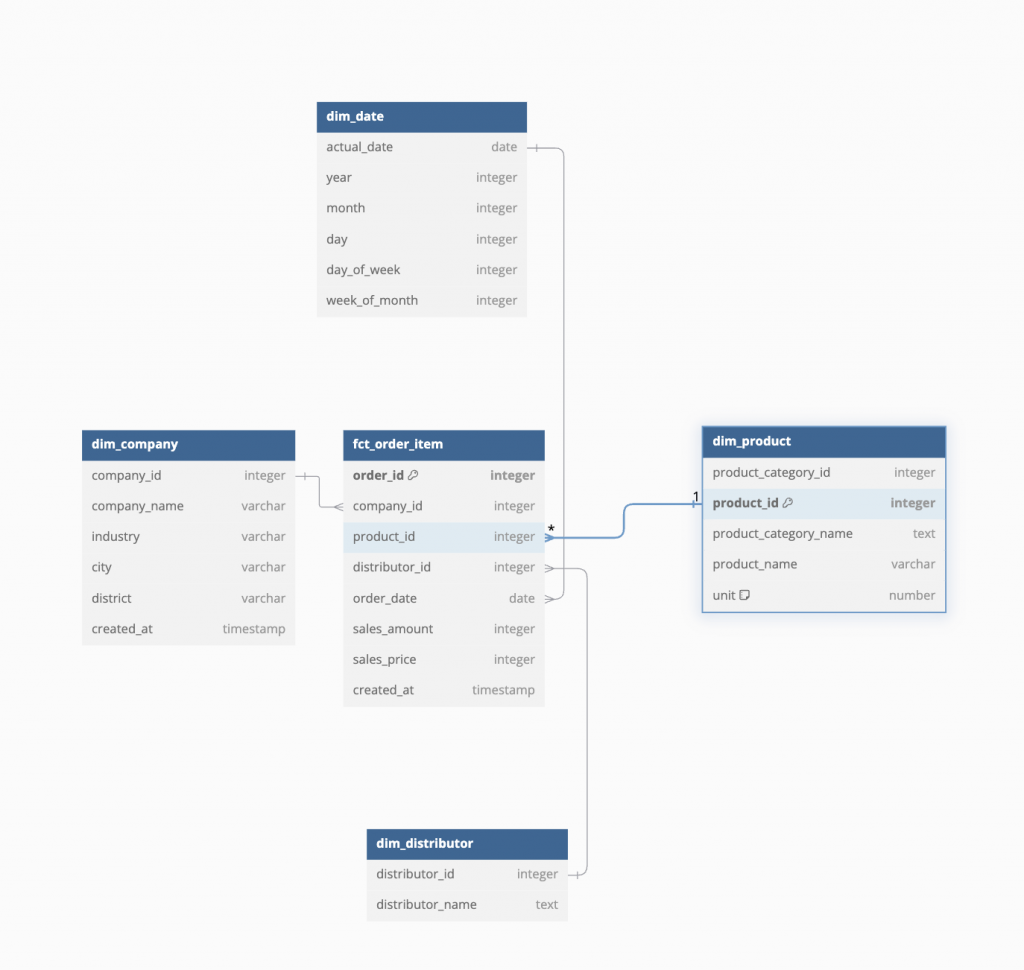
事實表通常被維度表環繞,欄位通常只有鍵值 ( id , key 等等)跟數字,每一列代表一個業務流程 (Business Process),透過與維度表的結合 ( join ) 以及 聚合函數 (summary function ) 比較不同實體間的表現,來呈現所謂的業績或是 KPI 的好或不好。在 Dimension Modeling 中事實表被大概分類成三種: Transaction Fact Table, Accumulating Snapshot Fact Table 以及 Periodic Snapshot Fact Table 。
Transaction Fact Table 是常見的事實表類型,上面星狀結構中的 fct_order_item 就是常見的 Transaction Fact Table 。用句子描述這類型的業務流程時,比較接近這個時候“發生”了什麼事情,這類的業務流程的「動作感」比較強烈,像是:
Accumulating Snapshot Fact Table,雖然看英文名字跟下面的 Periodic Snapshot Fact Table 比較相似,但我認為他在業務流程的敘述上更接近 Transaction Fact Table,只是動作的時間可能有複數個,像是:
Periodic Snapshot Fact Table 在敘述時,會更接近會計中「存量」的概念,最常見的例子是庫存。像是: 2024 年 1月 1 日 A 產品在 B 倉庫中還有 100 個庫存等等。這類型的事實表不太對時間維度表做相加,像是如果把昨天跟今天的庫存相加,基本上沒有任何商業上的意義。
而我們常見的指標就是針對這些事實表的每一筆紀錄做計算。當資料筆數過大時,也可以先將這些結果計算好儲存起來,加速之後的 query performace,這類表格就被稱為 Aggregated Fact Table,取名會以顆粒度來命名像fct_daily_product_sales ,紀錄的就不是每一筆訂單,而是訂單針對下訂日、以及產品做 group by 後的結果。
最後其實還有一種隱而不顯的業務流程,特徵是欄位中不具有可以量化的欄位,通常象徵欄位表與欄位表間的多對多關,像是。
學生註冊課程,一堂課可以有多位學生註冊,但一位學生也可以註冊多個課程。
使用者感興趣的主題類。
多位業務可能負責同一地區等等。
實務上,資料分析師或是資料工程師在面對需求時,使用者都頃向以指標或是報表做溝通。需要注意的是,指標或是報表背後常常有複數個想要量測的業務流程以及其所對應的事實表。像是業務的業績報表就隱藏了訂單這個業務流程以及業務負責的地區這個 factless fact table。
我自己在設計資料市集的資料模型 時,比較習慣先找出有哪些主要的維度表 (人時地物),接著找出主要的事實表,最後如果發現維度表與維度表之間存在多對多關係,就會再找出隱藏著的 Factless fact table。

