模型評估是機器學習中至關重要的一個步驟,它可以幫助我們了解模型的性能,並根據評估結果進行模型的調整和優化。今天,我們將學習如何使用交叉驗證和其他方法來評估模型的準確性與表現,從而選擇最佳的模型來解決問題。
繼續用昨天sklearn的檔案,先把昨天的檔案全部重新跑過一遍
在建立模型後,我們需要了解模型的準確性、穩定性以及在不同資料上的泛化能力。模型評估能夠幫助我們:
混淆矩陣是分類模型中常用的評估工具,它能夠顯示模型預測結果與實際結果的分佈情況。
我們將使用 Day 29 中的邏輯回歸模型來計算混淆矩陣。
from sklearn.metrics import confusion_matrix
# 使用測試集進行預測
y_pred = classifier.predict(X_test)
# 計算混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩陣:")
print(conf_matrix)
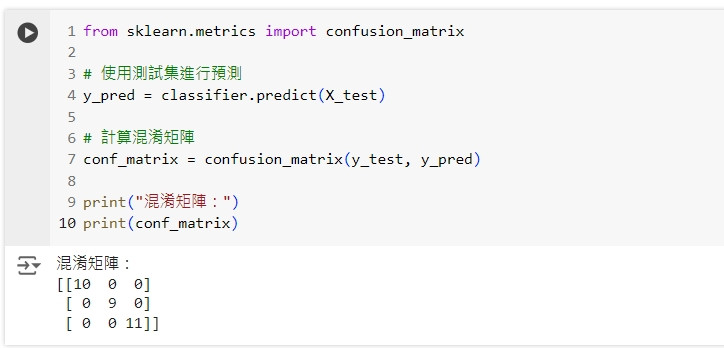
這段程式碼會顯示模型在測試集上的混淆矩陣,矩陣中的每個元素表示預測結果與實際結果的對比。
我們可以使用 Seaborn 繪製混淆矩陣的熱圖,使其更加直觀。
# 繪製混淆矩陣的熱圖
import seaborn as sns
import matplotlib.pyplot as plt
# 繪製混淆矩陣的熱圖
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('confusion matrix')
plt.xlabel('predict')
plt.ylabel('real')
plt.show()
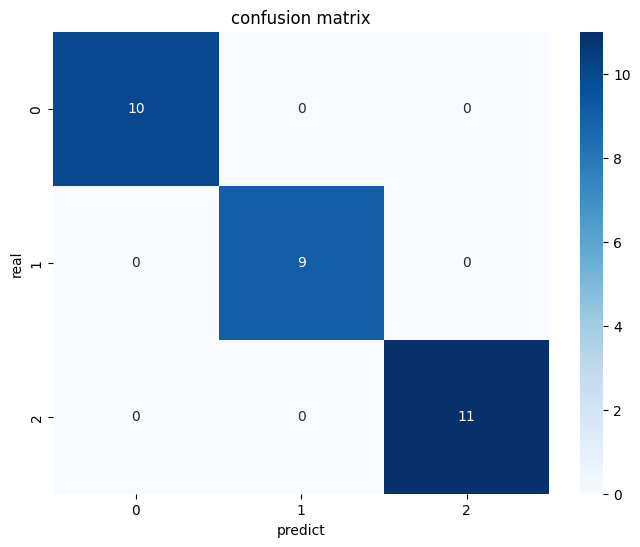
這段程式碼會繪製混淆矩陣的熱圖,顯示預測結果與實際標籤的對比情況。
交叉驗證(Cross-Validation)是一種常用的模型評估方法,能夠更全面地評估模型在不同資料集上的表現。最常見的交叉驗證方法是 k 折交叉驗證(k-fold cross-validation)。
我們將使用 cross_val_score() 函數來進行 5 折交叉驗證。
from sklearn.model_selection import cross_val_score
# 進行 5 折交叉驗證
cv_scores = cross_val_score(classifier, X, y, cv=5)
print("每次交叉驗證的準確率:", cv_scores)
print(f'平均準確率:{cv_scores.mean():.2f}')
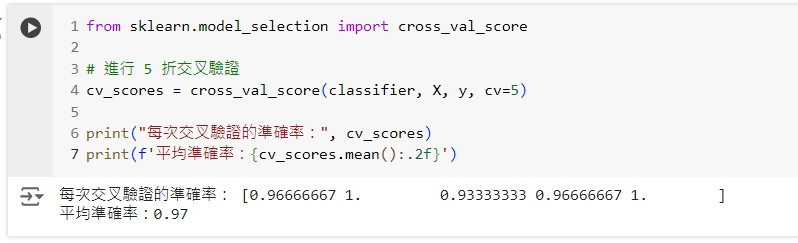
這段程式碼會在不同的訓練集與測試集劃分上進行 5 次模型訓練和評估,並輸出每次的準確率和平均準確率。
網格搜尋(Grid Search)是一種超參數調整的方法,可以在交叉驗證的基礎上自動搜尋最佳參數組合。
from sklearn.model_selection import GridSearchCV
# 定義要調整的參數範圍
param_grid = {
'C': [0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
# 初始化網格搜尋
grid_search = GridSearchCV(classifier, param_grid, cv=5, scoring='accuracy')
# 執行網格搜尋
grid_search.fit(X, y)
# 顯示最佳參數與最佳準確率
print(f'最佳參數:{grid_search.best_params_}')
print(f'最佳準確率:{grid_search.best_score_:.2f}')
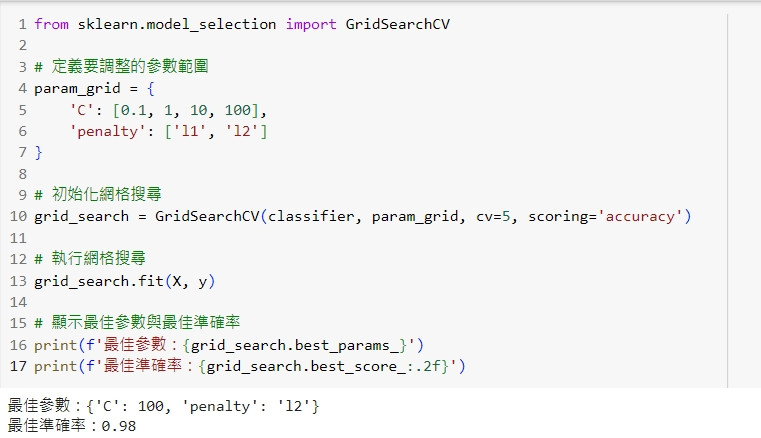
這段程式碼會使用網格搜尋在交叉驗證的基礎上找到最佳的參數組合,並輸出最佳參數與準確率。
學習曲線可以幫助我們觀察模型在不同訓練資料量下的表現,從而判斷模型是否存在過擬合或欠擬合。
我們可以使用 learning_curve 函數來繪製學習曲線,觀察模型隨著訓練資料增加的變化。
from sklearn.model_selection import learning_curve
# 計算學習曲線
train_sizes, train_scores, test_scores = learning_curve(classifier, X, y, cv=5, n_jobs=-1, train_sizes=np.linspace(0.1, 1.0, 10))
# 計算平均訓練與測試得分
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
# 繪製學習曲線
plt.figure(figsize=(10, 6))
plt.plot(train_sizes, train_scores_mean, 'o-', color='r', label='訓練準確率')
plt.plot(train_sizes, test_scores_mean, 'o-', color='g', label='測試準確率')
plt.title('學習曲線')
plt.xlabel('訓練資料量')
plt.ylabel('準確率')
plt.legend()
plt.show()
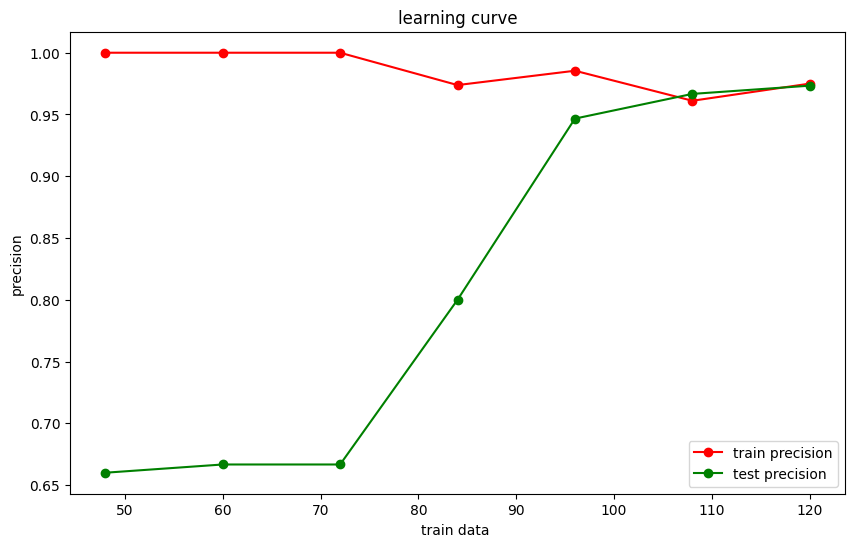
這段程式碼會繪製學習曲線,幫助我們觀察模型在不同訓練資料量下的訓練準確率與測試準確率。
在某些模型中,我們可以觀察特徵重要性來判斷哪些特徵對模型的影響最大。
# 顯示決策樹模型的特徵重要性
feature_importances = decision_tree.feature_importances_
for name, importance in zip(X.columns, feature_importances):
print(f'{name}: {importance:.2f}')

這段程式碼會輸出每個特徵的重要性分數,幫助我們了解哪些特徵對模型的影響最大。
今天我們學習了如何使用交叉驗證和其他方法來評估模型的準確性與表現,包括:
經過這 30 天的學習,我們從零開始了解了資料分析的基本概念、資料處理、視覺化,以及機器學習模型的應用。希望這些知識能幫助你在資料科學的旅程中更加順利,繼續探索並實現更複雜的資料分析和預測!


 iThome鐵人賽
iThome鐵人賽