在 『optimizer I 』中有提到,使用 significant-text aggregation 來補全單詞是個取巧的做法,今天稍微解釋一下 significant-text aggregation 排序分數計算原理。
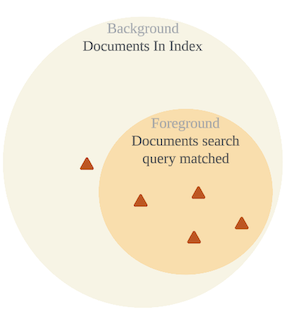
在 aggregation 之前後有一個 search query ,這個 search query 找到的資料稱為前景(foreground),在搜尋範圍內的稱為背景(background),所以 Foreground 是 Background 的子集合。
significant-text 會比較每個 token 在 foreground 和 background 的一個數值: 該 token 出現次數 / 總資料筆數 ,在 foreground 數值遠大於 background 的 token 容易被視為 significant text,下圖顯示了一個 significant-text 的可能情境:
在 background 中總共有 1000 筆資料,涵蓋 perfect 這個 token 的資料總共有 5 筆,但在 search query 找出的 10 筆資料中有 4 筆包含 perfect 這個 token,從 5/1000 到 4/10 有顯著的差異,顯示 perfect 這個詞對於目前這個 query 應該有些特別的意義,也可以避免單純使用詞頻計算而一直出現 we , they 這種高頻但對搜尋資訊沒有幫助的常用字。
並不是說這個算法有什麼問題,而是這個 aggregation 的設計跟現在的情境不太相符,現在的情境是把這個詞補完,也就是說我們還不知道使用者想要搜尋的目標。
另外是我們的取巧,會讓 es 做無用的功,當 search query 是 prefix,而 include 也只計算那些 prefix 的 token,等同於 background 是沒有意義的,我畫成下圖比較好理解。
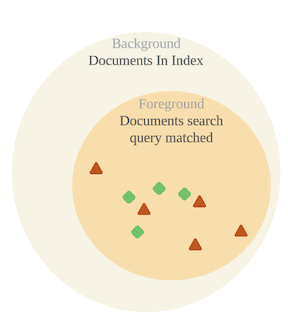
就一般情況,從現有數據發生頻率推測使用者行為才是比較合理的想法,也就是說,我們其實應該要從 token 的出現頻率去猜測使用者想輸入的 token。
既然如此,我們有辦法計算 token frequency 嗎?
在 ES 的工具裡面,可以透過 termvector api 來取得單筆資料內每一個 token 的詞頻以及這個 token 在幾筆資料中出現過(doc_freq),但沒有計算所有資料中以 prefix 篩選詞頻的工具。
在幾番搜尋後似乎只能透過 ES runtime field 加上自己寫 script 來完成這件事了,ES runtime field 是在 7.11 版推出的功能,功能是可以在 search 時新增 field,進行後續的搜尋或 aggregation。
計畫是這樣的:
實際的 query 如下:
GET covid19_tweets/_search
{ "query": {
"prefix": {"tweet": "cov"}
},
"runtime_mappings": {
"matched_term": {
"type": "keyword",
"script": {
"source": """
List matched_tweet = doc['tweet'];
for (String s : matched_tweet)
{
def m = /cov.*/.matcher(s);
if (m.find())
emit (m.group());
}
"""
}
}
},
"aggs": {
"nom": {
"terms": {
"field": "matched_term",
"size": 2
}
}
}
}
runtime_mapping 內的設定就是 runtime field 的內容, type 指定該 field 的 datatype,因為後續要進行 term aggregation,所以使用 keyword type,script 則是產生該欄位的邏輯,這裏寫的是:遍歷每一筆資料(doc)的 tweet field,使用 regex query 找出 prefix 為 cov 的 token。
因為要逐一處理每一筆資料,query 時間相對久(但比沒有 sampler 的 significant text 快了不少),在 aggregation 加上 sampler 試試看:
GET covid19_tweets/_search
{ "query": {
"prefix": {"tweet": "iso"}
},
"runtime_mappings": {
"matched_term": {
"type": "keyword",
"script": {
"source": """
List matched_tweet = doc['tweet'];
for (String s : matched_tweet)
{
def m = /iso.*/.matcher(s);
if (m.find())
emit (m.group());
}
"""
}
}
},
"aggregations": {
"my_sample": {
"sampler": {
"shard_size": 1000
},
"aggregations": {
"find_the_whole_token": {
"terms": {
"field": "matched_term",
"size": 2
}
}
}
}
}
}
確實比較快了(大概在 25~35 毫秒左右),算是可以接受。
雖然 query 長得越來越複雜了, 但感覺越來越接近理想的狀態了 : )


 iThome鐵人賽
iThome鐵人賽