表示簡單字串:
-每個字元都用一個0到255之間的數字表示,並儲存在8位元的記憶體中。
-我們將「8位元(bits)的記憶體」稱為一個「位元組(byte)」。
-ord() 函數可以告訴我們一個ASCII字元的數字值。
◆ ASCII(American Standard Code for Information Interchange,美國資訊交換標準代碼)是一種常用的字元編碼,將英文字母、數字和一些特殊符號對應到特定的數字。
-舉例: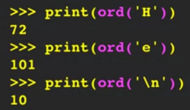
多位元組字符(Multi-Byte Characters):
-為了表示各種語言的豐富字符,電腦不再僅用一個位元組來代表一個字符,而是使用多個位元組。
-UTF-16、UTF-32、UTF-8: 這三種是常見的多位元組字符編碼方式。
-UTF-16: 每個字符固定使用兩個位元組來表示。
-UTF-32: 每個字符固定使用四個位元組來表示。
-UTF-8:
◆ 可變長度: 根據字符的不同,使用 1 到 4 個位元組來表示。
◆ 與 ASCII 相容: ASCII 字符在 UTF-8 中只佔用一個位元組,因此 UTF-8 檔案可以直接用 ASCII 編碼的程式開啟。
◆ 自動偵測: 許多程式可以自動偵測檔案是使用 ASCII 還是 UTF-8 編碼。
◆ 廣泛應用: UTF-8 是目前網路上最常用的字符編碼方式。
Python中的兩種字串:
-字串型態:
◆ Python 2: 有兩種主要的字串型態:
str: 通常是 ASCII 編碼,只支援有限的字元集。
unicode: 用來表示 Unicode 字符,需要加上 u 前綴。
◆ Python 3: 只有一種字串型態 str,且預設為 Unicode 編碼,支援更廣泛的字符集。
-bytes 型態:
◆ Python 2: 字串可以用 b 前綴轉換為 bytes 型態,表示位元組序列。
◆ Python 3: bytes 型態和 str 型態是分開的,用於表示原始的位元組數據。
-舉例: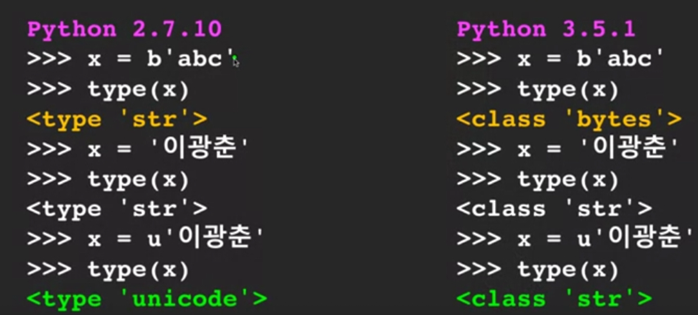
Python3與 Unicode:
-Python 3中的所有字串內部都是Unicode: 這意味著,Python 3 在處理文字時,預設採用Unicode編碼,能夠表示世界上大多數的文字。
-簡化字串操作: 這樣的設計簡化了程式設計師在處理不同語言文字時的複雜性。
-網路通訊: 當Python程式與網路資源(例如伺服器、資料庫)進行互動時,通常需要將Unicode字串編碼為特定格式(如UTF-8)才能傳輸。
Python字串與位元組的轉換:
-網路傳輸以位元組為單位: 當我們透過網路傳送資料時,實際上傳送的是位元組 (bytes) 的序列,而不是直接的文字。
-字串需要編碼: 在 Python 3 中,字串以 Unicode 表示,為了能夠在網路中傳輸,需要將 Unicode 字串編碼成特定的位元組序列,常見的編碼方式有 UTF-8、ASCII 等。
-位元組需要解碼: 從網路接收到的位元組序列,需要根據其編碼方式進行解碼,才能轉換回 Python 的字串。
-舉例: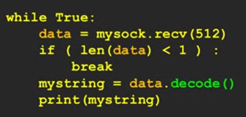
-程式碼說明:
◆ mysock.recv(512): 這行程式碼從網路連接 mysock 中接收最多 512 個位元組的資料,並將其存儲在變數 data中。
◆ if (len(data) < 1): 判斷接收到的資料長度是否為 0,如果為 0,表示連接已經關閉,跳出迴圈。
◆ mystring = data.decode(): 將接收到的位元組序列 data 解碼成字串,並將結果存儲在變數 mystring 中。這裡默認使用 UTF-8 編碼進行解碼。
◆ print(mystring): 將解碼後的字串輸出到控制台。
◆ 這段程式碼實現了一個簡單的網路客戶端,不斷從伺服器接收資料,並將接收到的位元組序列解碼成可讀的文字,然後輸出到螢幕上。
使用 urllib 讀取網頁:
-程式碼:
-程式碼說明:
1.第一行,導入模組:
◆ urllib.request: 用來開啟網路 URL 並讀取資料。
◆ urllib.parse: 用於解析 URL。
◆ urllib.error: 用於處理網路請求時可能發生的錯誤。
2.第二行,開啟網頁:
◆ urlopen() 函式會打開指定的 URL,並返回一個類似檔案物件的 fhand。這個物件讓我們可以像讀取本地檔案一樣,逐行讀取網頁的內容。
3.第三、四行,逐行讀取並印出:
◆ for line in fhand::這個迴圈會逐行讀取 fhand 中的內容,每次迭代 line 變數會指向當前行。
◆line.decode().strip():
■ decode():由於網路上的資料通常是以位元組的形式傳輸,所以我們需要將它解碼成字串才能處理。這裡默認使用 UTF-8 編碼。
■ strip():移除字串前後的空白字符,包括空格、換行符等。
■ print():將處理後的字串輸出到終端。
-程式碼總結:就像是用 Python 寫了一個簡單的瀏覽器,讓我們可以從網路上抓取文本資料,並將其顯示出來。
什麼是網路爬蟲(Web Scraping):
-是一種透過程式或腳本,模擬瀏覽器的行為,從網頁上擷取資料的技術。這個過程就像是有一個程式在網路上四處爬行,尋找並收集所需的資訊。
為什麼要進行網路爬蟲?:
-提取數據: 特別是社交媒體的數據,例如誰關注了誰。
-取回自己的數據: 從無法直接匯出的系統中提取數據。
-監控網站更新: 追蹤網站的最新資訊。
-為搜尋引擎建構資料庫: 建立網站索引,方便搜尋。
輕鬆從網頁中提取資料-Beautiful Soup:
-Beautiful Soup是一個Python的第三方庫,專門用於解析HTML和XML文檔。
-它提供了一套簡單易用的API,可以快速地從網頁中提取出需要的資料。相較於手動搜尋字串,Beautiful Soup更加高效、可靠。
以上圖片皆出自於Coursera上的課程「Python for Everybody」來自University of Michigan。


 iThome鐵人賽
iThome鐵人賽