了解正規表達式(Regular expressions):
-非常強大但又相當晦澀。
-一旦理解就會覺得很有趣。
-正規表達式是一種獨立的語言。
-一種「標記字符」的語言 - 用字符進行程式設計。
-這是一種「老派」的語言 - 緊湊。
正規表達式快速指南:
-^: 匹配行首。也就是說,只有在行開頭出現的字符才會被匹配到。
-$: 匹配行尾。只有在行結尾出現的字符才會被匹配到。
-.: 匹配任意單個字符(除了換行符)。
-\s: 匹配任何空白字符,包括空格、制表符、換行符等。
-\S: 匹配任何非空白字符。
-: 匹配前面的字符零次或多次。
-?: 匹配前面的字符零次或多次,但盡可能少地匹配(非貪婪匹配)。
-+: 匹配前面的字符一次或多次。
-+?: 匹配前面的字符一次或多次,但盡可能少地匹配(非貪婪匹配)。
-[aeiou]: 匹配方括號中列出的字符中的任意一個。在這個例子中,匹配任何一個元音字母。
-[^XYZ]: 匹配不在方括號中列出的字符。在這個例子中,匹配除了X、Y、Z之外的任何字符。
-[a-z0-9]: 匹配指定範圍內的字符。在這個例子中,匹配任意一個小寫字母或數字。
-( ): 用於捕獲匹配的子字符串。括號內的內容將作為一個組,可以被單獨提取出來。
-英文版: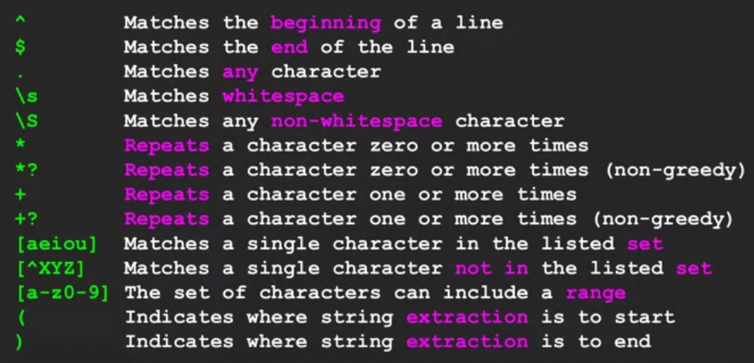
正規表達式模組:
-在使用正規表達式之前,必須先使用 import re 將 re 模組導入到你的程式中。
-re.search() 函數可以檢查一個字串是否符合特定的正規表達式。這有點像是在一個文本中尋找特定的關鍵字。
-re.findall() 函數可以從一個字串中找出所有符合正規表達式的部分。
萬用字元:
-「.」(點):這個字元可以匹配任意一個字符。
-「」(星號):當放在另一個字符或元字符後面時,表示前面的字符或元字符可以重複0次或多次。
-解釋:
◆ 點:舉例來說,如果我們要匹配一個包含三個字母的字串,可以使用 . {3}。這個表達式會匹配任何三個字母的組合,例如 "cat"、"dog"、"123" 等。
◆ 星號:這個字元通常和其他的元字符一起使用。例如,a 表示匹配0個或多個字母 'a'。所以,"a"、"aa"、"aaa"、甚至空字串都可以被匹配。
-範例:
◆ a.b:匹配以 'a' 開頭,以 'b' 結尾的任意字串。
◆ \d:匹配任意個數字。
◆ .@...*:匹配一個粗略的電子郵件地址格式。
-舉例:
(1)
-圖片說明:
◆ ^X.*: 的意思是:
■ 匹配以字母 X 開頭的一行。
■ X 後面可以是任何字符,數量不限(包括空格)。
■ 最後這行以冒號 : 結束。
◆ 符合的例子:
■ X-Sieve: CMU Sieve 2.3
■ X-DSPAM-Result: Innocent
■ X-DSPAM-Confidence: 0.8475
■ X-Content-Type-Message-Body: text/plain
(2)
-圖片說明:
◆ ^X-\S+: 的意思是:
■ 匹配以 X- 開頭的一行。
■ X- 後面跟著一連串的非空白字符。
■ 最後是以冒號 : 結束。
◆ 符合的例子:
■ X-Sieve: CMU Sieve 2.3
■ X-DSPAM-Result: Innocent

-程式碼說明:
◆ 第一行:導入 Python 的正規表達式模組。
◆ 第二行:定義一個包含數字的字串。
◆ 第三行:使用 re.findall() 函數,在字串 x 中查找所有連續的數字(一個或多個),並將找到的數字存儲在列表 y 中。
◆ 第四行:打印列表 y 的內容,即所有找到的數字。
◆ 第五行:輸出。
-正規表達式 [0-9]+:
◆ [0-9]:匹配任意一個數字(0 到 9)。
◆ +:匹配前面的元素(即數字)一次或多次。
◆ 因此,這個正規表達式用於匹配一個或多個連續的數字。

-正規表達式 ^F.+:
◆ ^:匹配字串的開頭。
◆ F:匹配字母 F。
◆ .+:匹配任意字符(.)一次或多次(+)。
◆ ::匹配冒號。
-為什麼會匹配到 'From: Using the :' ,而不是 'From:' 呢?
◆ 因為 .+ 是貪婪的,它會一直匹配下去,直到遇到 : 為止。所以,它匹配到了 'From: Using the :' 這整個部分。

-正規表達式^F.+?:
◆ .+?:匹配任意字符(.)一次或多次(+),但盡可能少地匹配(?)。
◆ 由於 .+? 是非貪婪的,因此匹配引擎會在找到第一個 : 時就停止匹配,所以最終匹配結果是 'From:'。
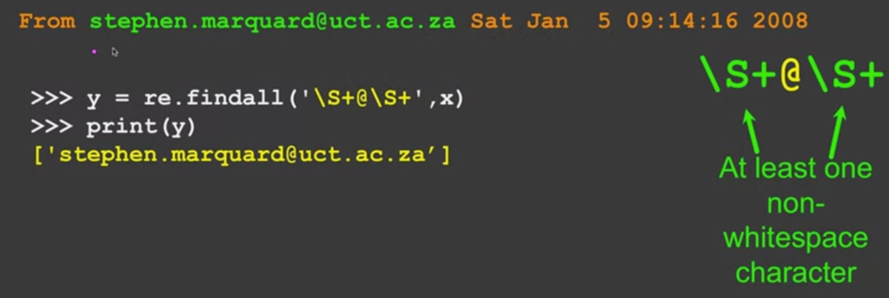
以上圖片皆出自於Coursera上的課程「Python for Everybody」來自University of Michigan。

