在介紹 Star Schema 與 Snowflake Schema 時,有提到表格與表格間的關聯應該盡量採取一對多的設計,避免多對多的設計,因此當 dim_company 是 SCD Type 1 時,dim_company 跟 fct_order_item 可以呈現如下的關聯:
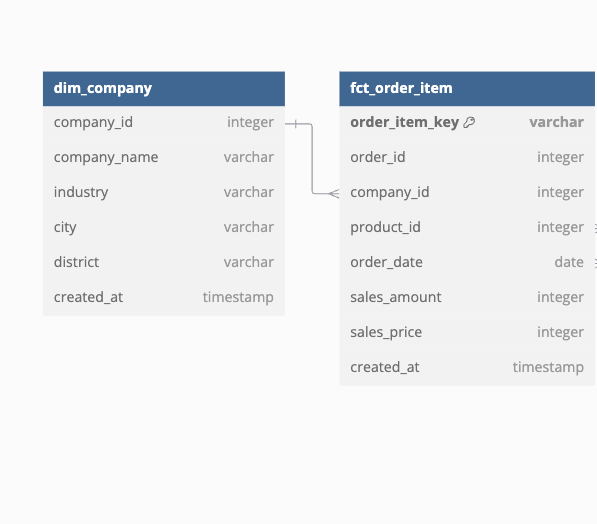
但如果將 dim_company 的設計改成 SCD type 2 那 dim_company 的 company_id 跟 fct_order_item 的 company_id 就不再是一對多,而變成多對多了。因此在做資料市集時,會採取相對一勞永逸的做法: company_key 先塞進 (populate) fct_order_item 中,因此 star schema 的設計會變成下圖:

如此一來,使用者在使用資料市集時,就不需要使用 Range Join,可以直接使用直觀的 key-based join。
select
date_trunc(month, dim_date.actual_date) as year_month,
dim_company.city,
coalesce(sum(fct_order_item.sales_amount), 0) as amount
from fct_order_item
left join dim_company on fct_order_item.company_key = dim_company.company_key
-- Range Join when company_key is not populated to fct tables
/*left join dim_company on fct_order_item.company_id = dim_company.company_id and fct_order_time.ordered_date between dim_company.valid_from and dim_company.valid_to*/
full join dim_date on fct_order_item.ordered_date = dim_date.actual_date
where dim_company.city = '台北市'
dim_company 的主鍵 (Primary key ) 也從 company_id 變成 company_key ,原本的 company_id ,一個 id 就能代表一間公司, 被稱為 Natural Key。而 company_key 則有點像是在記錄不同公司狀態的版本,被稱為 Surrogate Key。每當有任何一間公司的狀態發生改變,就會在 dim_company 新增一列,並押上舊狀態的到期日。
另外還有一些小細節,像是有些欄位 (例如:名字 )不論是在哪種維度表都會用最新的資訊,像是如果有一天 McBurger 改名成 DanBurger,那是不是把 dim_company 過去跟現在的 McBurger 都改成 DanBurger,會更方便之後使用呢:
| company_id | company_key | company_name | city | district | industry | created_at | valid_from | valid_to |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | DanBurger | 台北 | 天母 | Food and Restaurant | 2022-01-03 09:23:24 | 2022-01-03 09:23:24 | 2024-06-03 |
| 1 | 2 | DanBurger | 台中 | 西區 | Food and Restaurant | 2022-01-03 09:23:24 | 2024-06-03 09:23:24 | 2024-10-01 09:23:24 |
| 1 | 3 | DanBurger | 台中 | 西區 | Food and Restaurant | 2022-01-03 09:23:24 | 2024-10-01 09:23:24 |
眼尖的讀者到這邊應該會發現 SCD type 2 長得跟 Snapshot 真相似啊。事實上,他們紀錄真實世界資訊的方式也確實一樣。只是 Snapshot 通常指的是針對資料源的快照,SCD Type 2 則是資料市集中維度表的一個類型。簡單說,就是要在資料源就先保存好歷史資料 (Snapshot),資料市集才有辦法做出 SCD Type 2。
舉例來說,dim_company 的 city 以及 district 兩個欄位可能來自 CRM 系統,但是 industry 可能來自網路爬蟲,這時就必須先對資料源做 Snapshot ,後面在資料市集才有可能實踐出 SCD Type 2。因此在實務上另一個要處理的議題是,如何將兩張 snapshot 變成一張 SCD Type 2,有興趣的讀者可以參考這篇文章。
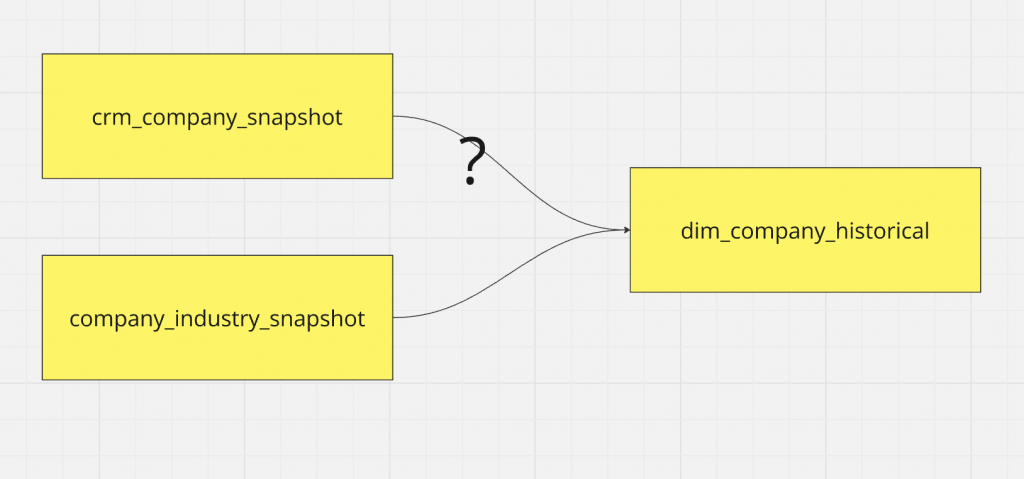
另外,如果大家還記得之前提到的 Data Vault 是能更快速精準的捕捉每次資料源變動的資料模型,也代表著他是另一種保存資料源歷史資料的形式。因此,如何在 Data pipeline 將 Data Vault 轉換成 SCD Type 2,也是個常見的議題,有興趣的人可以參考這支影片。
另外 dbt 其實也有個功能是對 table 做 snapshot,如果在資料庫中已經有一張 SCD Type 1 的 維度表了,每天對著他做一次 Snapshot 其實也能得到差不多的結果,但在後續的維護以及資料改動上,就不是那麼直觀。
現在介紹完在資料市集中,SCD Type2 的出現會怎麼微調資料市集的資料模型設計,以及介紹了一些資源給大家,讓大家在資料倉儲中可以順利地將資料源保存歷史資訊的資料模型轉換成資料市集中的 SCD Type 2 維度表。維度表的部分已經告一段落,明天將會開始介紹事實表。

