在機器學習的資料預處理階段,若遇到極度不平衡資料 (如金融詐騙、醫學疾病、特定事件...) 我們經常需要進行特徵縮放和不平衡資料處理,但我們應該先做哪一個? 這兩個步驟的先後順序一直是個充滿爭議的話題,我在許多論壇看到各種說法。有人認為應該先進行特徵縮,也有人主張先處理不平衡問題才能得到更好的結果,有些人認為都好。我希望透過這篇文章,藉由一些實驗,探討這個問題。
要做出正確的判斷,我們必須先理解這兩個預處理步驟各自的核心目標:
(1) 特徵縮放 (標準化 or MinMaxScaler) : 根本目的是將不同尺度的特徵轉換到相同的比例尺度上。這不僅能確保模型在學習過程中公平地評估每個特徵的重要性,更能大幅提升計算效率。當特徵被縮放到較小的範圍時,各種涉及距離計算的演算法(如SMOTE)能更快速地執行,這是因為小數值的運算本質上就比大數值更有效率。
(2) 不平衡處理 (imbalance sampling) : 目標則是確保模型能充分學習到少數類別的特徵模式。無論是透過過採樣產生新的少數類別樣本,還是通過欠採樣減少多數類別的數量,這個步驟的重點都在於調整類別間的平衡,使模型能更好地識別稀少但重要的模式。
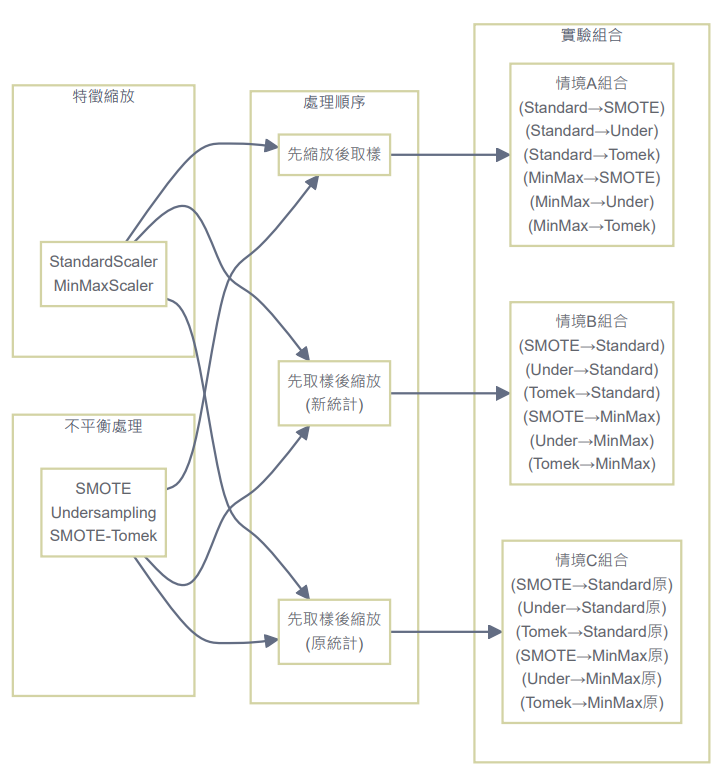
為了深入研究處理順序的影響,我設計了一個實驗,給定使用最單純的logistic預測模型下,比較了三種不同的處理順序:
其中,比較了StandardScaler和MinMaxScaler兩種縮放方法,以及SMOTE、隨機欠採樣、SMOTE-Tomek三種不平衡處理方法。
Kaggle 的 Credit Card Fraud Detection 資料集。 資料集連結
這是一個歐洲信用卡詐騙偵測資料集,收錄了2013年9月兩天內的284,807筆交易紀錄,其中詐騙案例佔0.172%(492筆)。主要特徵包含28個經PCA轉換的匿名特徵(V1-V28),以及原始的交易時間和金額。由於資料極度不平衡,該競賽建議使用ROCAUC而非準確率來評估模型表現。
(各個情境都執行10次,計算平均執行時間和標準差)
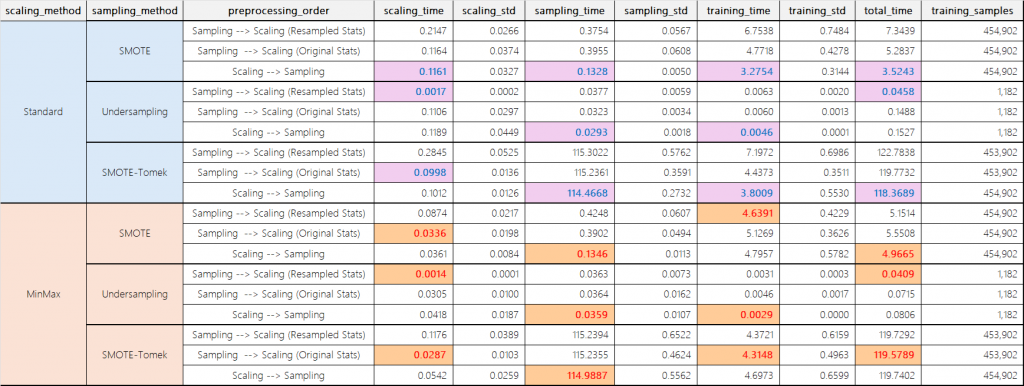
(顏色標住的地方代表該情境下,所花費時間最少)
實驗結果顯示,先進行特徵縮放後再處理不平衡問題能夠顯降低不平衡抽樣執行效率 (sampling_time)。這個結果完全符合理論預期:當特徵被縮放到較小的範圍後,不平衡處理算法 (特別是基於距離計算的方法如SMOTE)的運算效率自然會提高。
以SMOTE+標準化縮放為例:
當先進行縮放時 (Scaling-->Sampling):總處理時間為 0.1328 秒
當先進行不平衡抽樣時(Sampling --> Scaling (Resampled Stats)):總處理時間為 0.3754 秒
時間減少了約65% (0.1328/0.3754-1)x100%
這種效率提升的原因在於經過縮放的特徵能夠讓SMOTE算法中的距離計算更有效率,降低了生成合成樣本的時間成本。這種改善在不同的縮放方法,如標準化、MinMax中都能觀察到。
此外,我的訓練樣本才40多萬筆,假設套用到實務,動輒上百萬筆的交易數據,不就差異更大了!!?
標準化處理:可以發現若先採樣,會把原始資料的平均、標準差大幅改變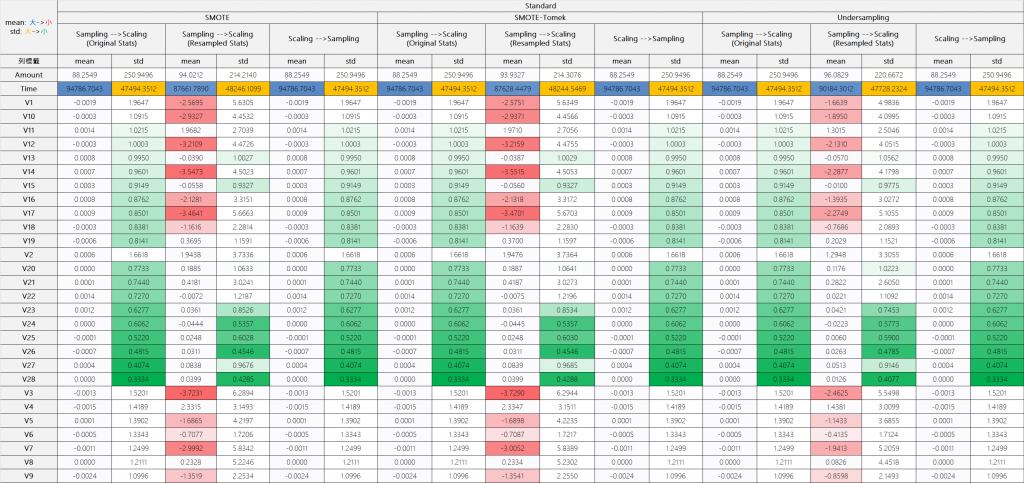
MinMax處理,這邊除了Undersampling涉及刪減樣本,而導致最大最小改變外,其他情境的MinMax都差不多一樣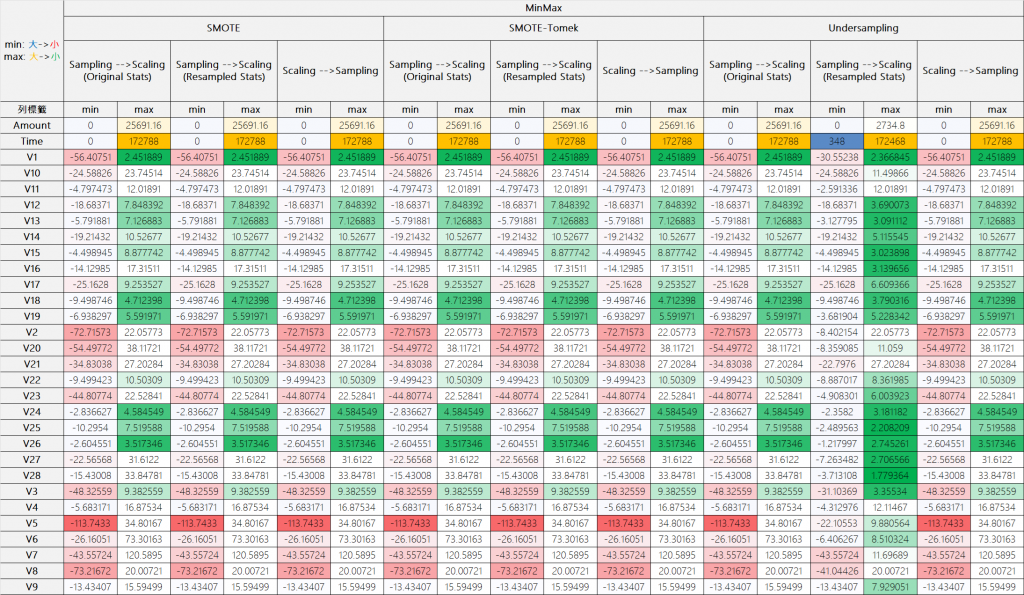
當我們先進行不平衡處理時,後續的縮放過程會使用改變後的數據分布來計算統計量,這可能導致特徵的相對關係發生變化。相比之下,先進行縮放能確保我們使用原始數據的統計特性,這對於保持特徵間的真實關係至關重要。但如果是透過MinMaxScaler的方式縮放特徵,除非不平衡處裡演算法有做到刪減樣本的動作 (如本次實證採用欠採樣,將正常樣本刪除到與詐欺樣本 =2:1),原則上MinMaxScaler的最大、最小若不會變動,則執行先後無差,反之就要注意。
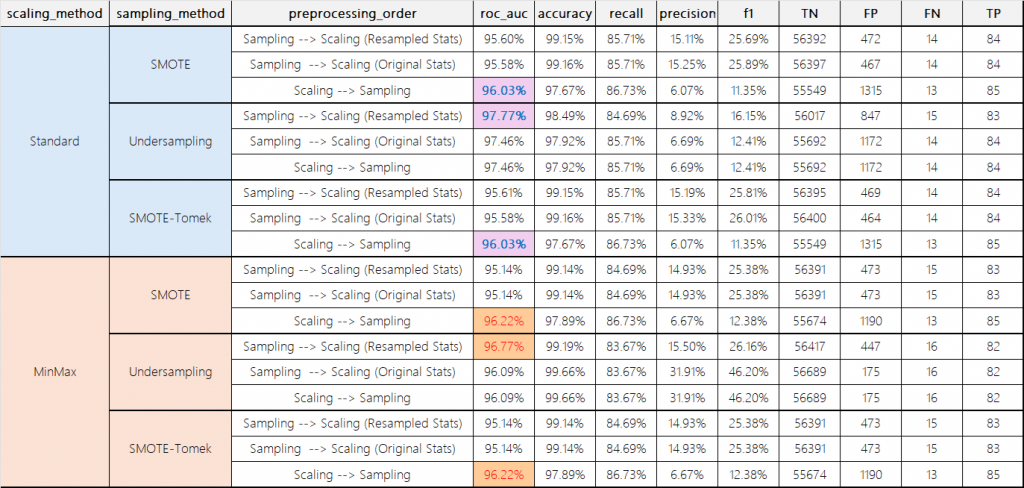
由於資料極度不平衡,該競賽建議使用ROCAUC而非準確率來評估模型表現。
實驗結果顯示,在模型效能方面,處理順序的影響雖然存在,但數據差異並不顯著。然而,值得注意的是,在SMOTE和SMOTE-Tomek這兩種方法下,先進行特徵縮放的策略在ROC-AUC指標上仍略微領先。
額外討論:特別說明Undersampling和SMOTE系列方法的選擇考量:
Undersampling特性:
實驗中採用2:1的比例 (刪減後正常樣本:詐欺樣本)。優點是能有效降低誤報率 (FP),進而使ROC-AUC表現較好
SMOTE系列特性:
通過模擬方式擴增異常樣本,優點是能更好地檢測出異常案例 (FN小於等於Undersampling的FN),但容易過擬。雖然可能導致較高的誤報率 (FP),但在實務應用中更適合處理高成本異常案例
實務應用建議:
當異常樣本的成本特別高時 (如金融詐欺造成的巨額損失),建議使用SMOTE系列方法。這類情況下,寧可提高異常檢測比率,也不要漏掉真正的異常案例,須根據具體業務場景和成本考量來選擇合適的方法。
基於實驗結果和理論分析,我強烈建議在大多數情況下先進行特徵縮放,再處理不平衡問題。這個建議基於以下三個關鍵理由:
通過本次的實驗,我們有諸多理由得到 「在大多數情況下,先進行特徵縮放再處理不平衡問題是更優的選擇。」
這個結論不僅基於效率考量,更重要的是基於對數據本質和演算法機制的考量。當然,在特定場景下 (如某些手法下,若使用MinMaxScaler且確定不會影響特徵邊界值的情況)處理順序的影響可能較小,但為了工作流程的一致性和可靠性,建議仍然採用「先縮放後平衡」的標準流程。
import numpy as np
import pandas as pd
import time
import statistics
from tqdm import tqdm
from dataclasses import dataclass
from typing import Dict, List, Tuple
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.combine import SMOTETomek
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
roc_auc_score,
confusion_matrix,
accuracy_score,
recall_score,
precision_score,
f1_score
)
from sklearn.linear_model import LogisticRegression
@dataclass
class TimingMetrics:
scaling_time: float = 0.0
scaling_std: float = 0.0
sampling_time: float = 0.0
sampling_std: float = 0.0
training_time: float = 0.0
training_std: float = 0.0
total_time: float = 0.0
def measure_execution_time(func, num_runs=5):
"""測量函數執行時間,返回平均值和標準差"""
execution_times = []
# 預熱運行
for _ in range(3):
func()
# 正式測量
for _ in range(num_runs):
start_time = time.perf_counter()
func()
end_time = time.perf_counter()
execution_times.append(end_time - start_time)
mean_time = statistics.mean(execution_times)
std_dev = statistics.stdev(execution_times) if len(execution_times) > 1 else 0
return mean_time, std_dev
def reduce_mem_usage(df):
"""減少DataFrame的記憶體使用"""
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
else:
if c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
return df
def process_experiment(X_train: np.ndarray, X_test: np.ndarray,
y_train: np.ndarray, y_test: np.ndarray,
scaler_class, sampler, process_type: str,
feature_names: List[str],
random_state: int = 123,
num_runs: int = 5) -> Tuple[Dict, List[Dict], TimingMetrics]:
"""執行單次實驗流程並記錄詳細時間"""
timing = TimingMetrics()
start_total = time.perf_counter()
if process_type == "Scaling → Sampling":
# 建立並保存 scaler
scaler = scaler_class()
# 測量縮放時間
def scaling_step():
scaler.fit(X_train)
return scaler.transform(X_train)
scaling_time, scaling_std = measure_execution_time(scaling_step, num_runs)
X_train_scaled = scaling_step() # 實際使用的轉換結果
timing.scaling_time = scaling_time
timing.scaling_std = scaling_std
# 測量取樣時間
def sampling_step():
return sampler.fit_resample(X_train_scaled, y_train)
sampling_time, sampling_std = measure_execution_time(sampling_step, num_runs)
X_current, y_resampled = sampling_step() # 實際使用的取樣結果
timing.sampling_time = sampling_time
timing.sampling_std = sampling_std
elif process_type == "Sampling → Scaling (Resampled Stats)":
# 測量取樣時間
def sampling_step():
return sampler.fit_resample(X_train, y_train)
sampling_time, sampling_std = measure_execution_time(sampling_step, num_runs)
X_resampled, y_resampled = sampling_step()
timing.sampling_time = sampling_time
timing.sampling_std = sampling_std
# 測量縮放時間
# 建立並保存 scaler
scaler = scaler_class()
def scaling_step():
scaler.fit(X_resampled)
return scaler.transform(X_resampled)
scaling_time, scaling_std = measure_execution_time(scaling_step, num_runs)
X_current = scaling_step()
timing.scaling_time = scaling_time
timing.scaling_std = scaling_std
else: # "Sampling → Scaling (Original Stats)"
# 測量縮放時間
def scaling_step():
scaler = scaler_class()
scaler.fit(X_train)
return scaler.transform(X_train)
scaling_time, scaling_std = measure_execution_time(scaling_step, num_runs)
scaler = scaler_class().fit(X_train) # 保存轉換器供後續使用
timing.scaling_time = scaling_time
timing.scaling_std = scaling_std
# 測量取樣時間
def sampling_step():
return sampler.fit_resample(X_train, y_train)
sampling_time, sampling_std = measure_execution_time(sampling_step, num_runs)
X_resampled, y_resampled = sampling_step()
timing.sampling_time = sampling_time
timing.sampling_std = sampling_std
X_current = scaler.transform(X_resampled)
# 收集縮放統計資料
scaling_stats = []
for i, feature in enumerate(feature_names):
stats = {
'feature': feature,
'mean_used': scaler.data_min_[i] if isinstance(scaler, MinMaxScaler) else scaler.mean_[i],
'std_used': scaler.data_max_[i] if isinstance(scaler, MinMaxScaler) else scaler.scale_[i],
'mean_result': X_current[:, i].mean(),
'std_result': X_current[:, i].std()
}
scaling_stats.append(stats)
# 測量訓練時間
def training_step():
model = LogisticRegression(random_state=random_state, solver='liblinear', max_iter=1000)
model.fit(X_current, y_resampled)
return model
training_time, training_std = measure_execution_time(training_step, num_runs)
model = training_step() # 實際使用的模型
timing.training_time = training_time
timing.training_std = training_std
# 預測
X_test_scaled = scaler.transform(X_test)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]
y_pred_label = (y_pred_proba >= 0.5).astype(int)
timing.total_time = time.perf_counter() - start_total
# 計算評估指標
metrics = {
'training_samples': len(y_resampled),
'roc_auc': roc_auc_score(y_test, y_pred_proba),
'confusion_matrix': confusion_matrix(y_test, y_pred_label).ravel(),
'accuracy': accuracy_score(y_test, y_pred_label),
'recall': recall_score(y_test, y_pred_label),
'precision': precision_score(y_test, y_pred_label),
'f1': f1_score(y_test, y_pred_label)
}
return metrics, scaling_stats, timing
def create_summary_tables(results_df: pd.DataFrame) -> Dict[str, pd.DataFrame]:
"""建立詳細的統計摘要表格"""
summary_tables = {}
# 1. 按照縮放方法分組的統計
metrics_cols = ['roc_auc', 'accuracy', 'precision', 'recall', 'f1',
'scaling_time', 'scaling_std', 'sampling_time', 'sampling_std',
'training_time', 'training_std', 'total_time']
for group_by in ['scaling_method', 'sampling_method', 'preprocessing_order']:
summary = results_df.groupby(group_by)[metrics_cols].agg([
('mean', 'mean'),
('std', 'std'),
('min', 'min'),
('max', 'max')
]).round(4)
summary_tables[f'summary_by_{group_by}'] = summary
# 2. 交叉分析表
for metric in metrics_cols:
pivot = pd.pivot_table(
results_df,
values=metric,
index='scaling_method',
columns=['sampling_method', 'preprocessing_order'],
aggfunc='mean'
).round(4)
summary_tables[f'pivot_{metric}'] = pivot
return summary_tables
def main():
# 設定RANDOM_STATE
RANDOM_STATE = 123
NUM_RUNS = 10 # 每個時間測量重複次數
# 讀取資料
print("Loading and preparing data...")
data = pd.read_csv("creditcard.csv").dropna()
#data = data.sample(n=6000, random_state=RANDOM_STATE)
data = reduce_mem_usage(data)
print("Dataset Shape:", data.shape)
# 顯示類別分布
print("\nClass distribution:")
counts = data['Class'].value_counts()
print(f"Normal transactions: {counts[0]}")
print(f"Fraudulent transactions: {counts[1]}")
print(f"Fraud ratio: {(counts[1] / len(data) * 100):.4f}%")
# 準備資料
X = data.drop('Class', axis=1)
y = data['Class']
feature_names = X.columns.tolist()
# 分割訓練測試集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=RANDOM_STATE
)
# 不平衡處理方法
samplers = {
'SMOTE': SMOTE(random_state=RANDOM_STATE),
'Undersampling': RandomUnderSampler(random_state=RANDOM_STATE, sampling_strategy=0.5),
'SMOTE-Tomek': SMOTETomek(random_state=RANDOM_STATE)
}
# 縮放方法
scaler_choices = {
'Standard': StandardScaler,
'MinMax': lambda: MinMaxScaler(feature_range=(-1, 1))
}
# 處理順序
process_types = [
"Sampling → Scaling (Resampled Stats)",
"Sampling → Scaling (Original Stats)",
"Scaling → Sampling",
]
# 儲存結果
results = []
all_scaling_stats = []
print(f"\nRunning experiments (each timing measurement repeated {NUM_RUNS} times)...")
# 執行實驗
for scaling_method_name, scaler_class in tqdm(scaler_choices.items(), desc="Scaling Methods"):
for sampler_name, sampler in tqdm(samplers.items(),
desc=f"Sampler for {scaling_method_name}",
leave=False):
for process_type in process_types:
# 執行實驗並收集結果
metrics, scaling_stats, timing = process_experiment(
X_train.copy(), X_test.copy(), y_train.copy(), y_test.copy(),
scaler_class, sampler, process_type, feature_names,
RANDOM_STATE, NUM_RUNS
)
# 儲存結果
result = {
'scaling_method': scaling_method_name,
'preprocessing_order': process_type,
'sampling_method': sampler_name,
'scaling_time': timing.scaling_time,
'scaling_std': timing.scaling_std,
'sampling_time': timing.sampling_time,
'sampling_std': timing.sampling_std,
'training_time': timing.training_time,
'training_std': timing.training_std,
'total_time': timing.total_time,
'roc_auc': metrics['roc_auc'],
'training_samples': metrics['training_samples'],
'TN': metrics['confusion_matrix'][0],
'FP': metrics['confusion_matrix'][1],
'FN': metrics['confusion_matrix'][2],
'TP': metrics['confusion_matrix'][3],
'accuracy': metrics['accuracy'],
'recall': metrics['recall'],
'precision': metrics['precision'],
'f1': metrics['f1']
}
results.append(result)
# 儲存縮放統計
for stats in scaling_stats:
stats.update({
'scaling_method': scaling_method_name,
'preprocessing_order': process_type,
'sampling_method': sampler_name
})
all_scaling_stats.append(stats)
# 轉換為DataFrame
results_df = pd.DataFrame(results)
scaling_stats_df = pd.DataFrame(all_scaling_stats)
# 生成摘要表格
summary_tables = create_summary_tables(results_df)
# 儲存結果
results_df.to_csv('detailed_results.csv', index=False)
scaling_stats_df.to_csv('scaling_statistics.csv', index=False)
# 儲存摘要表格
with pd.ExcelWriter('summary_statistics.xlsx') as writer:
for name, df in summary_tables.items():
df.to_excel(writer, sheet_name=name[:31]) # Excel sheet名稱最長31字元
print("\nExperiment completed. Results have been saved:")
print("- Detailed results: detailed_results.csv")
print("- Scaling statistics: scaling_statistics.csv")
print("- Summary statistics: summary_statistics.xlsx")
# 印出關鍵結果摘要
print("\nKey Performance Metrics Summary:")
print("\nROC-AUC Scores by Scaling Method:")
print(summary_tables['summary_by_scaling_method']['roc_auc'])
print("\nROC-AUC Scores by Sampling Method:")
print(summary_tables['summary_by_sampling_method']['roc_auc'])
print("\nROC-AUC Scores by Processing Order:")
print(summary_tables['summary_by_preprocessing_order']['roc_auc'])
print("\nTiming Statistics Summary:")
print("\nScaling Time (seconds) by Method:")
print(summary_tables['summary_by_scaling_method'][['scaling_time', 'scaling_std']])
print("\nSampling Time (seconds) by Method:")
print(summary_tables['summary_by_sampling_method'][['sampling_time', 'sampling_std']])
if __name__ == "__main__":
main()
 吉度濕潤@@
吉度濕潤@@
