在今天的學習中,我們就要來學習另外一個爬蟲庫–BeautifulSoup。
在探討它要怎麼使用之前,我們理所當然的要先了解它是個什麼東西。
簡單來說,BeautifulSoup 就是一個用於
解析 HTML 和 XML 文件的 Python 庫,它非常廣泛的應用在網頁爬蟲中
來處理和解析網頁的結構。它可以將網頁的 HTML 或 XML 代碼
轉換為 Python 的對象,以此讓開發者可以輕鬆查找、提取和修改網頁中的數據。
那在知道它有什麼功用後,我們就先來做安裝的部分。
在這邊我們一樣要使用Win + R 快捷鍵開啟cmd (命令提示符窗口),
那跟Selenium的安裝很類似,
我們要輸入安裝指令pip install beautifulsoup4
然後我們再輸入確認的指令
-pip show beautifulsoup4 來確認有沒有正確安裝:
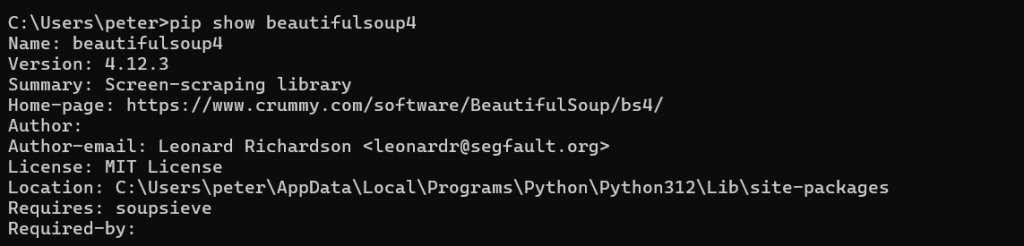
若是顯示的跟上方一樣,那就代表正確下載完畢了。
在設置完環境後,我們就來創立Beautiful的第一隻程式,
以下就按照我撰寫的步驟一步一步來學習研究:
我們這次的實作目標是要能夠「爬取電影評分前250名的電影」,
那我們這邊先來做第一步的撰寫:
(以下多數程式碼皆參考
https://www.youtube.com/watch?v=exttkF7niKU )
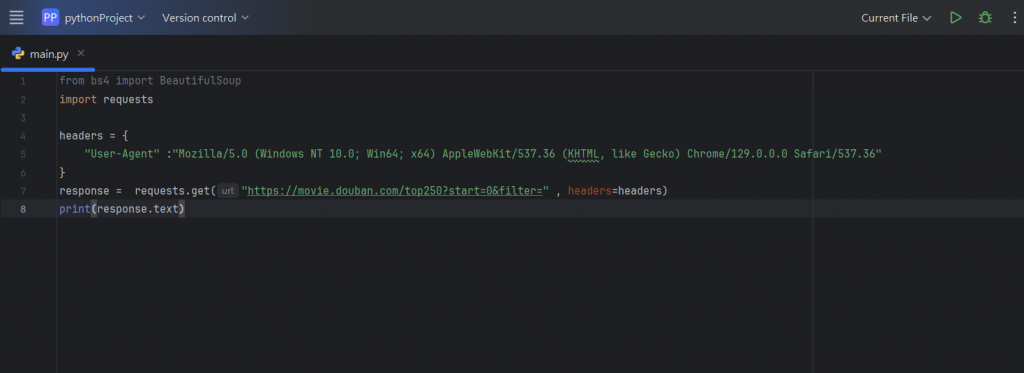
上方都是一些基本的前置作業,這邊就簡單挑幾行重要的出來講:
這個在前面之前有提過了,但我自己在做的時候也有點小忘記,
所以就再拿出來複習一下。
要獲取準確的user-agent,只要隨便找一個網頁,
然後滑鼠右鍵按下檢查,並選取Network選項選擇任一個元素,
並滑到最下方,就可以找到準確的User-Agent了。
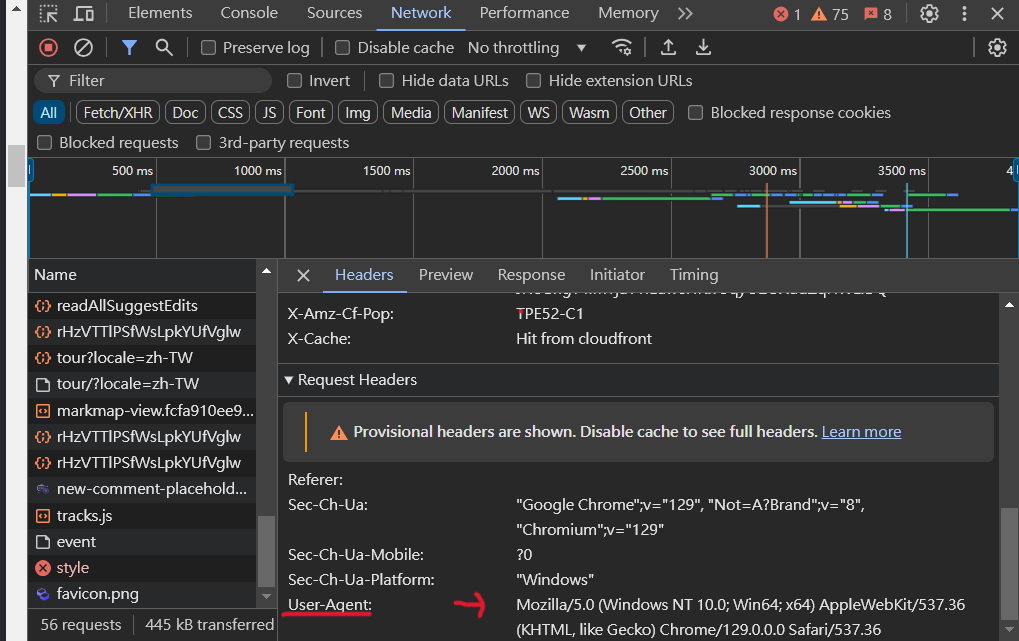
而透過上面的程式碼,我們就可以獲取目標網頁的HTML代碼了。
那理所當然,我們要從HTML中抓取想要的資訊,
而這次我們想抓取的是「電影名稱」,
我們就要先來看看HTML中是如何標示標題的:
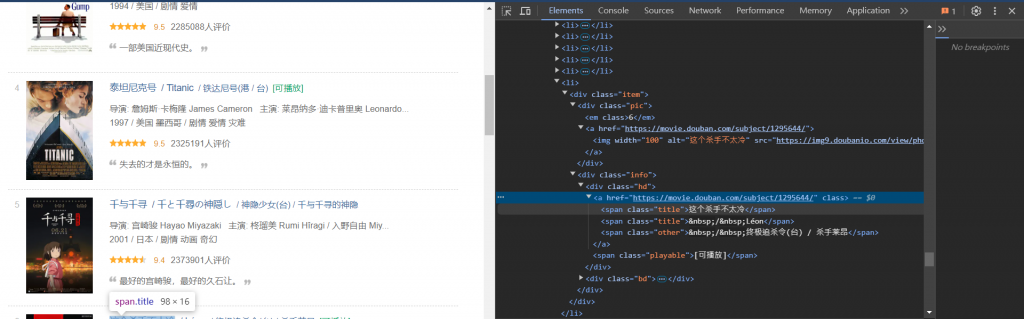
可以看到,他們都是一個span元素,而他們的class都是title,
所以我們就可以以此資訊來抓取我們要的資訊:
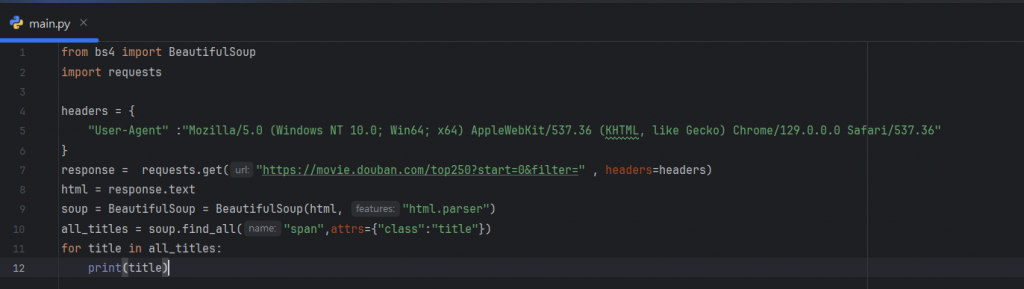
以下我們也針對幾行做詳細的解釋:
soup = BeautifulSoup(html, "html.parser"):
這邊使用 BeautifulSoup 來解析 HTML 內容,並且使用
內建的一個 HTML 解析器 html.parser,它的作用是可以原始 HTML 轉換成
可供操作的一個BeautifulSoup 物件。
all_titles = soup.find_all("span", attrs={"class": "title"}):
這邊則是使用另一個方法 - *find_all() *,來查找 HTML 裡所有符合條件的標籤,
這裡就是查找所有 span 標籤且其 class 屬性為 title 的元素,
這些元素包含了電影的標題,讓我們可以直接過濾出想要的內容。
那這邊顯示的結果如下:
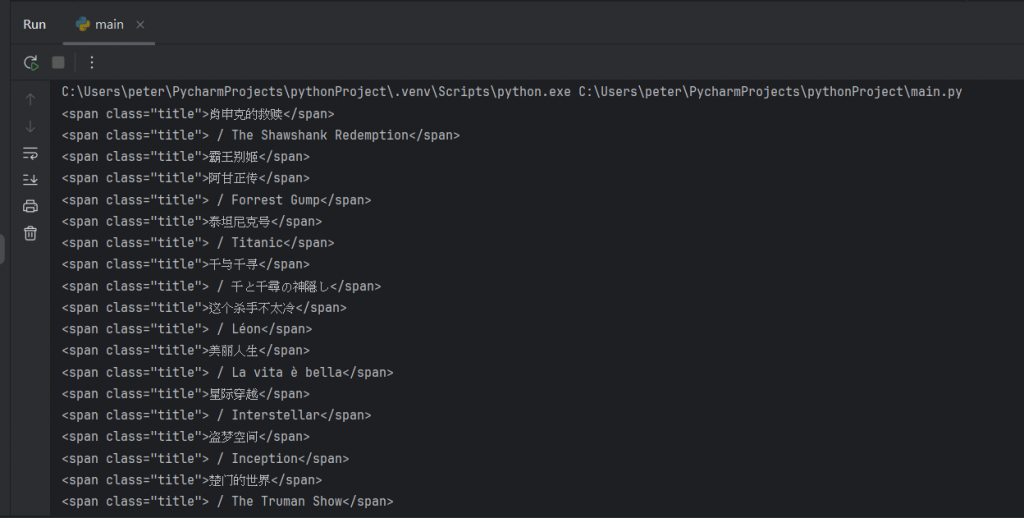
但我們可以發現,我們是抓出了電影名稱沒錯,但版面還是顯得有點雜亂,
我們應該要試著只呈現出電影名稱就好。所以我要再針對結果來做一次調整:
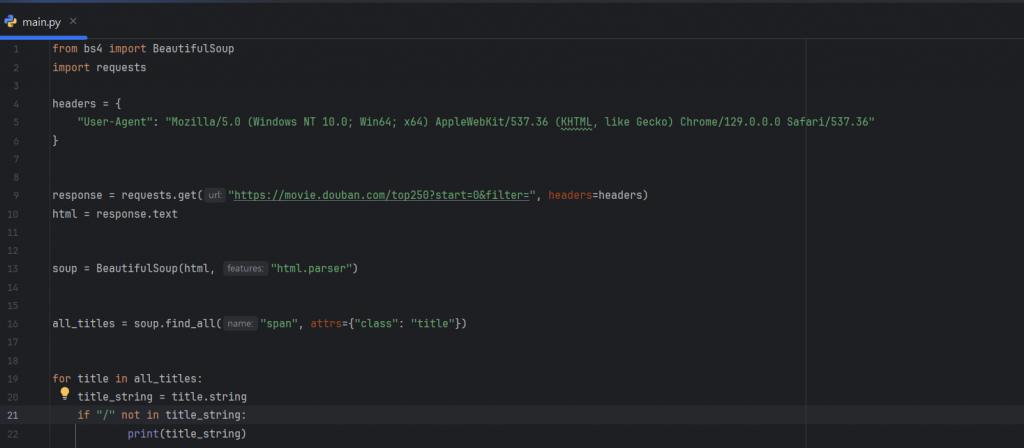
在上方新增的程式碼中,我們將具有 ”/” 的字串進行了過濾,
這樣就可以讓輸出結果只顯示電影標題,而結果如下:
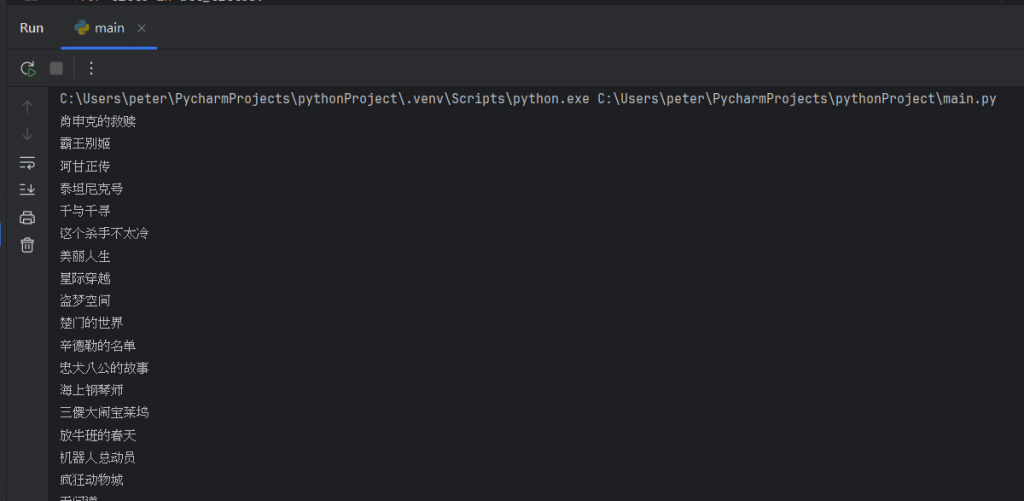
但這邊又發現了一個問題:這邊顯示的結果只有顯示1-25個,
而我們應該要一次爬取到250個的,
所以我們要多設定爬取範圍以及跳頁爬取的部分。
那以下是最後(真的是最後)的最終程式碼:
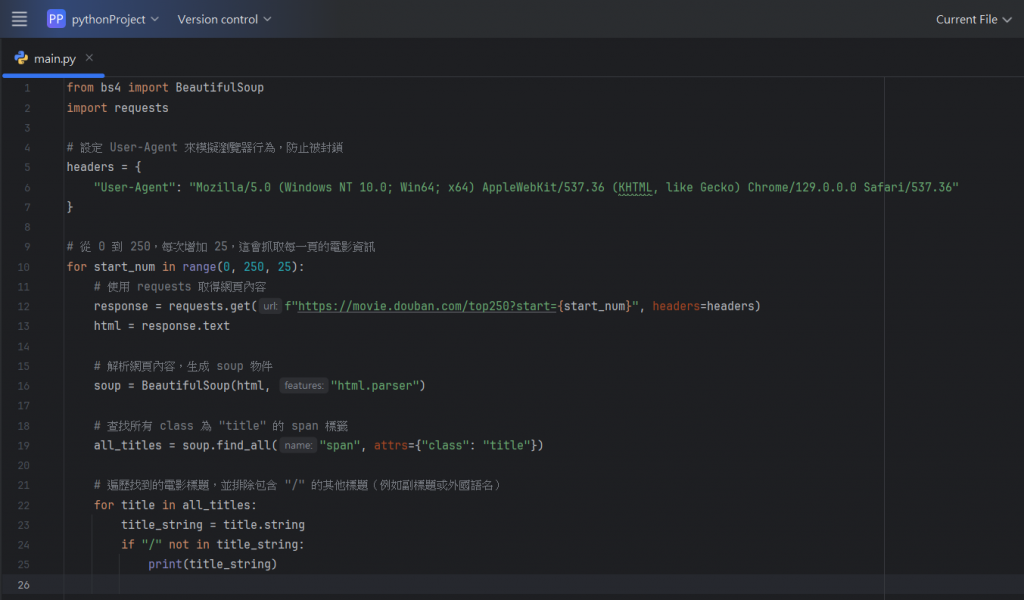
我們在上面新增了一個range的功能:
for start_num in range(0, 250, 25):
這邊就是使用 range() 生成一個數列,從 0 到 250,每次遞增 25,
這對應到不同頁面的 URL 參數 start,因為每頁顯示 25 部電影,
因此需要逐頁抓取不同部分的電影資訊。
那要怎麼設定跳選頁面呢?我們對網址的後面做了一些更改如下
(原本的網址為https://movie.douban.com/top250):
?start={start_num}:
? 後面是查詢參數的起始符號,start 是這個頁面的 URL 查詢參數。
{start_num}:
這則是 Python 的 f-string 語法,
表示會把 start_num 變數的值代入 start 參數的位置。
程式中的迴圈 for start_num in range(0, 250, 25)
會讓 start_num 依次取值 0, 25, 50, 75, ...,代表
抓取「Top 250」中各個頁面的電影。
如此爬取就不會只在一個特定網頁中,而是會根據寫的方式不斷進行跳轉。
最後就可以得到我們想要的最終結果:
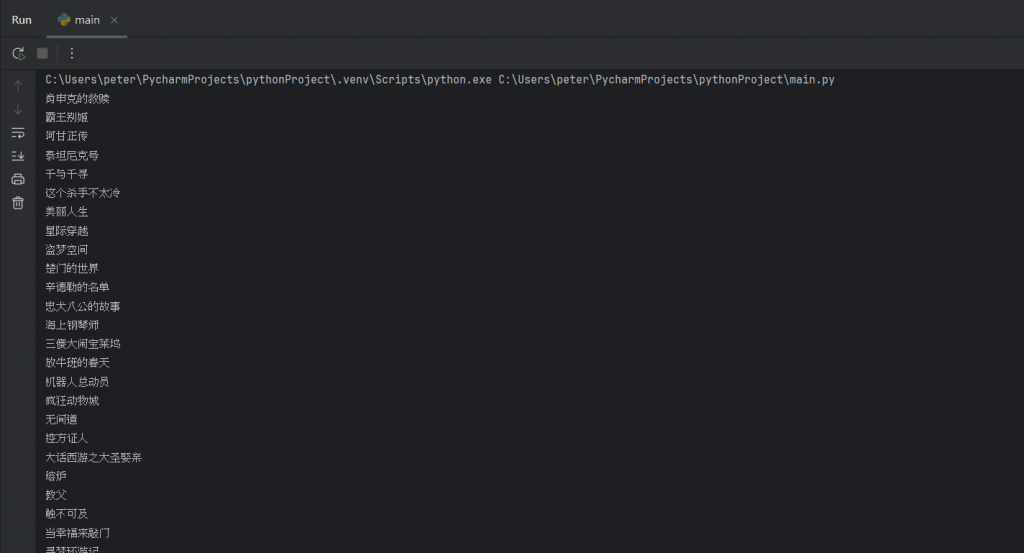
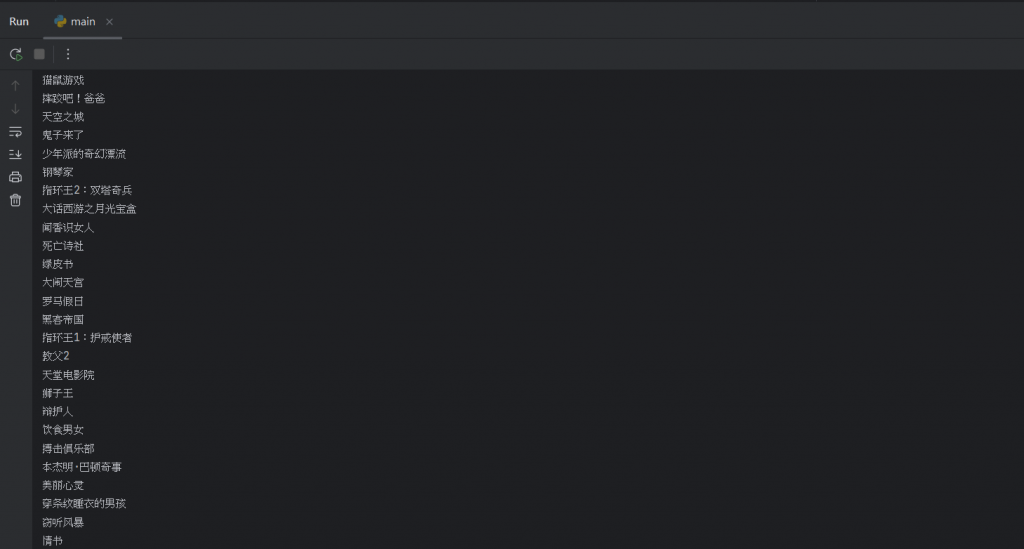
如此就真的只有剩下我們想要的電影名稱了,使用者就可以依自己的需求作尋找。
參考資料:
https://www.youtube.com/watch?v=exttkF7niKU
https://hackmd.io/@aaronlife/python-topic-beautifulsoup

