
今天要介紹 Client Side Rendering 的運作流程、優缺點與改善方式。
以 React 來說明運作流程如下。
index.html,接著會將這個 build 好的 index.html 部署到伺服器上以讓客戶端存取
<!DOCTYPE html>
<html lang="en-US">
<body>
<div id="root"></div>
<script src="./bundle.js"></script>
</body>
</html>
index.html
bundle.js 內的 JavaScript 程式碼<div id="root"></div> 這個容器中,並針對 DOM 元素綁定事件處理器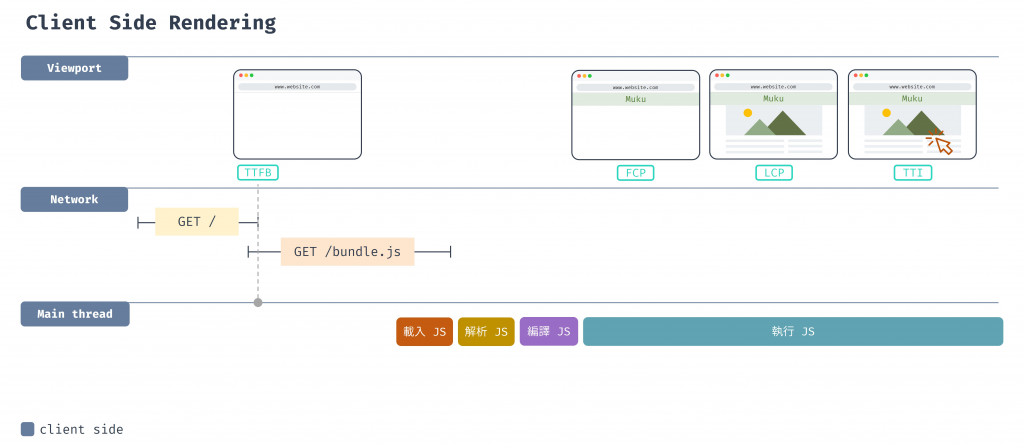
圖 1 CSR 流程示意圖(資料來源:自行繪製)
可看出在 Client Side Rendering 中,使用者一開始只會拿到一個基礎、只有一個空的 div 容器的 HTML,頁面上顯示內容所需的邏輯、請求資料、渲染 DOM 元素和路由導航都是由在瀏覽器/客戶端中執行的 JavaScript 程式碼來處理的。
CSR 的運作方式讓建構單頁應用程式(Single-Page Applications, SPA)變得十分流行,讓網頁和手機應用程式 App 之間的界線變得模糊。
補充一下,什麼是 SPA 呢?SPA 是一種網頁應用的架構,此架構應用程式的所有內容都會在同一個頁面中呈現(使用同一個 HTML 檔案),舉例來說,Gmail 就是一種 SPA 的應用,使用者可在同個頁面中查看不同信件、回覆、編輯和送出信件,這些操作都不需刷新或重新整理整個頁面。當使用者查看一封新信件時,應用程式只需動態載入和顯示此信件需要的新數據,而非重新載入整個新頁面。
SPA 之所以成功是因為前端技術的演進,例如可使用 AJAX 動態載入資料,又或是 React 應用程式可搭配 React Router 這類前端路由工具,在不重新載入整個頁面的情況下,在應用程式內部轉導頁面、並動態更改顯示的內容。
另外,Huli 在這篇文章中有提了 SPA 從何時開始流行的一些歷史脈絡,有興趣的讀者可再去閱讀~
SPA 可提供更流暢、快速的網頁體驗,因為它不會因為換頁或使用者操作(如:搜尋框篩選、送出表單)而重新載入整個頁面,讓網站看起來更像一個原生的 APP,進而提升使用者體驗。
當使用者切換不同頁面時不需再向伺服器請求,在客戶端處理 UI 和資料邏輯更快。但要補充的是,相對其他渲染模式(如:SSR),使用者不一定會更快看到資料,因為 CSR 還是需要透過 API 去取得資料,但是以使用者的角度來說,整個應用會「看起來」更快回應請求,好像我一切換頁面,網頁應用就立刻有反應了,就算我只是先看到 loading 畫面,但有立即回饋對使用者體驗就會比較好。
在 CSR 架構下的 SPA 應用程式中,前端主要負責頁面渲染和互動,後端則負責提供數據和 API,職責區分較明確。如果不使用 SPA 架構,而是使用傳統的多頁面架構(如:/about 路由建一個 about.html 檔案,/product 路由建一個 product.html 檔案),當使用者請求新頁面時,後端要回傳完整的、包含資料與畫面的頁面,如此前後端的任務會較難分離。因此 SPA 這種分離方式相較於傳統方式,可讓前後端開發和維護更獨立,明確分工讓開發更有效率。
如果用了 CSR,因為畫面都是後續由 JavaScript 產生,搜尋引擎只會爬到一個空的 HTML。雖然現在的搜尋引擎可執行 JavaScript,也能解析 CSR 網站了,但很難確定爬蟲執行 JavaScript 後拿到的結果是自己想要的,有可能 API 回應速度太慢,導致有意義的內容無無法更快地被渲染,例如如果抓取資料的 API 要兩秒以後才會 response,但搜尋引擎執行 JavaScript 以後只等一秒就當作最終結果,那結果畫面還是不會有資料,爬蟲仍然無法索引,還是有可能會影響 SEO。
社群平台會以 <meta> 標籤來知道這個網頁的標題、描述和預覽圖,但如果在客戶端產生 <meta> 標籤是沒用的,因為通常社群平台的 bot 不會執行 JavaScript,所以 CSR 頁面的 <meta> 只會有一個,無法根據不同頁面動態決定內容。
因為 JavaScript 都在客戶端裝置上執行,雖然現在裝置的運算速度都很快,但也可能遇到裝置比較老舊、JavaScript bundle 大小過大而讓程式碼執行較慢的狀況,使用者就需要等一段時間才能讓 JavaScript 執行完並看到畫面。在程式碼拆分的文章中有分析使用者要看到畫面前,要先經過載入、解析、編譯和執行 JavaScript 的階段,當 JavaScript 檔案越大,使用者就需要等待越久,中間等待時間只會看到白畫面(或是 loading 提示),使用者體驗就會不好,延後了 FCP、LCP 和 TTI 的時間。
某些商業邏輯可能會被分開放在客戶端和伺服器端,但這些邏輯可能是重複的,例如貨幣、日期欄位的驗證與格式化的邏輯。
另外,因為 CSR 的關係,許多邏輯都會放在前端處理,前端的程式碼會變得更複雜。舉例來說,以前只要根據請求的路由,伺服器就會回傳對應的 HTML 檔案,並渲染出不同的資料與畫面,但現在 CSR 只有一個 HTML 檔案,前端程式碼要自己判斷現在的網址是什麼,才能決定在前端應該渲染出哪個畫面,並且也要自己控制資料的狀態、非同步請求的邏輯等,前端程式碼變複雜後相對來說也會較難維護(當然現在也有很多函式庫、第三方工具可以輔助開發)。
針對上述缺點,有幾個可改善的方向:
會有 SEO 和社群平台 link preview 問題,主要是因為 CSR 只會先回傳一個空的 HTML 檔案,因此改善方向就是讓這個 HTML 檔案有內容、可以被爬蟲爬取。
server 可以在收到請求時判斷,如果請求來自於搜尋引擎或社群平台的 bot 時,就回傳一個準備好、填滿資料內容的 HTML 檔案。不過還是有缺點,因為專門給搜尋引擎和 bot 看的網頁會和一般使用者看到的不太一樣,且其實 Google 並不建議此種作法,這種針對 Google bot 回傳特殊頁面被視為反面模式(anti-pattern),稱為 cloaking。
可先在 server 端用 puppeteer 這類工具開啟網頁頁面,然後執行 JavaScript 得到網頁的資料內容,將完成後的頁面保存成 HTML,搜尋引擎和 bot 請求時,就回傳這個 HTML。如此可確保這個 HTML 和使用者看到的畫面一樣。pre-render 的熱門框架如 Prerender。
但此方式若要實作,會有許多細節要注意,相對前一種方法複雜很多。
因為我沒實際實作過,如果有興趣了解的可以看看這裡有 Huli 大大的實作和實驗結果。
補充:puppeteer
puppeteer 是由 Google 開發的 Node.js 函式庫,提供 API 以進行網頁測試、螢幕截圖和網頁爬蟲等應用,但僅限於使用 Chromium 瀏覽器引擎的瀏覽器,例如:Google Chrome 或 Microsoft Edge。
Vercel 在這篇文章有指出,Google 的搜尋引擎還是會下載與執行 JavaScript 的,但是搜尋引擎會為網站分配爬蟲的成本,所以如果 JavaScript 的檔案太大,花太多成本執行,可能會讓爬蟲的成本花完後,某些頁面仍沒被執行到 JavaScript 而影響 SEO,因此針對 SEO 的改善方向還有一點,就是盡量減少 JavaScript 的檔案大小。
在 Huli 的文章中還有提到兩個改善 SEO 的方式,分別是「在 server render client app」和「在 build time 就做 render」,這和後面文章要提到的 SSR 和 SSG 相關,會在後面繼續說明。
會有效能以及使用者體驗(需等待較久)的問題,主要是因為 JavaScript 檔案太大了,以及需要等待 API 請求回來的結果,因此會針對這個來做改善。這些方法在之前的文章都有介紹過,就不再細部展開。
確保初始頁面載入的 JavaScript 檔案容量足夠小,可以盡量壓縮(minified)檔案,並且只放入初始頁面需要的 JavaScript 即可,其他初始頁面不需要的,可以之後需要時再載入。
以 preload 關鍵字來告訴瀏覽器預先載入關鍵資源。
拆分 JavaScript bundle,將單一一個檔案拆分為多個,在初始頁面時載入必須的 bundle,之後在需要的路由或使用者行為觸發時再動態載入,程式碼拆分也因而能實現 JavaScript 的延遲載入。
在需要的時候才載入資源,延後載入那些非必要的資源以提升載入速度。例如在初始頁面載入時不會立即可見的元件,就可採用延遲載入。
可用 Service Worker 將基本的頁面框架以及需要經常存取的資源做快取,減少網路往返的次數,能更快取得資料並顯示。
CSR 可以實現 SPA 流暢的使用者體驗,尤其適合處理大量動態資料的應用。但這種模式也存在一些缺點,雖然已有一些改善方式試圖解決這些問題,但這些方法仍然有其侷限性,無法徹底解決。因此才會衍生出其他的渲染模式,這部分會在後續文章繼續介紹。

