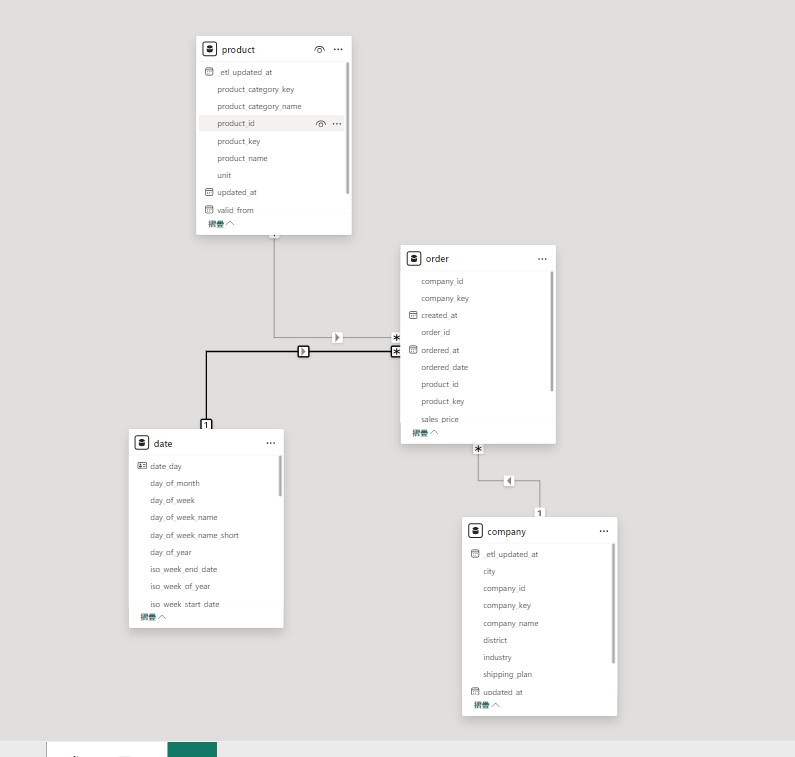
下面的圖是目前的資料模型,跟上一篇最後的資料模型相比,只改變了表格名稱 (e.g. dbt dim_company → company)。
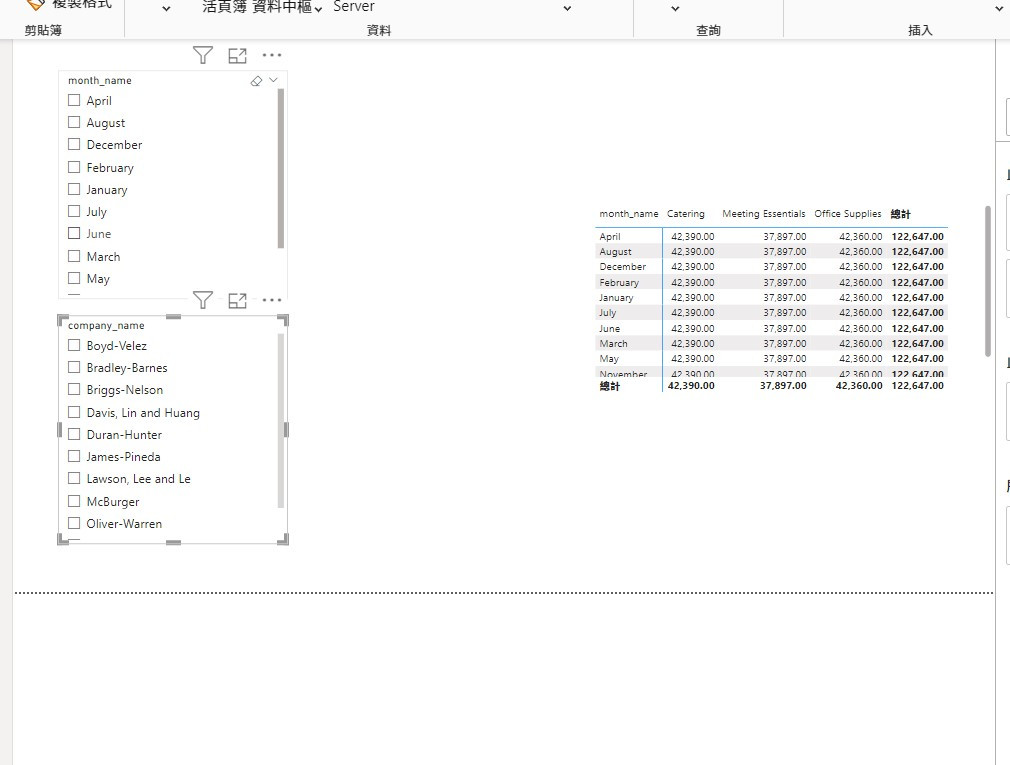
在介紹 Power BI 的「關聯性」有哪些種類前,想先介紹一下「關聯性」對圖表 (Visualization)的影響。這邊先簡單定義一個 DAX: Sales Revenue = SUM(orders[sales_amount])。接著做出一個月份跟產品種類的樞紐分析表,如下圖:
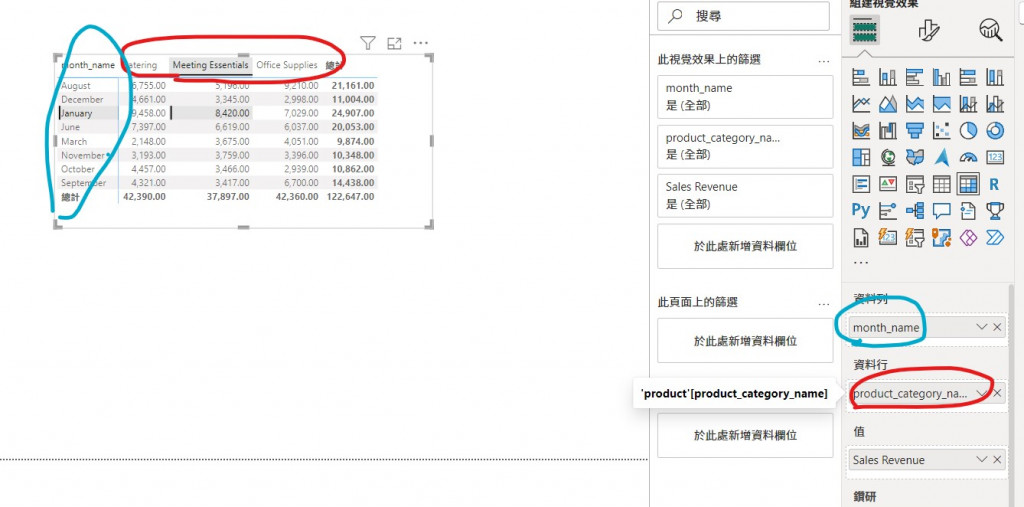
這張樞紐分表欄用的是 product 這張表的 product_category_name ,列用的是 date 的 month_name ,因此可以把它想成,表格中的每個數字,都是透過資料模型的關聯性做篩選計算出來,如下圖所示:
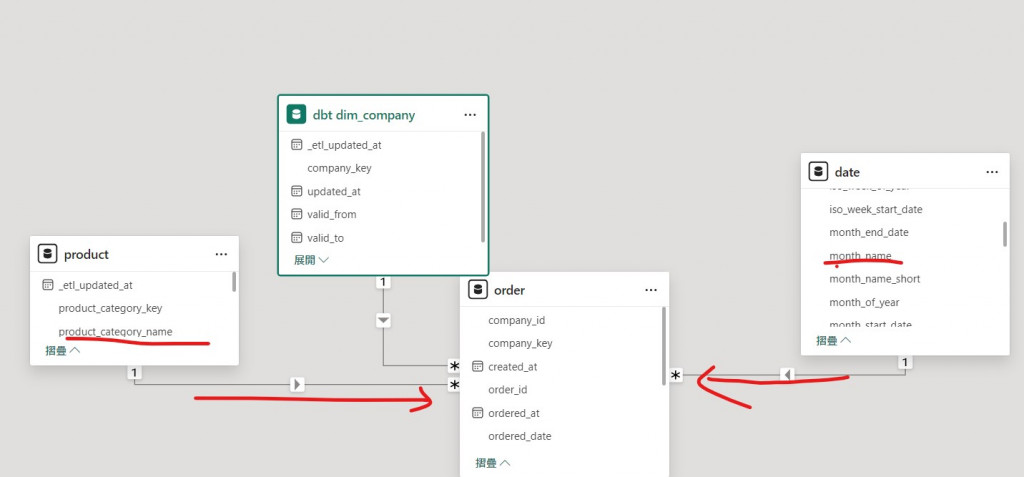
所以可以把 Power BI 語意模型的關聯性想像成爪子,維度表會利用這個爪子從事實表抓出適當的列作運算。
這其實也代表 DAX 的計算規則,事實上會被關聯性影響。比方說,我將 date 這張表格跟 order 這張表格的關聯性刪除, SUM(orders[sales_amount]) 的計算方式就會跟之前不同,得到的樞紐分析表也不同,下面是移除關聯性後的資料模型以及樞紐分析表:
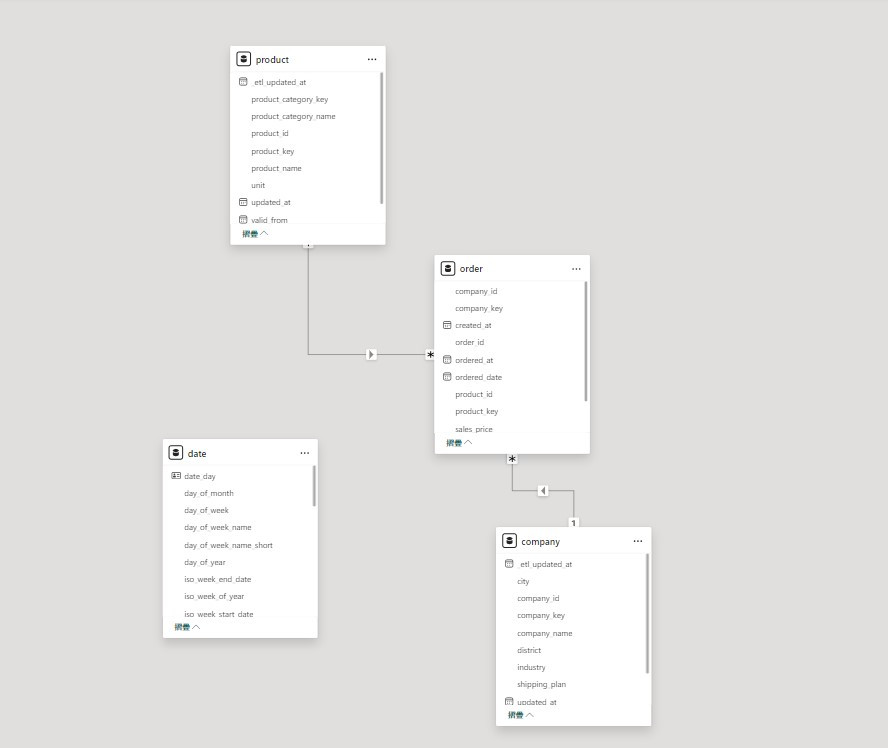
所以要讓 DAX 計算後的結果跟預期是一樣的,如何在資料模型中建立清晰的關聯性就相當重要。
Power BI 的關聯性大慨從幾個角度去分類:表格與表格間的對應關係、方向性以及是否為預設關聯
單向:
雙向:
關聯性影響。因此 DAX 其實也提供在計算時再打開雙向的功能,不如等雙向時再使用 (i.e. CROSSFILTER()函數)。建立 Power BI 的資料模型時,應該盡可能讓方向性只能從一指向多。
多數關聯性為預設關聯,但當兩張表格間可以有兩種關聯時,也是在 Day 12 中談到的角色維度表。可以看到下圖從 date 到 order 有兩個關聯性 (因為有訂單日跟到貨日),其中虛線代表非預設關聯。
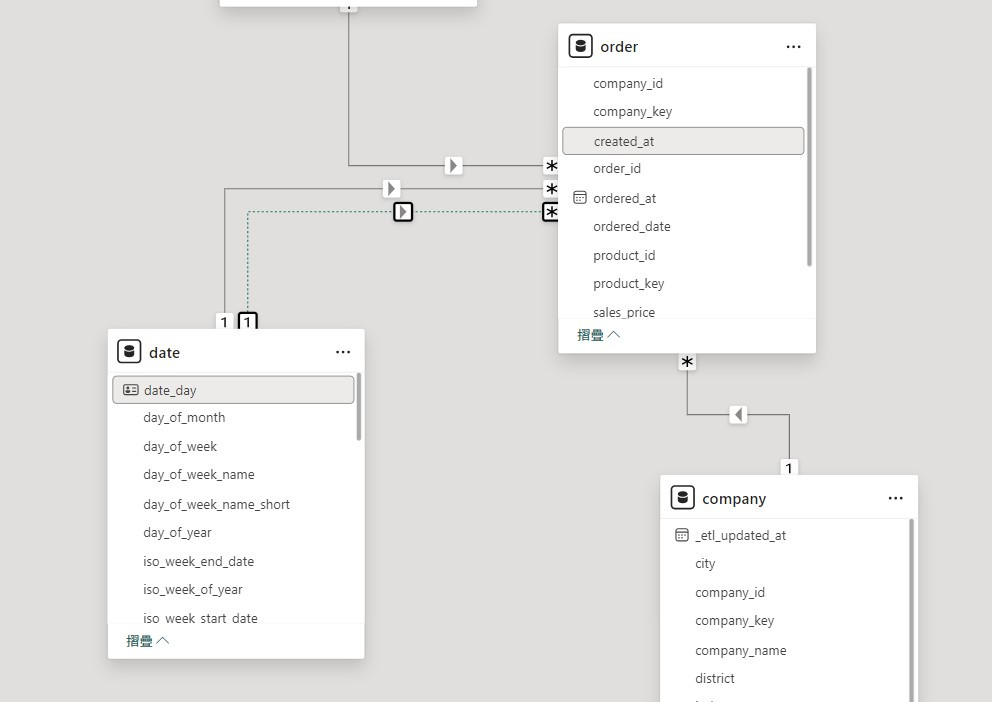
DAX在計算時除非使用 USERELATIONSHIP 這個函數,否則非預設關聯會被忽略,只使用預設關聯。
因為關聯性具有篩選的性質,也可以透過新增 RLS (Row Level Security)用職員表去保障資料安全。比方說 某一 Product Category 的產品應該就只有該 Category Manager 以及其下屬 可以看到業績。一樣可以在資料倉儲建立好一張 RLS 用的表格後,匯入 Power BI 。欄位大概如下,其中 employee_email 可以用來被 Power BI 作為身份驗證的工具:
| employee_email | product_category_id |
|---|
之後這張表要跟 product 建立關聯。這時這張表跟 product 就無法避免多對多關係,但因為他只有篩選的功能,也只跟 product 有關聯,因此可以將指標算錯的風險降到最低。

