from ultralytics import YOLO
import os
os.chdir(os.path.dirname(os.path.abspath(__file__)))
model = YOLO("./Weights/yolov8n.pt", task="detect")
result = model.predict("./Image/bus.jpg", save=True)
model = YOLO("./Weights/yolov8n.engine", task="detect")
result = model.predict("./Image/bus.jpg", save=True)
yolov8
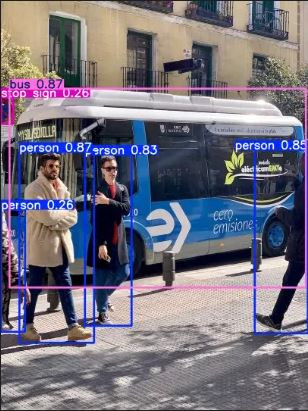
image 1/1 d:\05.Python\yolov8_tensorRT\Image\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 44.9ms
Speed: 2.0ms preprocess, 44.9ms inference, 53.4ms postprocess per image at shape (1, 3, 640, 480)
yolov8 + tensorRT
Loading Weights\yolov8n.engine for TensorRT inference...
[11/09/2024-18:59:07] [TRT] [I] Loaded engine size: 9 MiB
[11/09/2024-18:59:07] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +12, now: CPU 0, GPU 18
(MiB)
WARNING ⚠️ Metadata not found for 'model=./Weights/yolov8n.engine'
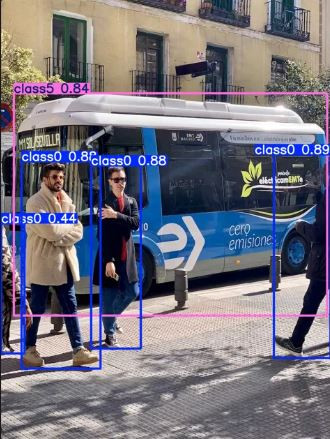
image 1/1 d:\05.Python\yolov8_tensorRT\Image\bus.jpg: 640x640 4 class0s, 1 class5, 2.0ms
Speed: 2.0ms preprocess, 2.0ms inference, 1.0ms postprocess per image at shape (1, 3, 640, 640)
from ultralytics import YOLO
import os
os.chdir(os.path.dirname(os.path.abspath(__file__)))
print("pt to engine fp32:\n")
model = YOLO("./Weights/yolov8n_fp32.engine", task="detect")
result = model.predict("./Image/bus.jpg", save=True)
print("pt to engine fp16:\n")
model = YOLO("./Weights/yolov8n_fp16.engine", task="detect")
result = model.predict("./Image/bus.jpg", save=True)
print("pt to engine int8:\n")
model = YOLO("./Weights/yolov8n_int8.engine", task="detect")
result = model.predict("./Image/bus.jpg", save=True)
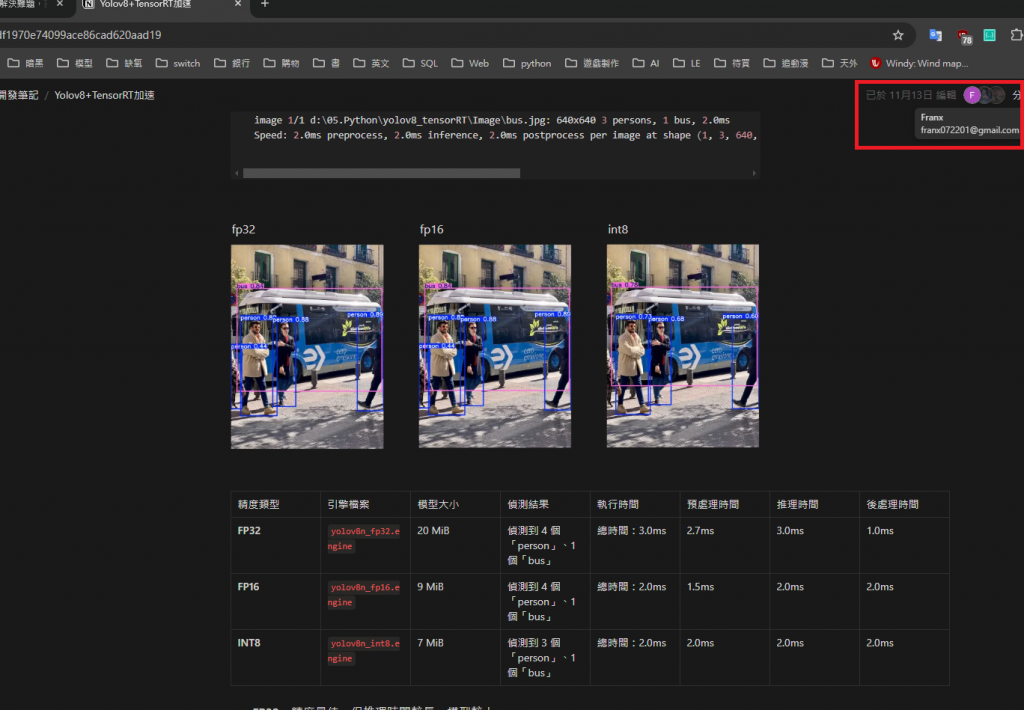
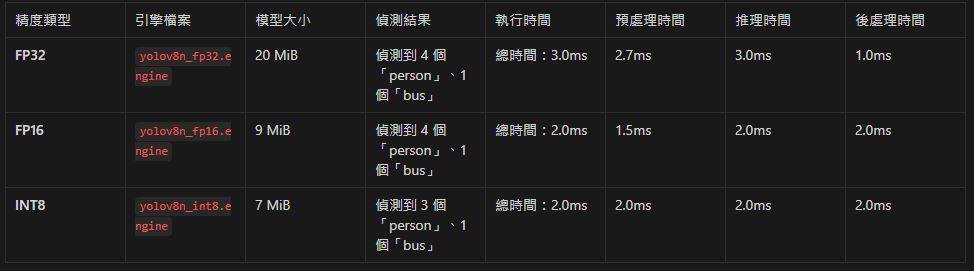
pt to engine fp32:
Loading Weights\yolov8n_fp32.engine for TensorRT inference...
[11/09/2024-21:22:58] [TRT] [I] Loaded engine size: 20 MiB
[11/09/2024-21:22:58] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +18, now: CPU 0, GPU 34 (MiB)
image 1/1 d:\05.Python\yolov8_tensorRT\Image\bus.jpg: 640x640 4 persons, 1 bus, 3.0ms
Speed: 2.7ms preprocess, 3.0ms inference, 1.0ms postprocess per image at shape (1, 3, 640, 640)
pt to engine fp16:
Loading Weights\yolov8n_fp16.engine for TensorRT inference...
[11/09/2024-21:22:58] [TRT] [I] The logger passed into createInferRuntime differs
from one already provided for an existing builder, runtime, or refitter. Uses of the global logger, returned by nvinfer1::getLogger(), will return the existing value.
[11/09/2024-21:22:58] [TRT] [I] Loaded engine size: 9 MiB
[11/09/2024-21:22:58] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +1, GPU +13, now: CPU 1, GPU 54 (MiB)
image 1/1 d:\05.Python\yolov8_tensorRT\Image\bus.jpg: 640x640 4 persons, 1 bus, 2.0ms
Speed: 1.5ms preprocess, 2.0ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
pt to engine int8:
Loading Weights\yolov8n_int8.engine for TensorRT inference...
[11/09/2024-21:22:58] [TRT] [I] The logger passed into createInferRuntime differs from one a
one already provided for an existing builder, runtime, or refitter. Uses of the global ogrre
logger, returned by nvinfer1::getLogger(), will return the existing value.
[11/09/2024-21:22:58] [TRT] [I] Loaded engine size: 7 MiB
[11/09/2024-21:22:58] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionCoionContext creation: CPU +0, GPU +2500, now: CPU 1, GPU 2557 (MiB)
image 1/1 d:\05.Python\yolov8_tensorRT\Image\bus.jpg: 640x640 3 persons, 1 bus, 2.0ms
Speed: 2.0ms preprocess, 2.0ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640, 640)

參考文件:
nvidia: https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#python_topics
ultralytics: https://docs.ultralytics.com/integrations/tensorrt/#usage
 franx0722
franx0722