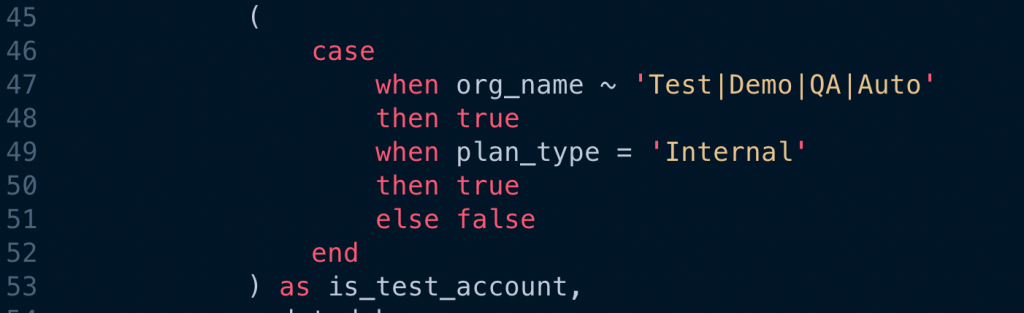
- 在 CRM 系統中的公司資料中不知道為什麼,訂單系統中的 公司 id 重複了好幾筆,而且產業這個欄位,有的有,有的沒有沒有,每次分析時,跟對相同的 org_id ,都需要去重複,並且都是取得有產業的那那一筆。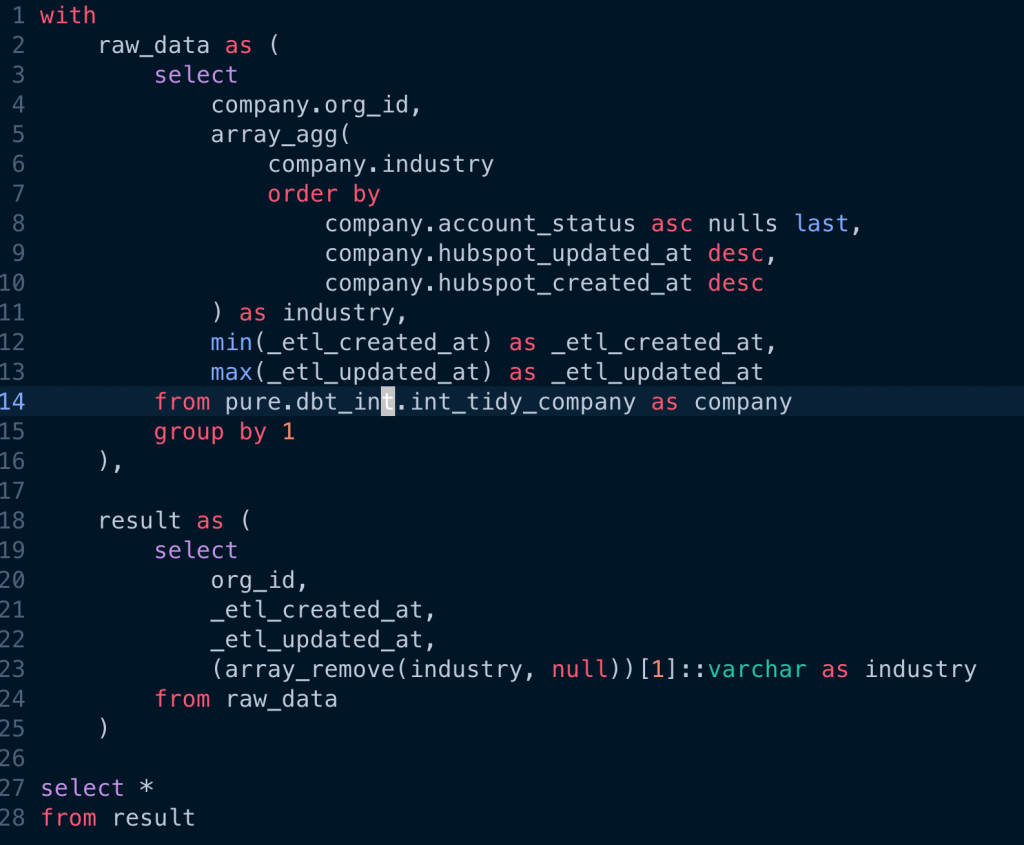
- 有些有缺失值的資料,需要用其他欄位補上。
不難想像,每次只要有分析需求跟產業或是庫戶有關,資料分析師都得做完類似的資料清洗,實在非常麻煩。
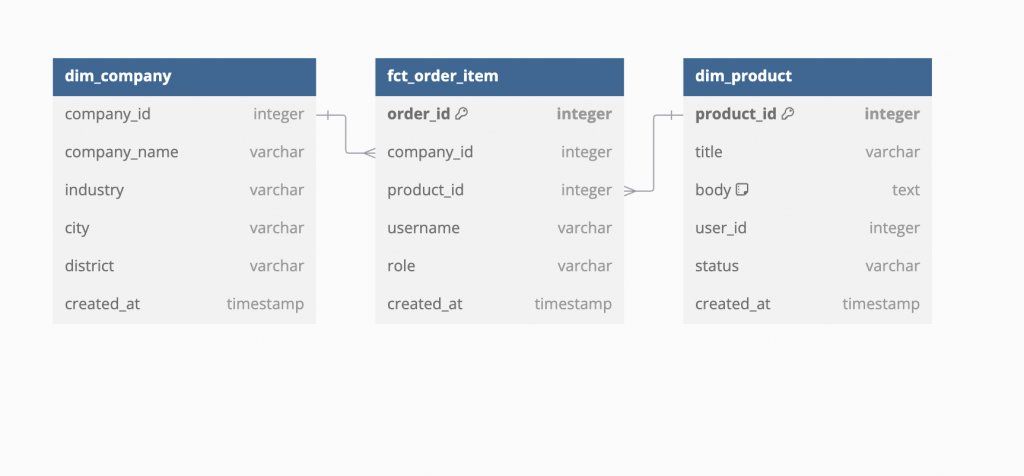
這時候,如果有人能把資料整理好,讓他們快速地取得指標,不僅能加快分析的效率,更能解決資料品質的問題。這時候 Star Schema 的設計與實作就能解決這個問題,因為在 B2B 最基礎關於訂單的商業分析中,在乎的不外乎以下問題:
這時如果有一個已經建好的資料模型(如下圖),資料表格以及欄位的定義以及將例外處理以及去重複處理好了,那資料分析師只需要處理簡單的 Join 以及 Aggregation Function 就能取得需要的資料,在進行分析時就相當方便:

有了上圖後,我們會發現用最簡單的方法理解 Star Schema,就是人事時地物。業務流程是事,人時地物是不同的維度 (Dimesion),透過維度的劃分,就能用比較有架構的方式找出問題來源,也有足夠彈性應付不同報表各字所需的顆粒度。
看到這裡,肯定有一些人會有疑惑:那為什麼不把資料模型設計成一張大表呢?因為如果太早設計成大表,就會減少了這組模型可以利用的彈性以及擴展性,像是:
基本上,不可能做出一張大表來滿足各式各樣的需求。因此在做資料建模時,需要意識到的是,該如何讓資料模型的設計能有彈性應付未來其他部門的需求,並不是只為了單一份報表做設計。
就像之前提到的,商業就像是由各式各樣的業務流程堆疊起來的賺錢機器。資料建模模擬的是各段商業流程,指標則是針對各商業流程(或是不同商業流程之間)的 計算 / 敘述統計。因此,在設計分析用的資料建模時,最直觀的原則就是將人事時地物拆分,讓事實表 (fct) 各自去對應到商業中各式各樣不同的業務流程。不同維度、顆粒度或是業務流程之間的比較,都應該放在處理單一報表需求時再做各字的設計。
目前簡單了介紹 Star Schema 的概念,他的目的是為了讓我們可以更一致且方便地去觀測、了解各項業務的運營狀況。但是從 OLTP 到 OLAP 的資料轉換流程其實非常複雜,也需要運用各式各樣的資料建模方法將資料從各個資料源中一步步轉換成分析用的資料模型。接下來會介紹一些在資料倉儲中常見的資料模型,之後再細說專屬分析用的資料建模設計。

