在今天的學習中,我會試著抓取有使用「Ajax」的網頁的資料,
並且最後將抓取到的資料存取到EXCEL中。
(參考來源:
https://www.youtube.com/watch?v=1PHp1prsxIM)
AJAX,簡單來說就是讓網頁在不刷新整個頁面的情況下,能動態更新部分內容的技術。
它的全名是「Asynchronous JavaScript and XML」,但其實現在大家更多用 JSON,
而不是 XML 來傳輸數據,因為 JSON 更輕便、簡單。
AJAX 的核心就是「非同步」,意思是當你點擊網頁上的某個按鈕或者進行某些操作時,
網頁背後會偷偷地向伺服器發送請求,獲取一些數據回來,然後直接更新你看到的那部分內容,
而不用整個頁面刷新。這樣,使用者感覺到的就是頁面反應很快,體驗更加流暢。
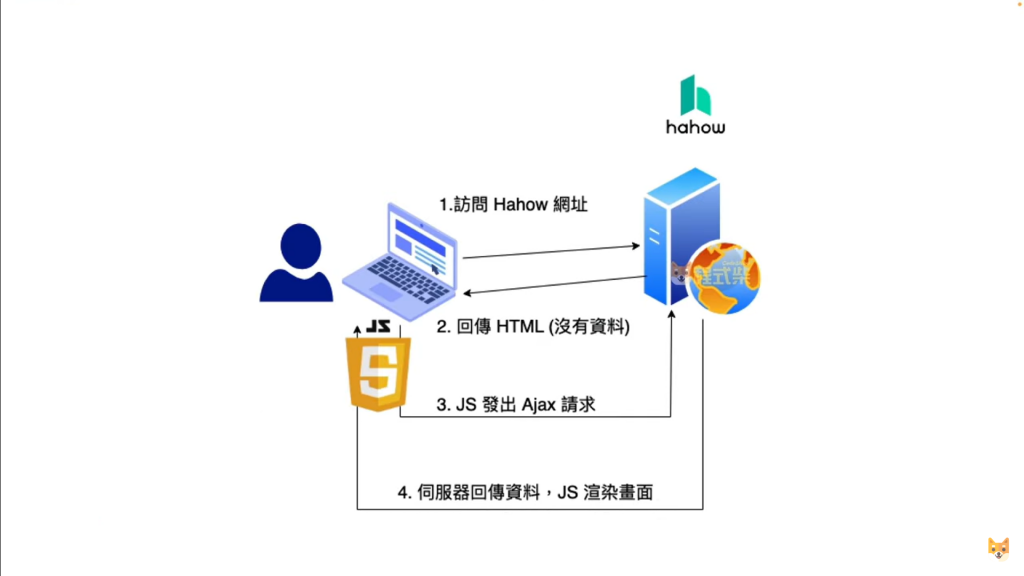
那它背後是怎麼運作呢?
首先,網頁還是照常用 HTML 和 CSS 來排版和設計。
當你觸發了某個事件,比如點擊按鈕,JavaScript 就會啟動,
利用 XMLHttpRequest 或現在更流行的 Fetch API,向伺服器發送請求。
伺服器收到請求後處理完數據,再把結果發回來。
這時候,JavaScript 就會把這些數據塞進網頁的某個部分,
你就能在畫面上看到變化了。
(圖片來源:
https://www.youtube.com/watch?v=1PHp1prsxIM)
非同步的好處是,網頁不會卡住等待伺服器回應,
其他操作還是能正常進行,讓整體的體驗更加順暢。
這樣你在看網頁的時候,可能一邊輸入東西、一邊瀏覽,
結果頁面裡的數據就自動更新了,根本感覺不到有等待時間。
最常見的 AJAX 應用包括像 Google 搜尋建議,
你在輸入框裡打字,結果會自動出現一些相關建議;
還有像社群網站的無限滾動,當你滑到底時,更多內容會自動加載出來,
不用再手動點擊下一頁。
這些功能都是靠 AJAX 來實現的。
總之,AJAX 改變了網頁的互動方式,讓我們可以更快速、流暢地跟網站互動,
不用每次操作都等整個頁面刷新,也讓現代網頁應用變得更靈活和高效。
接著,我們就進行到實作的環節。
我們今天要抓取的網站名稱是「Hahow」:
會選擇該網頁的主要原因主要是它有使用Ajax技術,
比較方便我們拿來當作範例。
那我們的目標就是要爬取上面可以看到的熱門影音課程,
裡面的標題、課程價格等資訊,
並把它彙整到Excel裡面做統整。
那首先,我們一樣先檢查網頁的原始碼(F12開啟):
點選Network中的「Fetch/XHR」
以此來看看伺服器是怎麼獲取資料的:
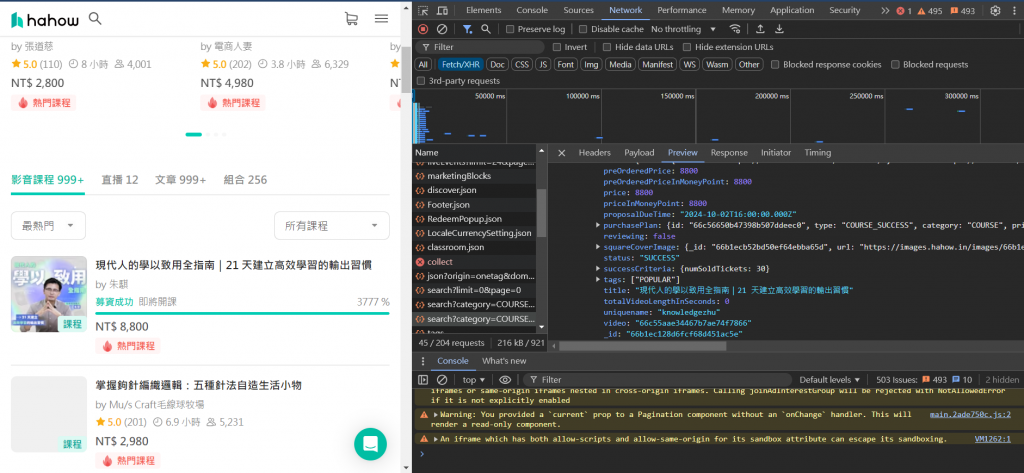
我們點選右邊的「Preview」,在這邊就可以看到構成該網頁的各個API,
我們就要在這個裡面找出我們想要抓取的部分。
這邊就是一個一個找,直到找到我們想要的資料。
接著,在找到我們想要的API後,我們要進行接下來的動作:
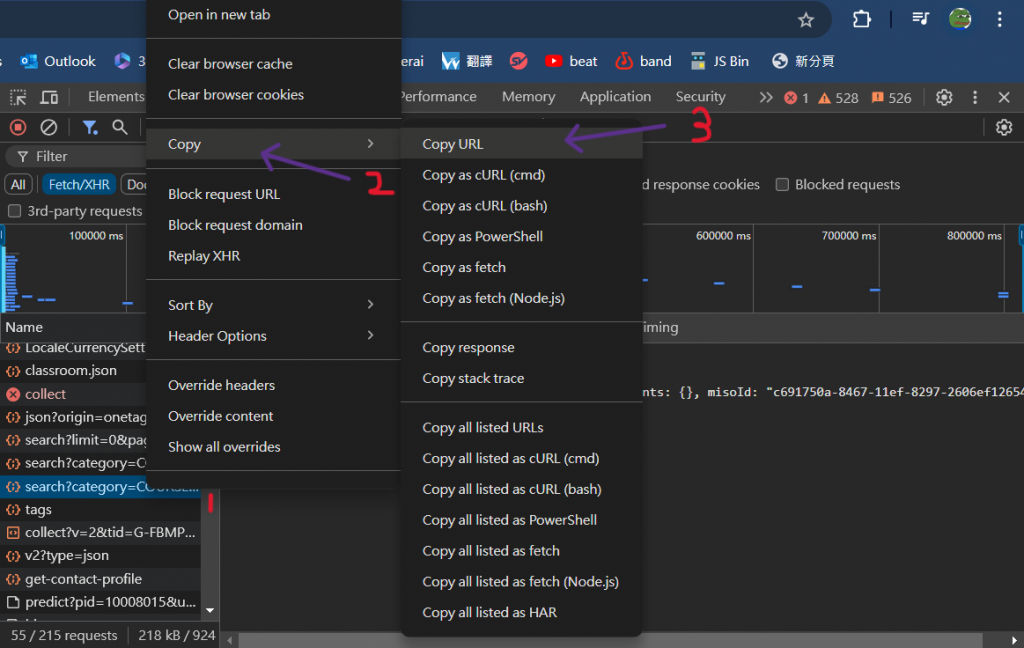
(1)滑鼠點選API右鍵 (2)點選複製 (3)點選複製網址(URL)
再來,我們把複製的網頁放到一個新的頁面進行查詢,就會得到以下的畫面:
上面是一個很亂的JSON編碼,應該是沒什麼人看得懂...,
所以我們要按下左上角的「美化排版」:
如此就可以讓我們比較方便的抓取出資料了。
接著我們就直接進入到python的編譯器中來撰寫程式:
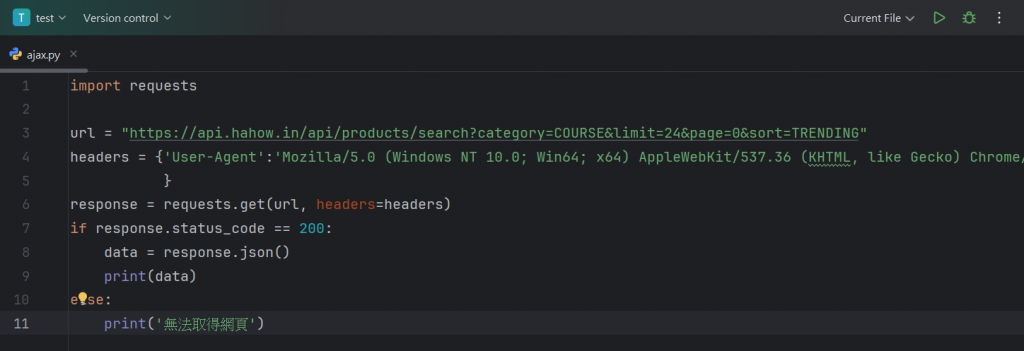
這邊就是進行第一步的設置,引進requests並設置模擬請求頭(前面都講爛了),
另外在下面設置一個for迴圈,讓我們可以確認有沒有正確的引進資料。
執行後的結果如下:
上面看到的很多像是data、courseData,就是我們資料的小標題,
我們可以把他帶入程式碼看看:
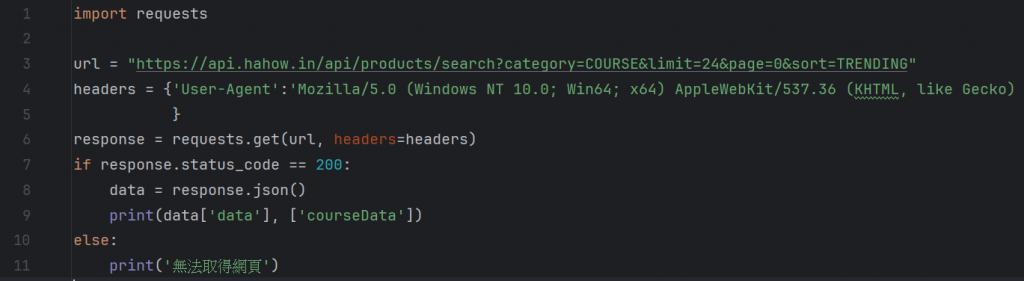

可以看到,如此我們就獲得了小標題內的資料了。
那因為我們是要抓取實際的像是課程資料、價錢等等的資訊,
所以我們還要在JSON中找到專門管理那一欄的屬性。
那回到JSON編碼中:
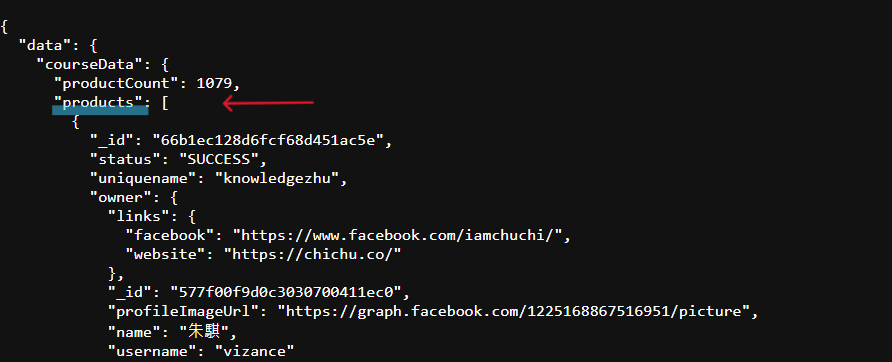

我們從上面的兩欄找到了他的實際管理欄位以及最內部的標題區域,
接著就是把他們引進:
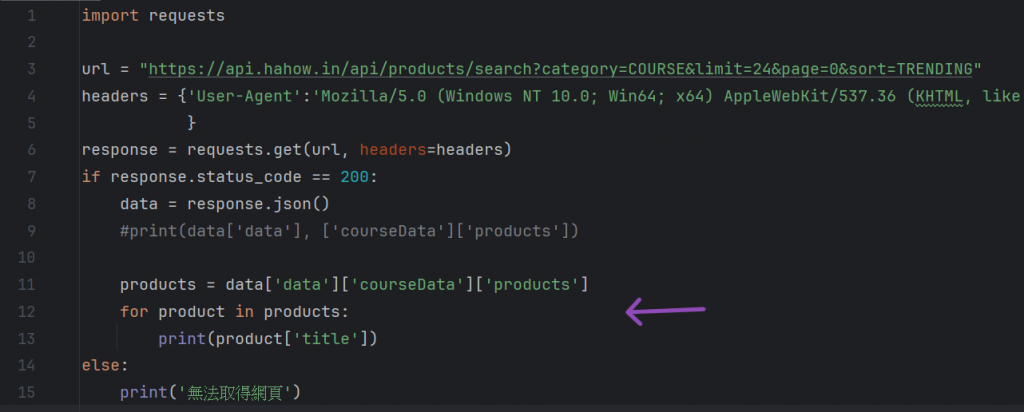
我們把剛剛搜尋到的欄位加入了進去,並設立一個for迴圈讓程式可以不斷執行,
最後把title這個屬性印出來,結果如下: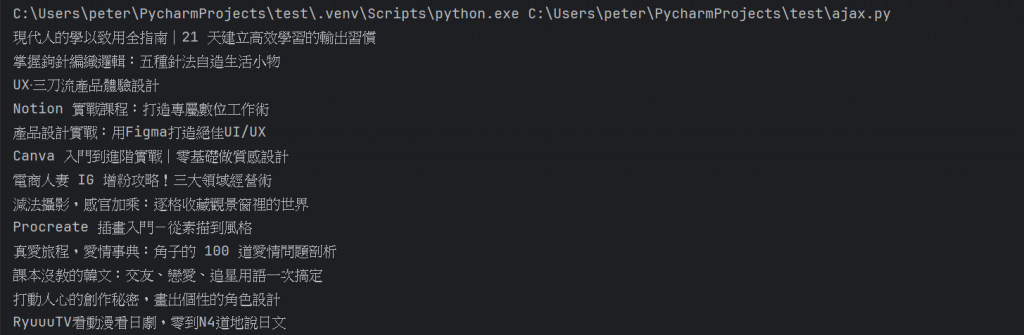
如此我們就抓取到了所有的標題了。
再來,因為其他元素的加入方式也都大同小異,這邊就直接先省略,
我們就直接進到將檔案儲存成Excel的部分:
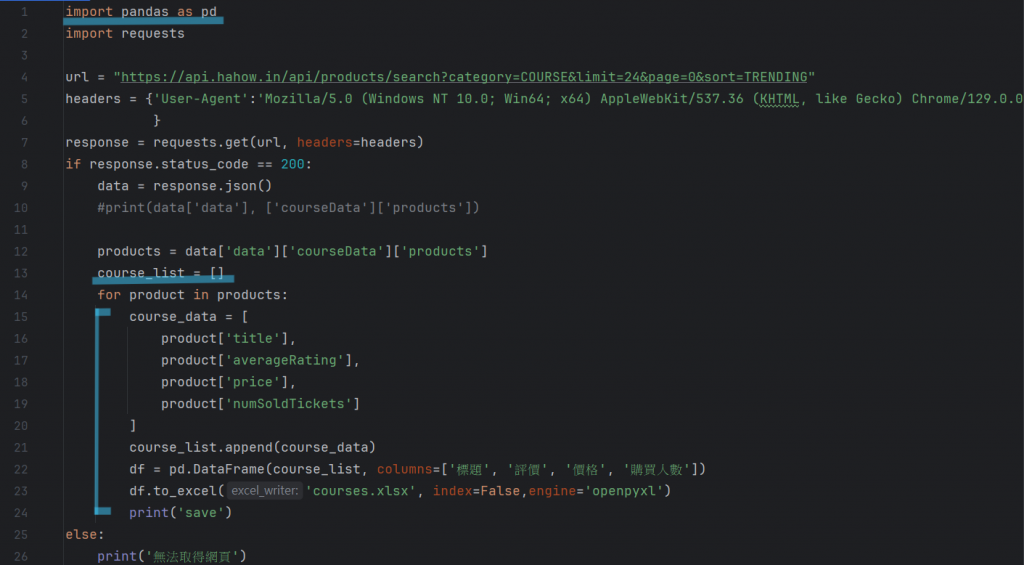
將檔案儲存都會進行類似的流程:
(1)引進pandas庫
(2)新增data列表
(3)新增元素
(4)用dataframe設定後面要輸出的格式
(5)將index設為false(讓預設的索引值消失)
(6)設定讀取和寫入 Excel 文件的 Python 庫 - openpyxl
但要記得要安裝openpyxl這個python庫,不然系統會顯示錯誤。
(親身經歷)
在執行後,我們就可以看到右邊新增了一個檔案,
我們點擊滑鼠右鍵,然後按 Open in ---> Explorer
我們就可以在資料夾中看到一個新的Excel檔案了:
我們將它打開,看看裡面的成果: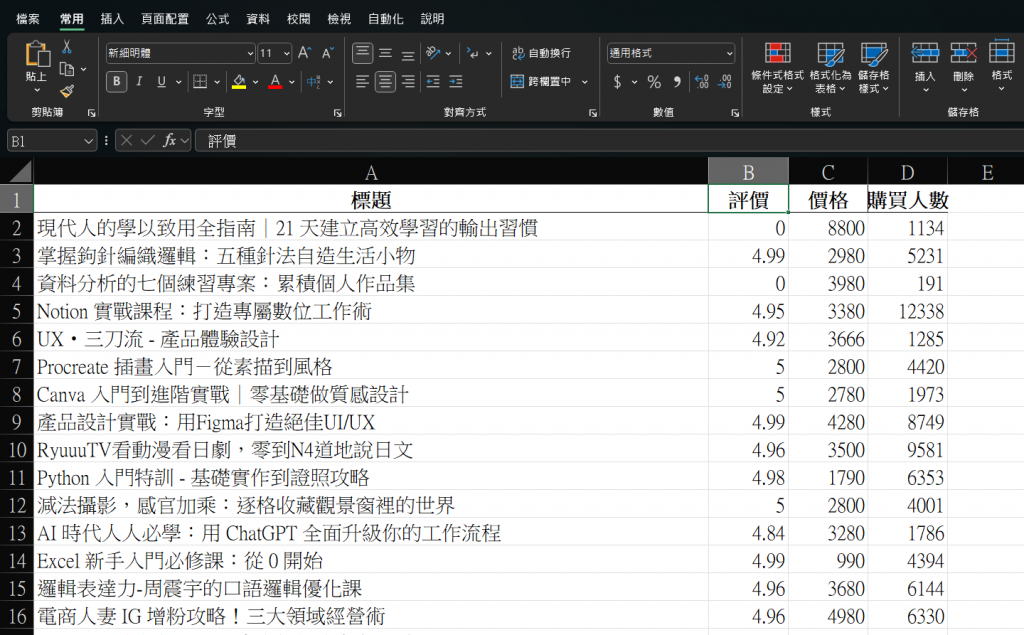
如此就獲得了一個漂亮的表格了!!!
參考資料:
https://tw.alphacamp.co/blog/ajax-asynchronous-request

