Pod 是 k8s 中最重要的資源之一,今天就來看看 pod 的生命週期吧!
簡單描述 pod 的生命週期:
補充:當 pods 短時間內一直啟動失敗時,常會看見 **
CrashLoopBackOff的狀態,**但其實這並不是一種 pods 的生命週期,並且隨著失敗的次數變多,嘗試重啟的間隔也會越來越長。
當 pods 為 running 狀態時,kubelet 可以重啟 containers,並且會追蹤各種 container 的狀態來看如何讓有異常的 pods 恢復正常
k8s 有自己定義的 pods 狀態,若 APP 有特殊需求,也可以定義 APP 何為健康 (使用 Pod readiness,下面會提到)
同個 pods 的 lifetime 是只能被調度一次。每一個 pods 都有一個唯一的 uid (metadata.uid),因此即使有兩個相同 name 的 Pods,uid 也會不同。
也就是說,重新調度的行為其實是透過刪除/新建 pod 完成的。
與 pods lifetime 相同的還有 volume (有唯一的 uid,重新掛載代表重建一個)
比如掛載在同個 Pods 裡面的 emptyDir,也是使用這個機制去處理 pods 重建的
container 即為 pods 裡面真正執行的 process,有三種狀態:
Waiting:等待開啟,常見的例子就是正在拉取 container imageRunning:正常運行,若是有設定 postStart hook 的話,Running 的 container 即代表已經通過此 hookTerminated:container 被關閉或是工作完成,當 container 為此狀態時,可以透過 kubectl describe 檢查到 reason 與 exit code,方便診斷原因prestop hook,則會在 Terminated 前完成在 pods 有個欄位為 restartPolicy (預設為 Always),可以決定當 pods 掛掉時,會怎麼處理內部的 containers
有以下幾個步驟:
Initial crash:k8s 會根據 restartPolicy 定義立刻重啟。Repeated crashes:當 initial crash 短時間內太多次,將會把重啟時間拉長,以避免系統負荷過重CrashLoopBackOff state:代表已經套用延遲時間重啟,間隔會越來越長 (以指數型成長,10s → 20s → 40s,最長到 5 分鐘)Backoff reset:當 container 已經正常運作一段時間 (e.g. 10 分鐘),則重啟間隔時間就會被重置。常見的 CrashLoopBackOff 原因有以下:
基於以上五點,排查的思路也有五點:
kubectl logs <name-of-pods>
kubectl describe pods <name-of-pods> 查看 event,或許可以看到一些提示。pods 的預設 restartPolicy 為 Always,該值會直接帶入 pods 內的 “正規” container 內 (除了 initcontainer 與 Sidecar container 會忽略 pod-level 的 restartPolicy 設定)
對應的三種設定為:
在 pods 建立之後,會有五個布林值分別代表 pods 目前的狀態:
PodScheduled: pods 已經成功被排程到某個 nodePodReadyToStartContainers: (beta feature; enabled by default) pods 已經準備好建立 container (應該是指 pause container 已經準備好,也就是 k8s 內負責設定網路/PID 的 pause container)ContainersReady:pods 內的所有 container 都是 Ready 狀態Initialized: 所有 init conatiners 都正常完成了Ready: Pods 已經準備好接受從 service 來的流量 (若沒有設定 readniness probe,則 pods 一進入 running 狀態就會開始接收流量)補充:這五點的其中兩點
ContainersReady與Ready蠻容易混淆的,筆者是以Ready代表整個 pods 都啟動完畢來記,而Containers Ready則是 pods 內的 containers 都 Ready
其實我覺得… 似乎差不多?
這幾個欄位都可以透過 kubectl describe 指令查看,若是使用 kubectl get -o yaml 的話,則會是在最下面 status 的部分以 array 的方式呈現。
比如執行:
kubectl describe po -n kube-system etcd-k8s-master1
kubectl get po -n kube-system etcd-k8s-master1 -o yaml
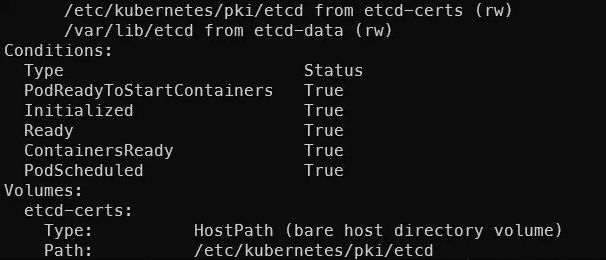
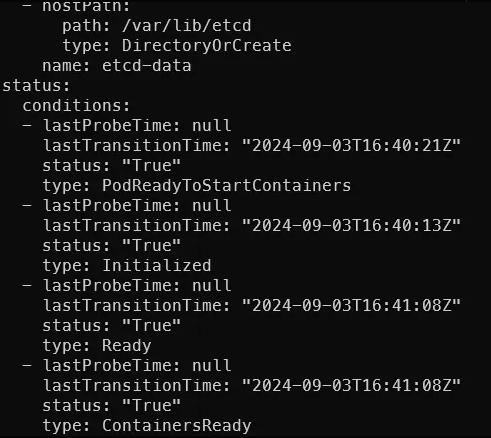
在 status 欄位還可以看到最後檢查時間,若失敗還會有 reason, message 等欄位提供管理者閱讀。
今天就先到這邊,明天再來看看比較重要的 Probe 如何設定
在平常操作 k8s 時,完全理解 pods Lifecycle 或許幫助不大,但當 Pods 出狀況時,就會必須要知道這些可能會出現的訊息,才有辦法快速的修復服務。
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle

