資料標準化(Standardization)與正規化(Normalization)是資料處理中的兩個重要步驟,尤其在進行機器學習建模時,這兩個步驟能夠提升模型的性能和穩定性。今天,我們將介紹這兩個概念的區別,並展示如何將資料進行標準化與正規化處理。
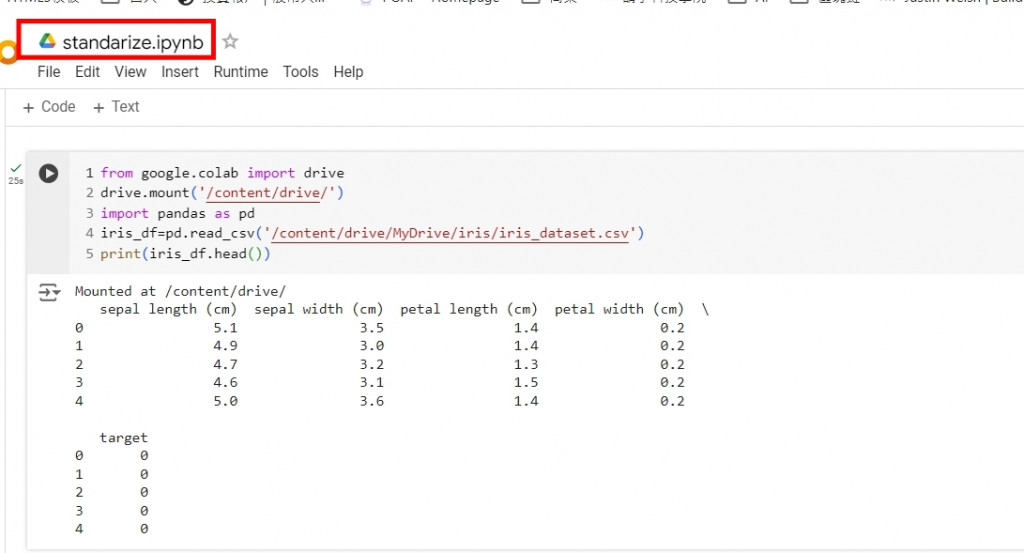
在原本資料夾中建立一個standarization.ipynb的檔案
並且第一段程式碼放入以下內容
from google.colab import drive
drive.mount('/content/drive/')
import pandas as pd
iris_df=pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
print(iris_df.head())
資料標準化是將資料轉換為平均值為 0、標準差為 1 的分佈。這種方法特別適合在資料存在不同單位或量級的情況下,保持資料的相對分佈特性。標準化的公式如下:
[ Z = \frac{X - \mu}{\sigma} ]
其中:
資料正規化是將資料壓縮到 [0, 1] 或 [-1, 1] 的區間,這在資料範圍不一致的情況下很有用。正規化的公式如下:
[ X' = \frac{X - X_{\min}}{X_{\max} - X_{\min}} ]
其中:
我們可以使用 sklearn 的 StandardScaler 來輕鬆地將資料進行標準化處理。
from sklearn.preprocessing import StandardScaler
import pandas as pd
# Select features to be standardized
features = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# Initialize the standardization tool
scaler = StandardScaler()
# Perform standardization on the selected features
iris_df[features] = scaler.fit_transform(iris_df[features])
# Display the standardized data
print("Standardized data:")
print(iris_df.head())
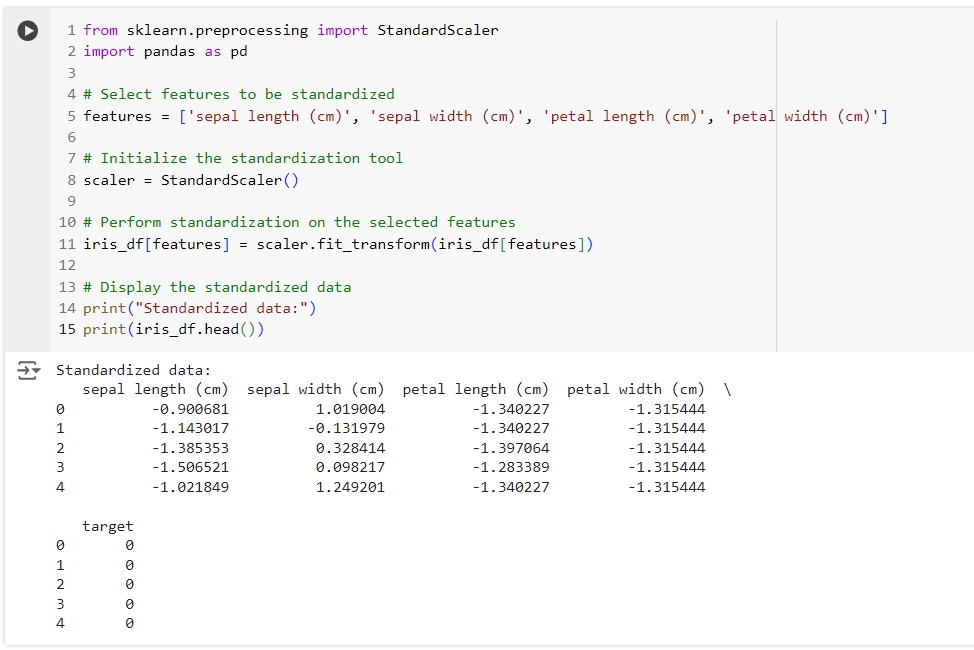
這段程式碼使用 StandardScaler 對 sepal length (cm)、sepal width (cm)、petal length (cm) 和 petal width (cm) 進行標準化處理,將資料轉換為平均值為 0、標準差為 1 的分佈。
我們可以使用 sklearn 的 MinMaxScaler 來將資料進行正規化處理。
from sklearn.preprocessing import MinMaxScaler
# Initialize the Min-Max Scaler
min_max_scaler = MinMaxScaler()
# Apply Min-Max normalization to the selected features
iris_df[features] = min_max_scaler.fit_transform(iris_df[features])
# Display the normalized data
print("Normalized data:")
print(iris_df.head())
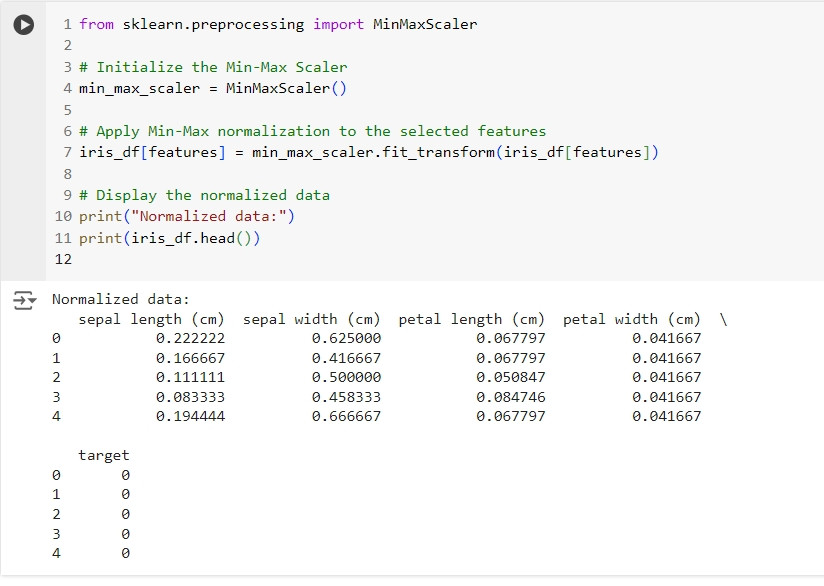
這段程式碼使用 MinMaxScaler 將資料轉換為 [0, 1] 區間的分佈,方便後續的模型訓練和分析。
有時我們需要將資料標準化或正規化到其他範圍,例如 [-1, 1]。我們可以通過設定 feature_range 參數來實現。
from sklearn.preprocessing import MinMaxScaler
# Set the normalization range to [-1, 1]
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
# Apply Min-Max normalization with the specified range to the selected features
iris_df[features] = min_max_scaler.fit_transform(iris_df[features])
# Display the normalized data with the custom range
print("Data normalized to the range [-1, 1]:")
print(iris_df.head())
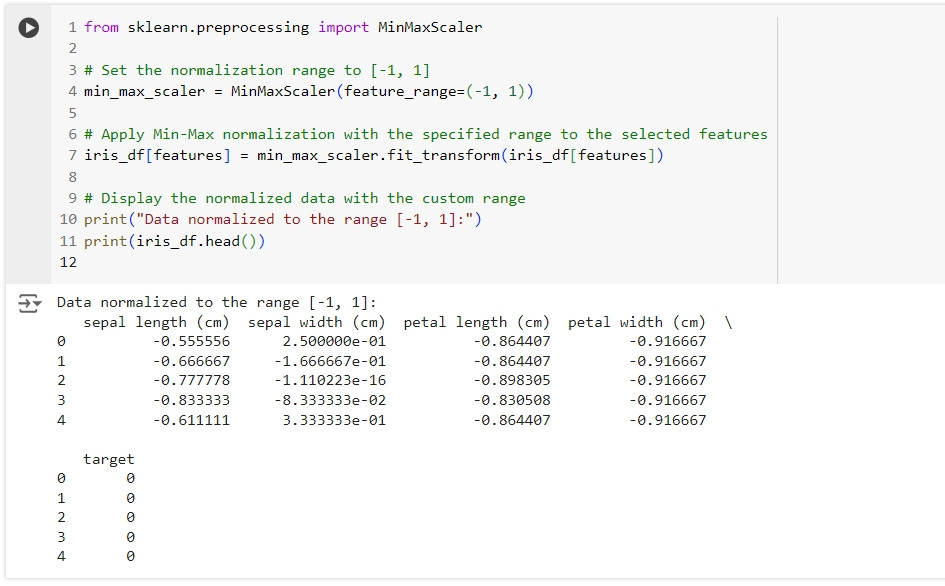
這段程式碼會將資料壓縮到 [-1, 1] 的區間,方便進行一些需要負值的模型訓練。
有時我們需要將標準化或正規化後的資料還原回原始狀態,可以使用 inverse_transform() 函數來實現。
# Restore the data to its original state
iris_df[features] = scaler.inverse_transform(iris_df[features])
# Display the restored data
print("Restored data to original state:")
print(iris_df.head())
這段程式碼會將資料還原回標準化或正規化前的原始狀態,方便我們進行原始資料的比較。
今天我們學習了資料標準化與正規化的概念和應用,包括:
sklearn 進行標準化與正規化處理。資料標準化與正規化是機器學習中重要的資料預處理步驟,能夠提升模型的性能和穩定性。接下來,我們將學習如何使用 Pandas 進行進階的數據操作,如資料透視表、進階篩選等。


 iThome鐵人賽
iThome鐵人賽