在朋友的推薦下開始使用PTT,個人最常逛的就是表特版,因為希望能更快速的過濾出想要看的文章,所以試著爬蟲想要看的文章,幸運的是PTT爬蟲友善,且也有許多文章可以參考。
PTT就是充滿著鄉民的那個PTT,給人的印象比較多是充滿著暴戾之氣,不過在表特版中,不太常有紛爭、筆戰,更多的是純欣賞和讚美,是讓眼睛和心情放鬆的好所在。
網址是 https://www.ptt.cc/bbs/Beauty/index.html ,而因為有規定文章的格式,PTT很適合用來練習爬蟲。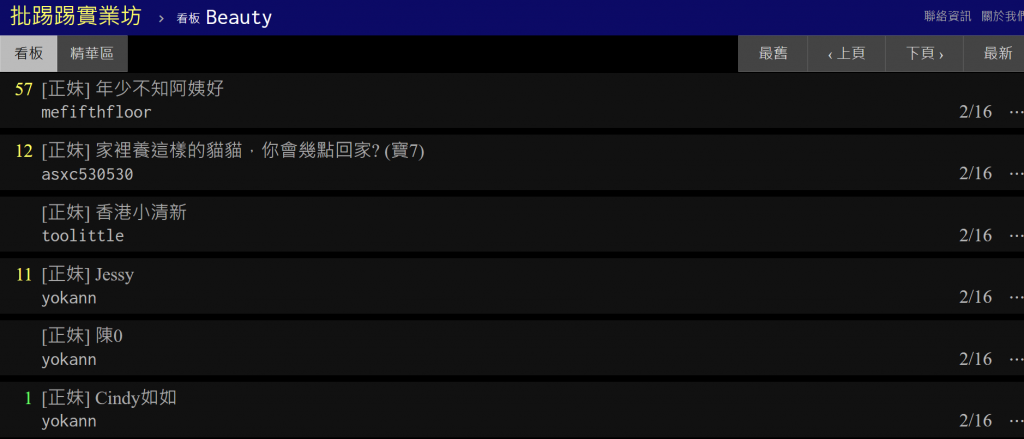
例如像文章在結束前會有個 "--",所以擷取 "--" 前的圖片就不會擷取到留言區的圖片 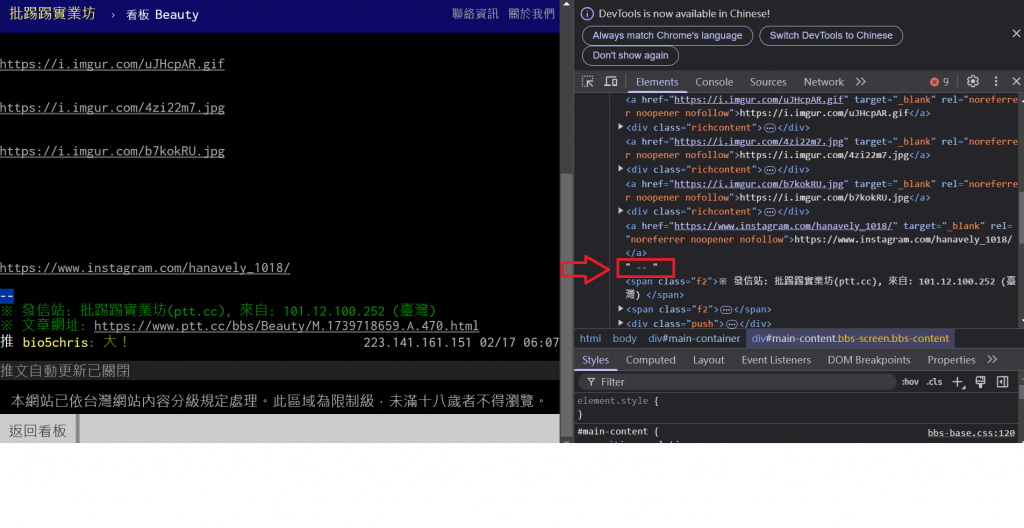
不過有時候在文章結束前會有圖片中本人的社群連結,所以要加入黑名單過濾幾個常見的平台
目標是昨天的文章因為今天會不會再有新增的文章不知道,但是昨天總不會有新文章了吧;鎖定分類不含[神人]和[帥哥],並且標題中不包含 "Cosplay",且沒有被刪除的文章 , personal reference , 因為比較少看動漫所以看不太懂 Coser 扮的是誰。
python version 3.13,會使用到requests和bs4, 要先
pip install requests bs4
在網址中選擇昨天的文章,並取出文章中的圖片,程式碼參考了版上其他文章例如: 使用 requests & bs4 爬蟲、確認已成年的 cookie 、翻頁 ...等等,就不一一列舉了。
# import library
import requests
from bs4 import BeautifulSoup as BS
import time #用來time.sleep()
from datetime import datetime, timedelta
def Main():
# 設定URL
base_url = "https://www.ptt.cc"
sub_url = f"/bbs/Beauty/index.html"
cookies = {'over18': '1'}
session = requests.Session()
# 使用config中的函數獲取昨天日期
yesterday = yesterday = datetime.now() - timedelta(days=1)
yesterday_str = f"{yesterday.month}/{yesterday.day:02d}"
# 初始化變數用來記錄爬取的文章和總爬取的頁數
data = list()
page_count = 0
max_page = 8
while page_count < max_page: # 設定最多爬幾頁
full_url = f"{base_url}{sub_url}" # 組合URL
response = session.get(full_url, cookies=cookies) # 設定網站的cookie確認成年
bs = BS(response.text, "html.parser") # BeautifulSoup解析網頁
# 找出所有文章列表項目
articles = bs.find_all("div", class_="r-ent")
# 文章列表中找出昨天的文章
for article in articles:
date = article.find("div", class_="date").text.strip()
title_div = article.find("div", class_="title")
if date == yesterday_str: # 找到今天的文章
title = title_div.text.strip()
if "Cosplay" in title or "帥哥" in title or "神人" in title:
continue
parsed_title = SplitTitle(title)
if parsed_title is None:
continue
title_link = title_div.find('a') # 找到文章連結
if title_link:
post_url = base_url + title_link.get('href')
images = ExtractImages(post_url, cookies, session)
parsed_title["Images"] = images
if parsed_title:
data.append(parsed_title)
# 找下一頁的連結
next_page = FindNextPage(bs)
if not next_page: # 如果沒有下一頁就結束
break
sub_url = next_page # 更新 sub_url 為下一頁的網址
page_count += 1
image_urls = []
for article in data:
if "Images" in article:
image_urls.extend(article["Images"])
return image_urls
def SplitTitle(title: str):
if "本文已被刪除" in title:
return
if "[" not in title:
return
if "]" not in title:
return
r = title.index("]")
title = title[r + 1 :].strip()
return {"Title": title}
def FindNextPage(bs):
links = bs.find_all("a", attrs={"class": "btn wide"})
for link in links:
if link.text == "‹ 上頁":
return link.attrs["href"]
# 設定黑名單,所有包含這些字串的網址都會被過濾掉
BLACKLIST = [
"instagram",
"facebook",
"tiktok",
"https://x.com/",
"twitter",
"youtube",
"https://youtu"
]
def ExtractImages(url, cookies, session):
try:
web = session.get(url, cookies=cookies)
time.sleep(1)
if web.status_code == 429:
time.sleep(int(web.headers.get('Retry-After', 60)))
web = session.get(url, cookies=cookies)
soup = BS(web.text, "html.parser")
main_content = soup.find('div', id='main-content')
links = []
for element in main_content.contents: # 遍歷所有子節點 (包括 #text)
if isinstance(element, str) and element.strip() == "--":
break # 遇到 "--" 則停止
if element.name == 'a' and 'href' in element.attrs:
href = element['href']
# 黑名單過濾: 如果網址包含黑名單中的關鍵字,就跳過
if any(blacklisted in href for blacklisted in BLACKLIST):
continue
links.append(href)
return links
except requests.exceptions.TooManyRedirects:
print(f"重定向過多: {url}")
return [] # 返回空列表,表示沒有獲取到圖片
if __name__ == "__main__":
urls = Main()
print(f"找到{len(urls)} 張圖片")
這段 Main() 函式回傳昨天表特版上目標文章中圖片url的陣列,可以再結合之前有關 Notion 的發文 - 使用Python Notion API匯入新頁面 ,把圖片匯入Notion中,並使用 Notion 的圖庫及日曆的瀏覽模式來管理圖片。
 bobby7414
bobby7414
