完整內容在此, 幹話王_Grafana Loki 和 Bloom Filter
在系統中,常常會面對一個問題,這資料存在不?這命令剛剛執行過了不?往往我們會把這些結果儲存至資料庫中,並且很可能建立索引(Indexing)或是設定唯一約束(Unique constraint),並免重複資料存在。也可能會在 application 中以 Map 或是 Tree 的資料結構來儲存這些資料,以便提供判斷。
在 Tree 讀取上不會是 O(1),而 Map 在記憶體的空間利用率上也不能用到很極致,都會有些許碎片化的副作用產生。具體細節能參考這篇了解 Go Map。但有些許時刻不是要取得資料元素全部屬性,而是要知曉是否存在而已。這兩者的目的是要儲存資料所設計的,像是快取的需求或是查詢分析的需求。
以網頁爬蟲為例,如果要給 crawler 知道給定的 URL 是否已經訪問過了呢?這時你會怎麼做?我直覺想到以下幾個解決方案︰
把訪問過得 URL 儲存至資料庫,並且設定 Unique。
在 PostgreSQL 與 MySQL,Unique index 都是以 B-Tree 型是在儲存處理。因此判斷是否存在的效率就取決於樹高,新增與查詢都需要判斷是否滿足該約束,所以不會非常快。

在 Application 用 Map 儲存訪問過得 URL。
記憶體利用率不高,會因為 load factor 的設定使得填充率不高,常見的策略是只有用到該 page 的 50% 利用率,如果該 Page 快滿了,會把 Map 的 Bucket 數量翻倍,頗費記憶體資源。

以上兩種覺得有點浪費空間,因此把 URL 透過 MD5 或是 SHA 做hash後在儲存至資料庫或 Map中
建立一個 BitArray 把 URL 經過 hash 印射到該Array的某一個位置
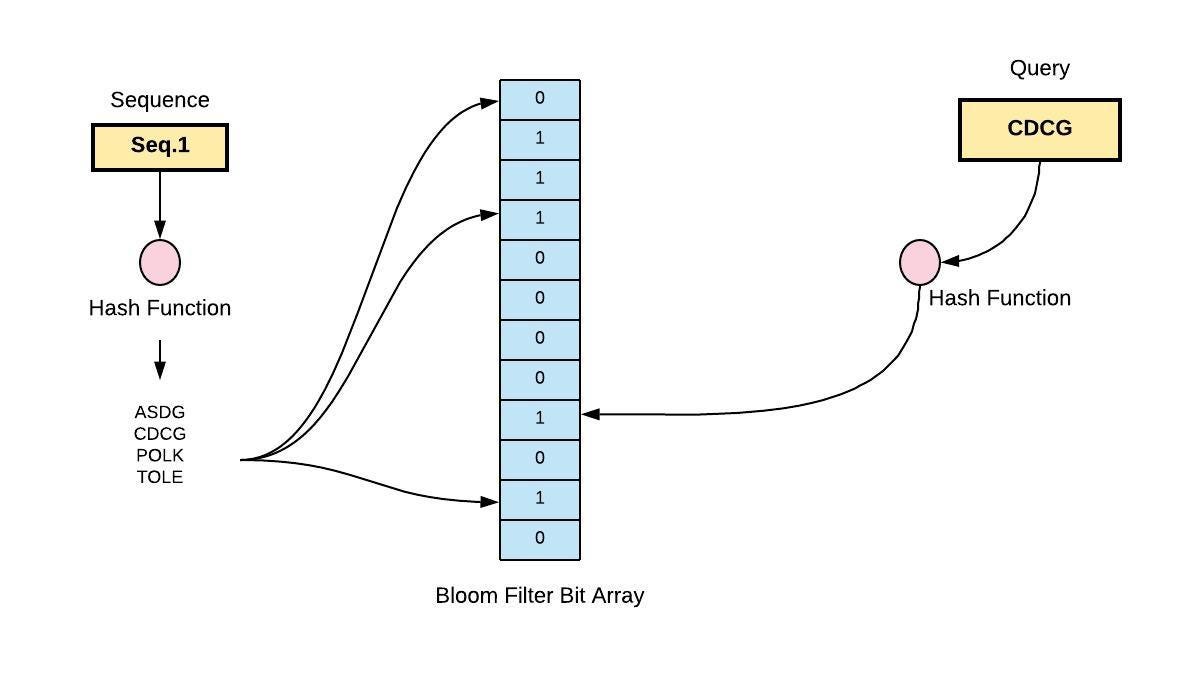
思考一下這 4 個方案,方案1~3都是把訪問過得 URL 完整儲存下來,在資料量來到一億筆時想像一下會發生什麼問題?方案 1 資料庫單表可能已經無法快速查詢需要一些優化手段。方案 2 ,如果每個 URL 長度為 50,在 UTF-8 ASCII 編碼下,每個 URL 約 50 bytes,一億筆需要將近 5GB 的記憶體來儲存。方案 3 透過 MD5 長度只有 128 Bit,SHA-1 約 160 Bit,也需要約 2GB 的記憶體。
而方案4指標記儲存一個 Bit,則一億筆只需要 12.5 MB 的記憶體需求。相較於方案 1~3(需要數 GB 的記憶體),方案 4 的空間效率極高。但因為是 Bit Array 所以有長度的設定,Hash function 也會基於這長度來決定放的位置,但要有有限的長度來存放近似無限的長度,勢必會發生衝突(Conflict,不同 URL 但對應到同一個位置)。如果要降低衝突機率就需要把 Array 長度變成預計儲存元素個數的數倍,以空間換時間的概念,但我們的主軸是節省空間。
加大 Array 長度能降低衝突問題,但會帶來稀疏的利用率問題,本來想要節省記憶體需求,變成沒省到太多。為此 Bloom Filter 的解決方法是使用了多個 hash function。因為單一個 hash function,在資料量逐漸變多時,衝突機率也會隨之變高(這裡稱呼該衝突機率為 p1)。而使用多個 hash function,分別衝突機率就會是 p1、p2、p3 … pn,又因為每個 hash function 彼此是獨立計算的不受到彼此狀態的影響,因此多個hash function 在這bit array 上的衝突機率就會是 p1*p2*…*pn,那就會遠小於 p1 了,用多一些計算使得衝突機率大幅減小,且不用更多的記憶體需求。所以要降低衝突機率有兩種解法,一是增加 array 長度,二是多個 hash function 來定義出該元素的多個位置,這做法就來到 Bloom Filter 的核心。
完整內容在此, 幹話王_Grafana Loki 和 Bloom Filter
 雷N
雷N
