一、前言及目標
學習如何使用生成式AI生成醫療文本的簡短摘要。
實作調用預訓練的語言模型來自動生成摘要,提升醫療文本處理效率。
二、程式碼與結果

三、嘗試
中間其實不停修改程式,最後才有了上面這個版本,輸出我想要的內容。以下是錯誤的結果: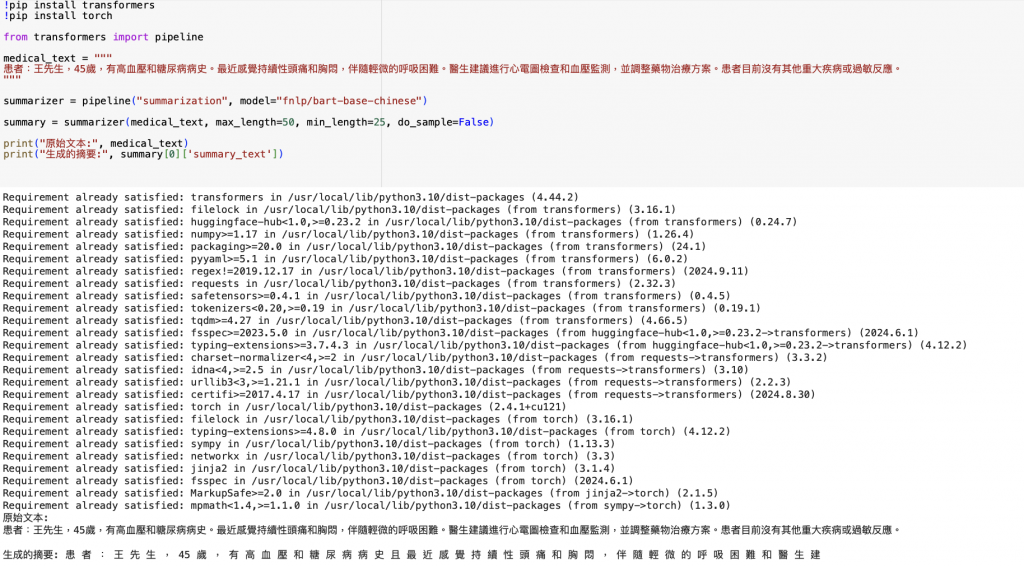
句子沒頭沒尾,且字與字的間距有問題。
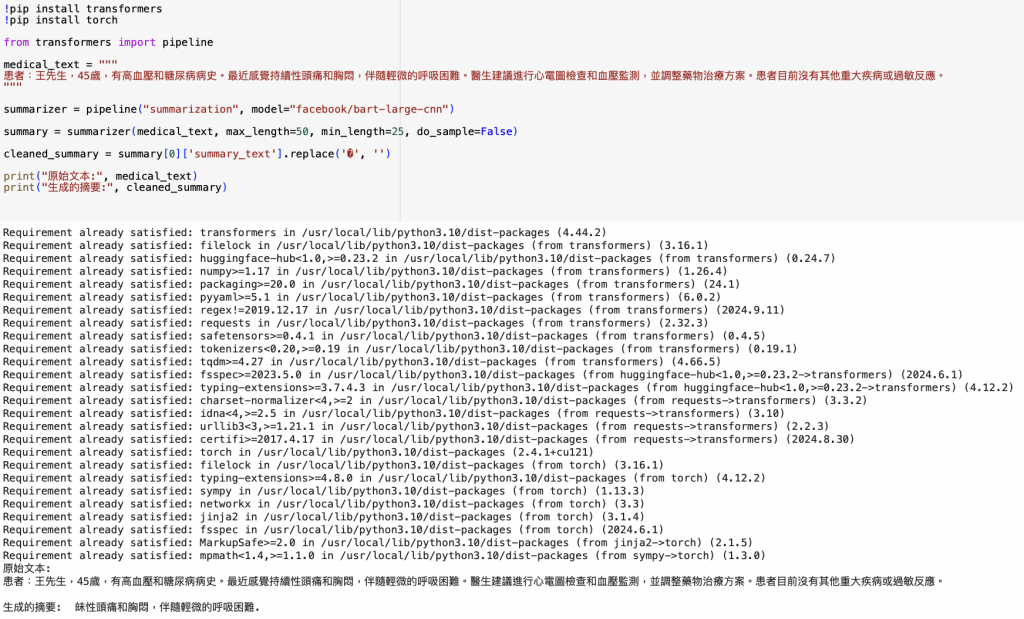
內容有錯字也太簡短不符合我的預期。
總之就在不停修改程式碼,針對問題去解決,才有了「二」的結果。
四、分析
max_length=100:將最大長度調整為100,這樣模型有足夠的空間生成完整的句子,避免截斷。
清理空格:cleaned_summary = summary[0]['summary_text'].replace(' ', '') 用於移除每個中文字之間的多餘空格,這應該能夠解決字之間被拆開的問題。
中文模型:繼續使用 fnlp/bart-base-chinese 來處理中文文本,以確保生成結果更適合中文語境。
五、小結反思
今天的實作內容是醫療文本的摘要生成。通過嘗試不同的模型與參數設定,最終選擇了適合中文文本的BART模型來生成摘要。因為一開始程式其實問題滿多的,結果根本不符合預期,所以有請chatGPT做修改,算是一起齊心完成最終版。我的內容當然只是簡單整理摘要,如果這種技術用在長篇且大量的文本一定可以很省時間,不僅僅是在醫療方面,各個面向都會很實用。


 iThome鐵人賽
iThome鐵人賽