樣板方法提供一個演算法模板,讓子類別在相同的步驟中實踐不同的實作細節。
以料理為例,每道菜使用的食材、烹煮方式和擺盤風格各不相同,但都會經歷三個主要步驟:備料、烹調和擺盤。這三個步驟就像是製作料理的共通樣板,無論菜色如何改變,都離不開這些基本流程。我們可以利用這個樣板為每道菜設計食譜,確保每份食譜都提供其中的必要細節。
假設我們有一個文字轉換工具,讓使用者上傳不同格式的檔案,像是 PDF 和圖片,並將其中的文字內容轉換為純文字檔。每種檔案格式的讀取方式與文字提取方法都有所不同,然而整個轉換流程可以分為三個步驟:讀取檔案、提取文字內容以及儲存純文字檔。我們可以將這三個步驟定義為轉換流程的樣板方法,再根據不同的檔案格式實現相應的轉換細節。
定義文字轉換功能的基礎類別。extractText 方法是樣板方法,定義了轉換文字的標準步驟。loadFileContent 與 parseContent 則由具體類別根據不同的檔案格式決定具體的處理方式。
abstract class TextExtractor {
extractText(filepath: string) {
console.log(`\nStarting text extraction process for file '${filepath}'...`);
const fileContent = this.loadFileContent(filepath);
const textContent = this.parseContent(fileContent);
this.saveToFile(textContent);
return textContent;
}
protected abstract loadFileContent(filepath: string): any;
protected abstract parseContent(fileContent: any): string;
private saveToFile(content: string) {
console.log("Saving extracted text to a file...");
}
}
為不同的檔案格式定義具體的轉換類別。
class PDFTextExtractor extends TextExtractor {
protected loadFileContent(filepath: string) {
console.log(`Reading PDF from '${filepath}'...`);
return "PDF content";
}
protected parseContent(fileContent: any) {
console.log("Extract text content from PDF...");
return "text extracted from PDF";
}
}
class ImageTextExtractor extends TextExtractor {
protected loadFileContent(filepath: string) {
console.log(`Reading image from '${filepath}'...`);
return "image content";
}
protected parseContent(fileContent: any) {
console.log("Extract text content from image...");
return "text extracted from image";
}
}
測試轉換方法。
class TextExtractorTestDrive {
static main() {
const pdfTextExtractor = new PDFTextExtractor();
const imageTextExtractor = new ImageTextExtractor();
pdfTextExtractor.extractText("sample-document.pdf");
imageTextExtractor.extractText("sample-image.png");
}
}
TextExtractorTestDrive.main();
執行結果。
Starting text extraction process for file 'sample-document.pdf'...
Reading PDF from 'sample-document.pdf'...
Extracting text content from PDF...
Saving extracted text to a file...
Starting text extraction process for file 'sample-image.png'...
Reading image from 'sample-image.png'...
Extracting text content from image...
Saving extracted text to a file...
透過樣板方法模式,我們可以將文字轉換工具的轉換流程標準化,並根據不同檔案格式實現具體的處理邏輯。這樣的設計不僅能確保轉換流程的一致性,還具備良好的擴展性,未來我們只需新增新的轉換類別來支援其他格式,無需改動現有的流程架構。此外,如果需要調整轉換流程,我們只需修改樣板方法即可應用到所有子類別。
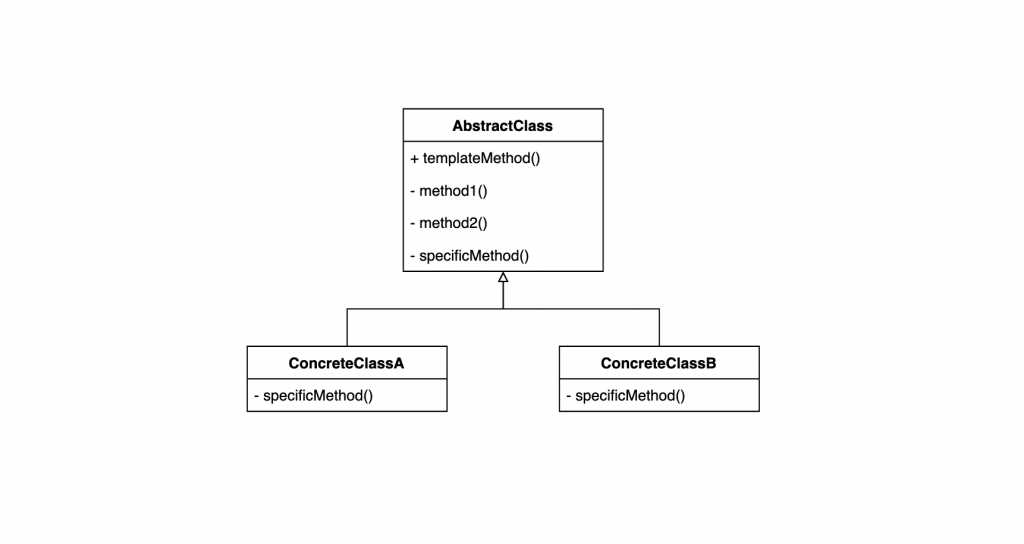
抽象類別確保所有的具體類別都遵循相同的步驟與程序,並提供通用的邏輯,以提升程式碼的重用性與一致性。子類別可以提供抽象方法或鉤子方法的具體實踐,以建立不同的演算法行為,進而滿足不同的使用情境。

