本文將介紹在編寫代碼之前,該如何為Kubernetes集群選擇最佳節點。
個性化IaaS服務,低至0.005 美元/GB的出站流量費!
每當我們需要創建Kubernetes集群時,肯定首先都會問自己:我該使用什麼類型的工作節點?
具體需要多少個?或者如果正在使用Linode Kubernetes引擎(LKE)等託管式Kubernetes服務,
那麼我們到底該使用8個2GB的Linode實例,還是2個8GB的Linode實例來實現您所需的計算能力?
畢竟需要明確的是:並非所有工作節點中的資源都可以用於運行工作負載。
消除複雜性、提高創新力!Akamai 雲計算服務,靈活的開放式架構,簡化開發體驗!
Kubernetes節點預留
在Kubernetes節點中,CPU和記憶體會被劃分給:
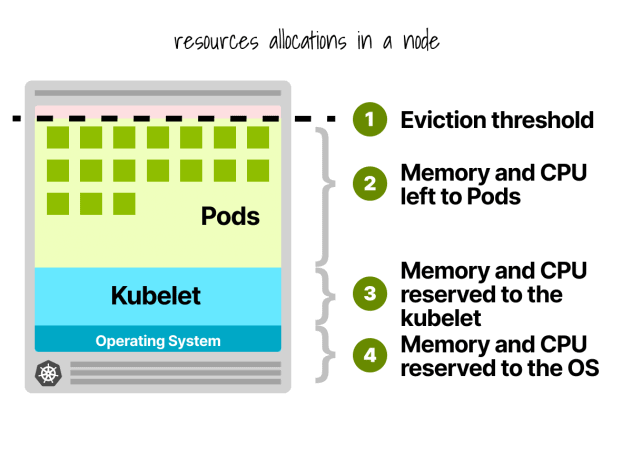
500MB記憶體。
60m的CPU。
此外,還有100MB記憶體為驅逐閾值保留。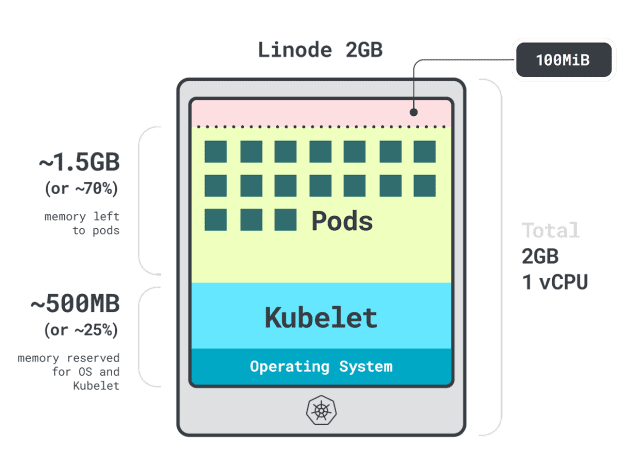
目前,我們有 30% 的記憶體和 6% 的 CPU 無法被工作負載使用。
每個雲提供商在資源限制方面各有差異,但在 CPU 使用限制上,他們似乎達成了共識:
第一個核心的6%;
下一個核心的1%(最多2個核心);
接下來的2個核心的0.5%(最多4個);以及
四個以上核心的0.25%。
至於記憶體方面的限制,不同提供商之間有很大的差異。但一般來說,記憶體的預留往往遵循以下限制:
前4GB記憶體的25%;
接下來4GB記憶體的20%(最多8 GB);
接下來8GB記憶體的10%(最多16 GB);
下一個112GB記憶體的6%(最多128 GB);以及
超過128GB的任何記憶體的2%。
既然知道了工作節點內資源的分配方式,現在該問出一個棘手的問題了:我們應該選擇哪種實例?
由於答案因具體情況而異,我們需要根據工作負載的實際情況來選擇最佳工作節點。
剖析應用程式
在Kubernetes中,我們有兩種方法來指定容器可以使用多少記憶體和CPU:
請求:通常與正常操作時的應用程式消耗量相匹配。
限制:設置允許的最大資源數量。
Kubernetes調度程式使用請求來確定在集群中分配Pod的位置。由於調度程式不知道消耗情況(Pod尚未啟動),
因此它需要一個提示。這些“提示”就是請求;我們可以為記憶體和CPU分別設置請求。
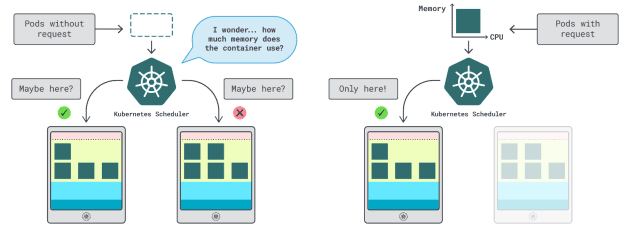
kubelet使用限制在記憶體使用超出允許範圍時停止進程。如果使用的CPU時間超過允許的範圍,kubelet也會限制該進程。但是,該如何選擇適當的請求和限制值呢?
我們可以測量工作負載性能(例如平均值、95和99百分位數等)並將其用作請求和限制。為了簡化該過程,可以通過兩個便利的工具來加速分析:
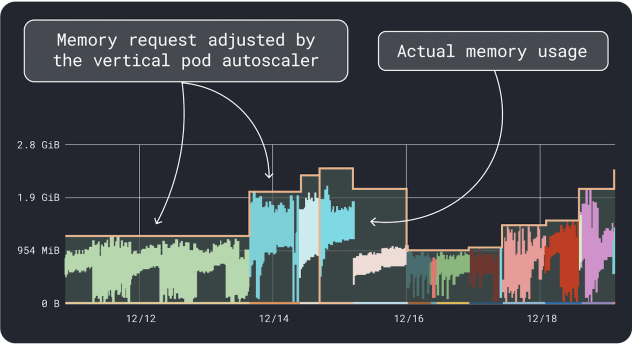
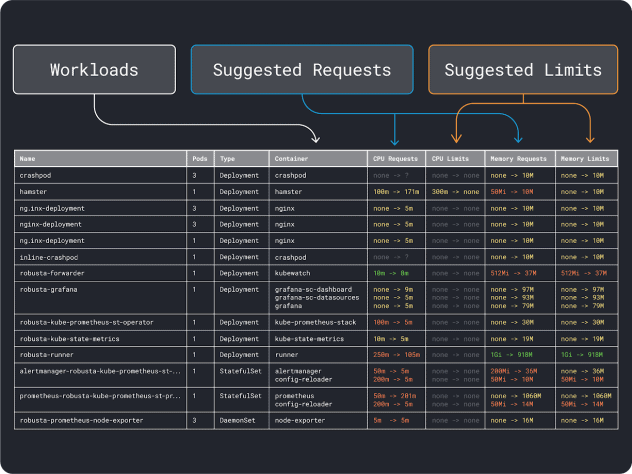
在大致了解資源需求後,終於可以進一步選擇合適的實例類型了。
選擇實例類型
假設估算自己的工作負載需要2GB的記憶體請求,並且估計至少需要約10個副本。我們可以排除大多數小於2GB的小型實例。此時也許可以直接使用某些大型實例,例如Linode 32GB。
接下來,可以將記憶體和CPU除以可部署在該實例上的最大Pod數量(例如在LKE中的110個),以獲得記憶體和CPU的離散單元數量。
例如,Linode 32GB的CPU和記憶體單元為:
記憶體單元為257MB(即(32GB – 3.66GB預留)/ 110)
CPU單元為71m(即(8000m – 90m預留)/ 110)
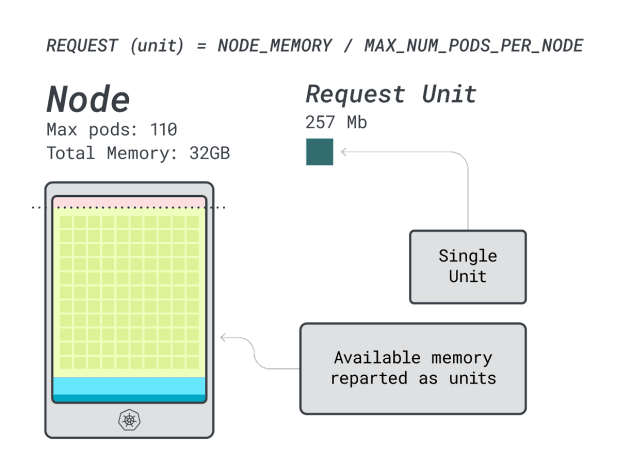
太好了!在最後一步中,我們可以使用這些單元來估算有多少工作負載可以適應節點。
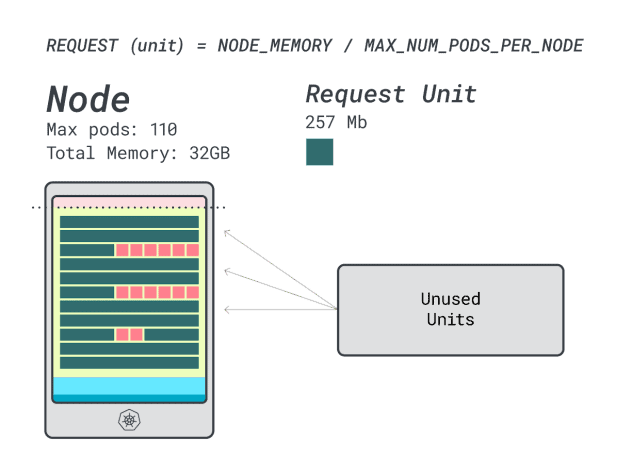
假設想要部署一個Spring Boot,請求為6GB和1 vCPU,這相當於:
適合6GB的最小單元是24個單元(24 * 257MB = 6.1GB)
適合1 vCPU的最小單元是15個單元(15 * 71m = 1065m)
這些數位表明,記憶體耗盡之前受限會將CPU耗盡,並且最多可以在集群中部署(110/24)4個應用程式。

當我們在此實例上運行四個工作負載時,將使用:
24個記憶體單元* 4 = 96個單元,有14個未使用(約12%)
15個vCPU單元* 4 = 60個單元,有50個未使用(約45%)
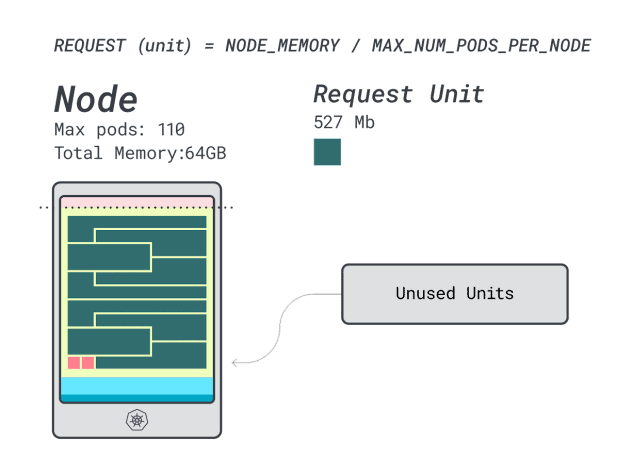
還不錯,但能做得更好嗎?讓我們嘗試使用Linode 64GB實例(64GB / 16 vCPU)。
假設要部署相同的應用程式,數位會發生一些變化:
記憶體單元約為527MB(即(64GB – 6.06GB預留)/ 110)。
CPU單元約為145m(即(16000m – 110m預留)/ 110)。
適合6GB的最小單元是12個單元(12 * 527MB = 6.3GB)。
適合1 vCPU的最小單元是7個單元(7 * 145m = 1015m)。
可以在這個實例中放多少工作負載?由於將耗盡記憶體,並且每個工作負載需要12個單元,所以最大應用程式數是9(即110/12)。
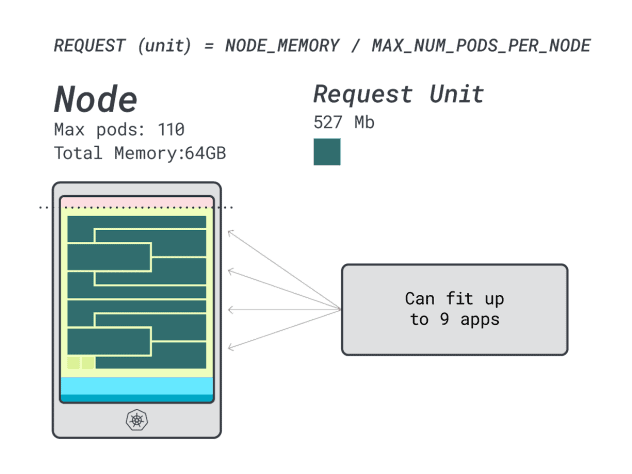
計算效率/浪費比例將會發現:
12個記憶體單元* 9 = 108個單元,有2個未使用(約2%)
7個vCPU單元* 9 = 63個單元,有47個未使用(約42%)
雖然浪費的CPU數量幾乎與前一個實例相同,但記憶體利用率得到了顯著改善。
最後,我們還可以比較一下成本:
Linode
32GB實例最多可以容納4個工作負載。在這樣的總容量下,每個Pod的成本為每月48美元(即實例成本192美元除以4個工作負載)。
Linode 64
GB實例最多可以容納9個工作負載。在這樣的總容量下,每個Pod的成本為每月42.6美元(即實例成本384美元除以9個工作負載)。
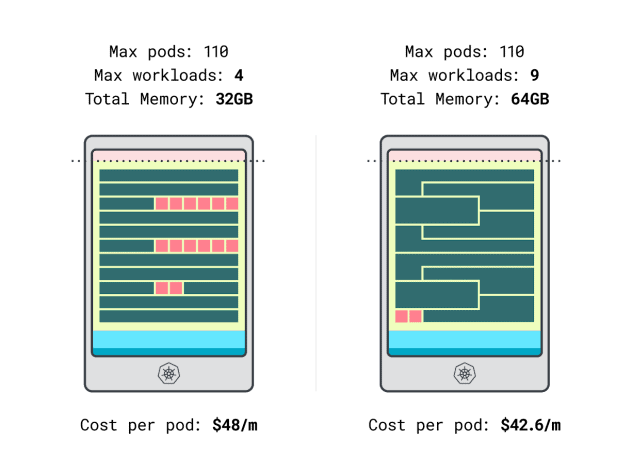
換句話說,選擇較大的實例可以為我們每月每個工作負載節省多達6美元。太棒了!
使用計算器對比不同節點
如果想測試更多實例該怎麼辦?進行這些計算需要很多工作。好在我們可以使用learnsk8s計算器加快該過程。
使用該計算器的第一步是輸入記憶體和CPU請求。系統會自動計算保留的資源並提供利用率和成本建議。此外還有一些額外的實用功能:按照應用程式用量分配最接近的CPU和記憶體請求。如果應用程式偶爾會突發高CPU或記憶體使用率,也可以靈活應對。
但是當所有Pod都將所有資源使用到極限會發生什麼?這可能導致超額承諾。我們可以通過門戶中的小元件瞭解CPU和記憶體超額承諾的百分比。那麼當超額承諾時具體又會發生什麼?
如果記憶體超額承諾,kubelet將驅逐Pod並將其移動到集群中的其他位置。
如果CPU超額承諾,工作負載將按比例使用可用的CPU。
最後,我們還可以使用DaemonSets和Agent小元件,這是一個方便的機制,可以模擬在所有節點上運行的Pod。例如,LKE將Cilium和CSI外掛程式部署為DaemonSets。這些Pod使用的資源對工作負載不可用,應從計算中減去。該小元件可以幫我們做到這一點!
如果想測試更多實例,該怎麼做?
進行這些計算需要耗費大量精力,但好消息是,我們可以借助 learnsk8s 計算器
來加速這個過程。
第一步是輸入記憶體和 CPU 請求,系統會自動計算保留資源,並提供利用率和成本建議。這個計算器還具備一些實用功能,比如根據應用程式的實際使用情況,分配最接近的CPU 和記憶體需求。如果應用偶爾有突發的高 CPU或記憶體使用情況,該工具也能靈活應對。
那麼,當所有 Pod 使用資源達到極限會發生什麼?
這可能會導致超額承諾。透過系統中的元件,我們可以監控 CPU和記憶體的超額承諾百分比。具體來說,當超額承諾發生時:
最後,我們還可以使用 DaemonSets 和 Agent 小元件 來模擬所有節點上運行的Pod。比如,LKE 將 Cilium 和 CSI 外掛程式部署為 DaemonSets,這些 Pod使用的資源對其他工作負載不可用,因此應從資源計算中扣除。這個小元件可以自動幫助我們完成這一操作。
總結
本文深入探討了一個系統化的方法,旨在幫助大家有效確定 LKE集群的規模及其成本。此外也歡迎企業或個人申請註冊免費試用的Linode帳號,親自體驗這些解決方案的強大之處。
 Akamai
Akamai
