在今天我會針對Selenium做第二個相關的實作:
我會將FB作為我的範例app,並試著透過Selenium的自動輸入方式進行自動登入。
(範例程式碼部分參考
https://medium.com/@kenAaa/%E5%AF%A6%E4%BD%9Cpython%E8%87%89%E6%9B%B8%E8%87%AA%E5%8B%95%E7%99%BB%E5%85%A5-c82c8f450f6e )
在最後我也會對我這幾天的學習做出一個總結。
那就開始今天的Selenium實作了。
因為昨天其實講過很多相關的語法了,所以今天我會減少一點文字解釋,
只對於那些跟昨天方法不一樣的做解釋,那有興趣的
可以去看我昨天前天的文章,這邊就不拖台錢了,
先來看看今天完整的程式碼: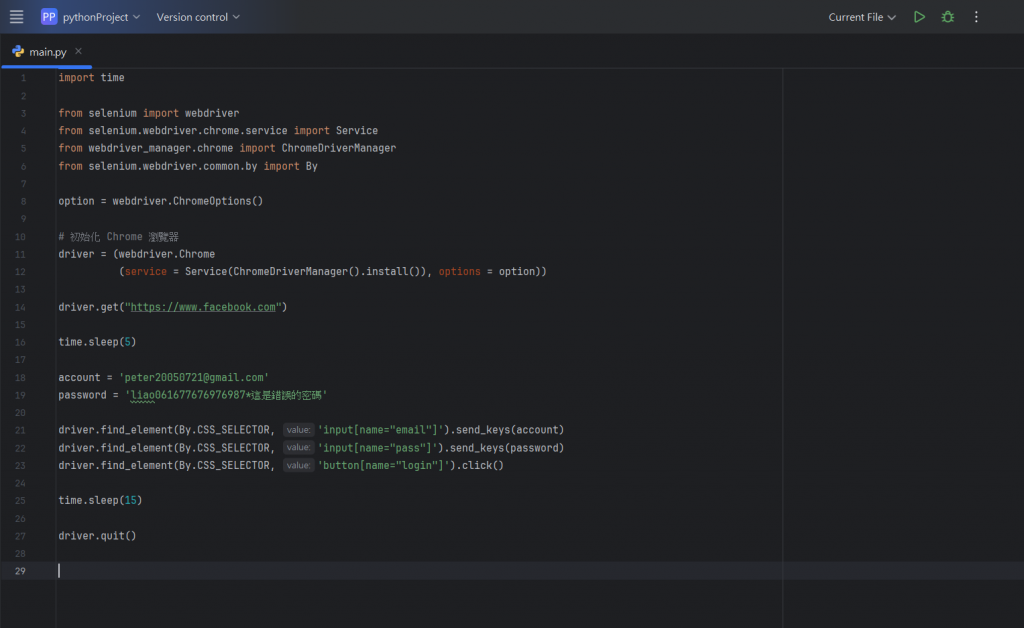
那以下,我就來針對跟昨天不一樣的以及沒有使用過的方法來進行解釋:
首先,我們就是要來講講昨天沒有應用到的 “service” ,
它能夠在程式碼中起到什麼功用:
Service作用?
Service類是在Selenium 中的一個工具,
用來管理像是 ChromeDriver 這樣的瀏覽器驅動的後台運行。
每當你用 Selenium 打開瀏覽器,瀏覽器驅動器會在後台默默地運行,
而 Service 就是要負責啟動和控制這個驅動器的運行狀態,
如此讓你不需要手動去啟動或停止 ChromeDriver。
from webdriver_manager.chrome import ChromeDriverManager:
ChromeDriverManager 則是一個很方便的工具,
它主要用於自動管理和下載正確版本的 ChromeDriver。
通常,Chrome 瀏覽器都會定期做版本的更新,而跟它
配套的 ChromeDriver 也需要做出相應得更新。
而如果手動下載或更新 ChromeDriver,又或是沒有
開啟自動下載更新,情況就可能變得繁瑣且容易出錯。
ChromeDriverManager 就是可以幫助你
自動下載與你本地瀏覽器版本匹配的 ChromeDriver的一個工具,
讓你可以省去手動管理的麻煩事,減少負擔。
driver = (webdriver.Chrome
(service = Service(ChromeDriverManager().install()), options = option)):
先講這一整行的作用是什麼好了:它的目的主要就是為了這行程式碼通過
webdriver.Chrome 來打開 Chrome 瀏覽器,
並確保使用的是與 Chrome 瀏覽器版本匹配的驅動程式。
那以下我再來對程式碼分行解釋:
webdriver.Chrome:
這是用來創建一個 Chrome 瀏覽器實例的函數。
service=Service(ChromeDriverManager().install()):
這部分指定了要使用的瀏覽器驅動服務,也就是安裝正確的程式版本。
ChromeDriverManager().install():
這就是上述所提到的,會自動下載並安裝正確的 ChromeDriver
(通過 ChromeDriverManager 工具來實現)。
Service():
啟動這個 ChromeDriver,並將其作為服務來管理,以保證驅動器正常運行。
options=option:
這部分則是用來傳遞 Chrome 瀏覽器的配置選項,例如是否開啟無頭模式、禁用通知等。
總結來說,這行程式碼通過 webdriver.Chrome
來打開 Chrome 瀏覽器,並確保使用的是與 Chrome 瀏覽器版本
匹配的驅動程式。而在運行期間,瀏覽器配置(如是否開啟特定模式)
也可以通過 options 來靈活設定。
因為這邊三行的運作模式都是一樣的,所以我就挑其中的一行出來講。
這邊跟我們所撰寫的上一篇程式有著明顯的區別,也就是所調用的方法不同。
在上一份實作中,我們是使用By.Name去搜索所想要選取的物件,
並查詢它在HTML中的表示方法(有興趣的可以看昨天的文章)。
而在今天,我們則是使用了「CSS選擇器」作為我們調用物件的方法。
那「CSS選擇器」有什麼不一樣呢?相較於前面只能
依靠現有元素來使用的方法,CSS明顯是一個更靈活的工具。
它適合對結構複雜的頁面進行精確定位,特別是當你需要
根據多個條件來選擇元素時。它適用於幾乎所有情況,
因為它可以根據元素的標籤、類別、屬性等多種條件來選擇。
而在這邊,我們就是利用它的id功能,直接查找到
HTML 頁面中 name="email" 的 input標籤(即輸入電子郵件地址的欄位),
並將 account 變數中的內容(你的帳號)填入該欄位,
就直接完成我們的需求了。
在講述完這些不一樣的改動後,下方就是所呈現出的結果:
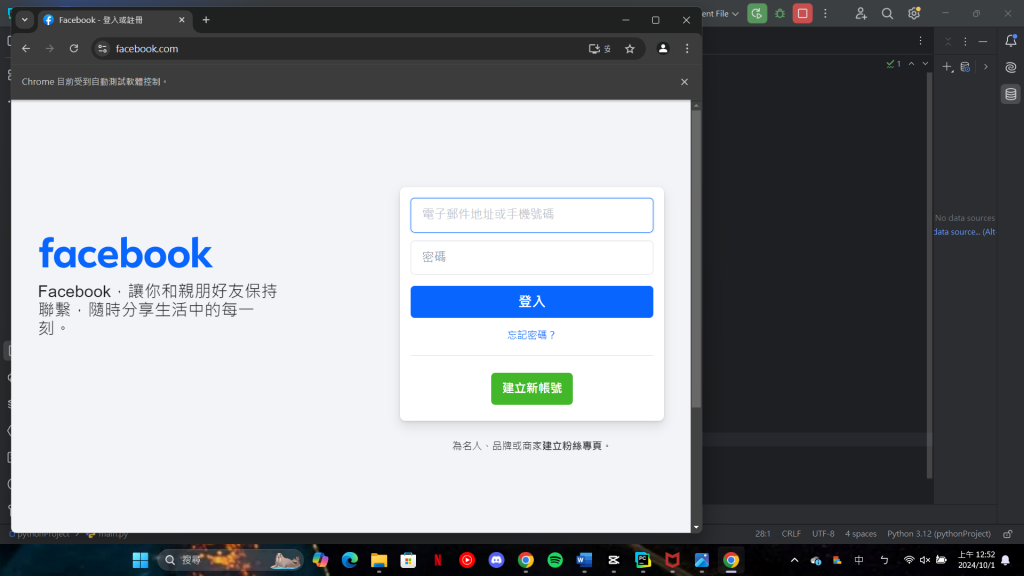
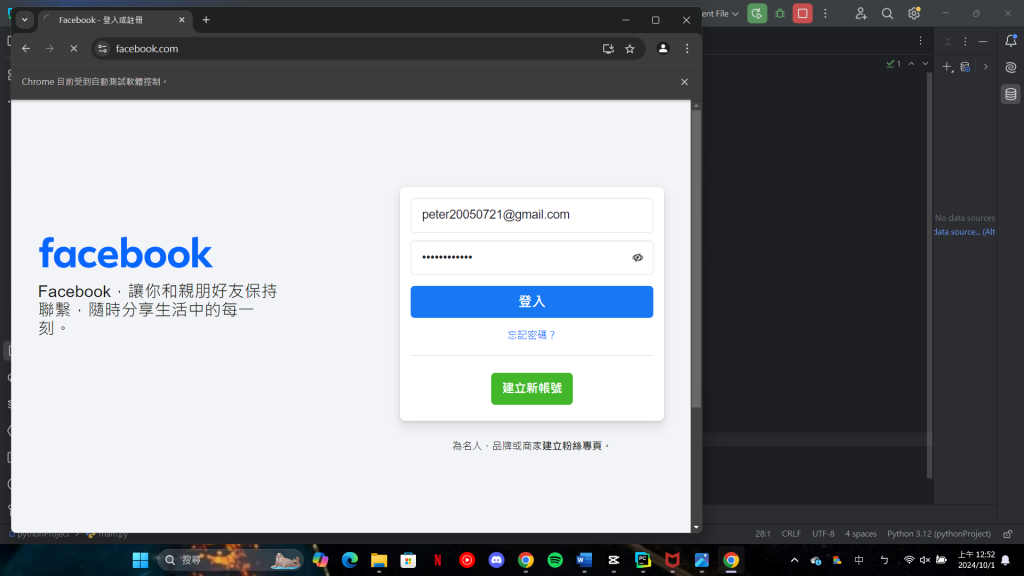
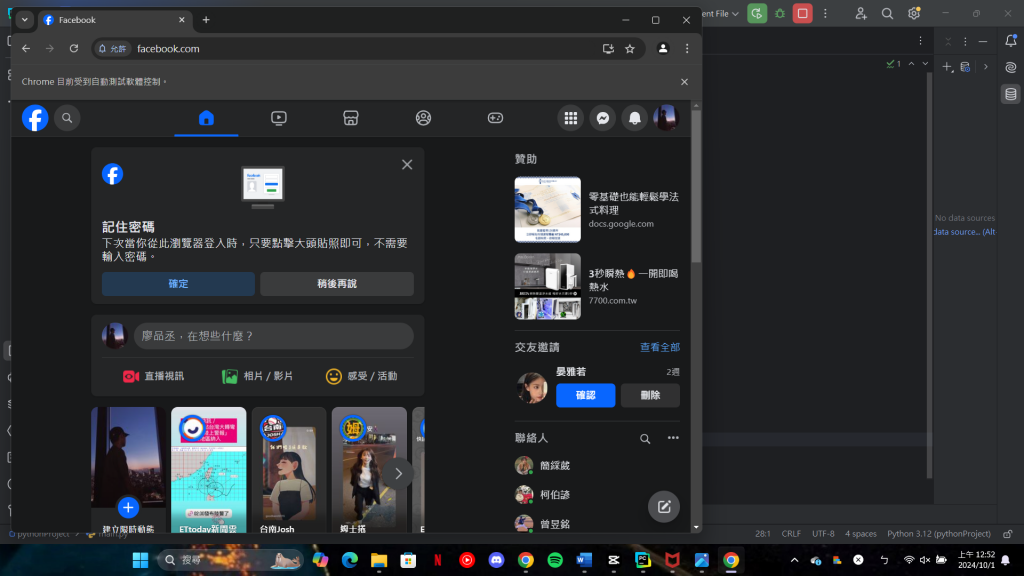
最後就可以在下方得到我們想要的結果,也就是自動登入自己的FB帳號。
(以上三張圖都是由系統自動進行的動作,並不是手動操作,但由於無法上傳影片,故改以截圖方式呈現。)
在這幾天的Selenium學習中,我對於相關的操作以及概念都有了一些進步,
其實之前我是完全不知道Selenium是什麼東西的,
但透過這次的學習,真的讓我發掘到了一個如此好用的程式,
甚至現在已經可以爬取想要的資料了,這絕對是我之前想都不敢想的事。
參考資料:
https://developer.mozilla.org/zh-CN/docs/Web/CSS/ID_selectors
https://medium.com/@kenAaa/%E5%AF%A6%E4%BD%9Cpython%E8%87%89%E6%9B%B8%E8%87%AA%E5%8B%95%E7%99%BB%E5%85%A5-c82c8f450f6e

