這一篇我們介紹如何部署股哥的storage system與在這些系統上的資料運作,例如資料的匯出/匯入,設定存取控制,效能調較等。包含了Cloud SQL, Cloud Spanner, Cloud Bigtable,Cloud Firestore,BigQuery,Cloud Memorystore與cloud Storage。同時我們也會討論到如何管理unmanaged Database, 了解各項storage service費用與效能,還有data lifecycle的資料管理。最終目的是要建立我們的Data pipeline。
Cloud Spanner
這是股哥專屬的Relational, horizontally scalable, global的DB。 因為它是relational DB所以也support fixed schema(是合規ANSI SQL 2011的)。Cloud Spanner提供data 的strong consistency. 所以所有對DB的平行處理程序看到的DB狀態都是一樣的。Cloud Spanner的data consistency跟No SQL的 eventually consistent是不一樣的,因為每個處理程序看到的NOSQL DB states是不一樣的。Cloud Spanner原生就是HA的,而且不需要failover instance(像Cloud SQL). 它是自動replica data到所有的節點的。
設定Cloud Spanner
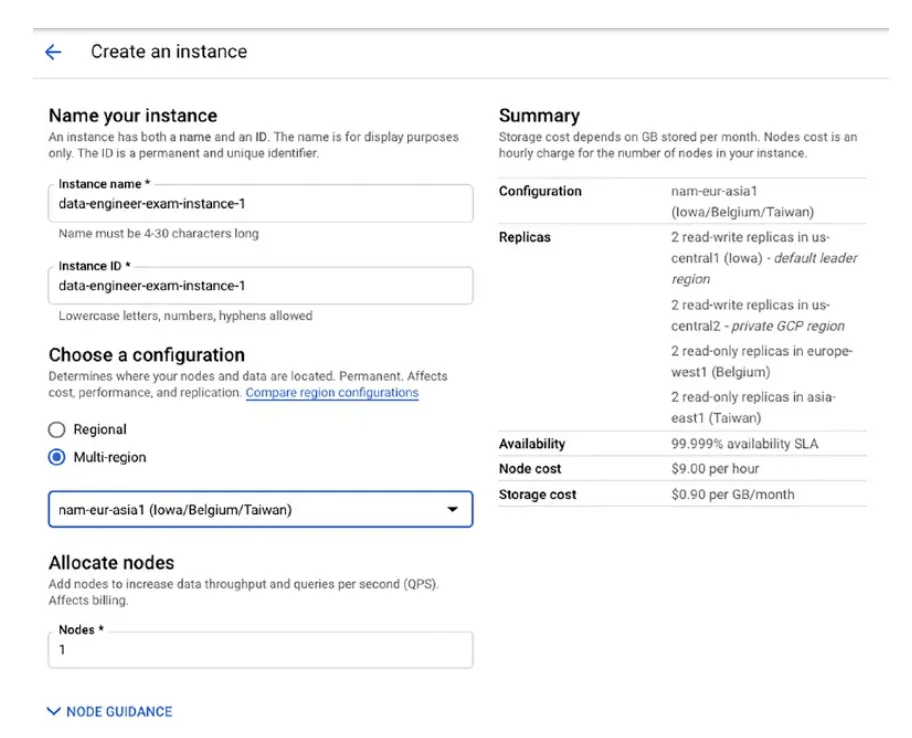
設定方式跟Cloud SQL很類似(如下圖),以下在create instance時需要指定以下資訊
其中上面第四與第五項的選擇關乎到你的費用。因為在不同的region有費用會有稍許的差異。 nodes的數量跟你資料的負載有關。 股哥建議如果只有一個Region跑Spanner,哪麼instance CPU要低於65%。如果是multi-regional instance就要低於45%. 每一個node可以儲存2TB的資料。
Replication in Cloud Spanner
Spanner會負責將這些散落在不同region的DB instance做data replica(by rows)。當Spanne開始將這些instance做全球性的資料同步,你可以從任一個replica讀得到最新的資料(row)。 Row會被拆分,拆分是一起copy的連續性blocks of row。這一群replica其中一個會被指定為leader,這個leader負責將資料寫入。由於資料與需要資料的Application在地理位置上接近,因此使用replica可以提data 的HA並減少latency。同樣,你需要拿捏添加nodes的效益與一直往上加node的費用取得一個平衡。
因為這樣分散式的特性對Spanner寫入資料時造成了挑戰。為了讓所有的replica保持資料同步,Spanner使用投票機制來決定資料寫入會發生的衝突狀況。Spanner使用這個投票機制使用"conflict value"來決定哪一資料是最新的資料寫入。
Spanner有三種replica型式
Regional instance只能只用 Read-only replicas; 而Mutli-regional instance則是三種都可以使用。Read-write replicas維持full copies的data以及讀取的操作,它們也可以選出write operation. Read-only replicas除能不能選出write operation之外,其他功能都跟Read-write replicas一樣。Witness replicas沒有保有全部的資料,但是會參與write投票。Read-write replicas最大的功用在於完成選舉的法定人數機制。
Regional instance可以維持三個Read-write replicas. 而使用Multi-regional instance我們可以考慮在兩個region使用 Read-write replicas,每個region 有兩個replicas。在這兩個region裡面選出一個leader replicas。而Witness replicas則選擇放置在第三個region。
Database 設計考量
就像NoSQL DB一樣, Spanner 也會發生同時對一個node 有過多的read-write operation而沒有將同時大量的read-write平行處理分流到多個node,這個我們稱為hotspots. 會發生這樣的狀況通常都是你使用的primary key是有順序性的,例如自動增加計數或timestamp的欄位資料。如果真的要用這一類的值作為primary key,哪麼就要將這些值(value)做hash.
如同我們之前提到的Relational DB的資料是經過正規化的。這意味著你在讀取資料時通常這些資料是分散在不同的table,哪麼 join table就會經常使用到。而這也是讀取DB效能最差的動作,因為DB需要從storage擷取不同的data block來組合資料。而Clud Spanner採用了一種parent-child 的方法讓這一類的資料儲存在一起(同一個data block),這一個方法需要你在Design schema時指定。需要注意的是採用parent-child方式的table它們的row size不可以超過4GB.
匯入/匯出資料
資料可以被從 Cloud storage import/export到 Cloud Spanner. export的檔案格式為CSV 或Apache Avro. 這個匯出的流程我們可以使用 Cloud Dataflow connector來完成。
以下有幾個因素會影響資料的import/export的速度
Cloud Bigtable
一種用在幾豪秒內寫入大量資料的wide-column NoSQL DB.通常用在資料是IoT,time-series, finance 等相似的Application上使用。
設定 Bigtable
這也使一個全託管式的服務,像Cloud SQL, Cloud Spanner一樣,你只需要指定instance的相關資訊就可以。
除了需要指定Instance name , Instance ID外。你還需要確定這一個Bigtable的Cluster是要用在Production or Development的環境上(如下圖)。Production 環境提供了HA環境(至少需要三個node)費用貴了一點,而Developementc環境則不用HA提供了較低的費用進行測試而已。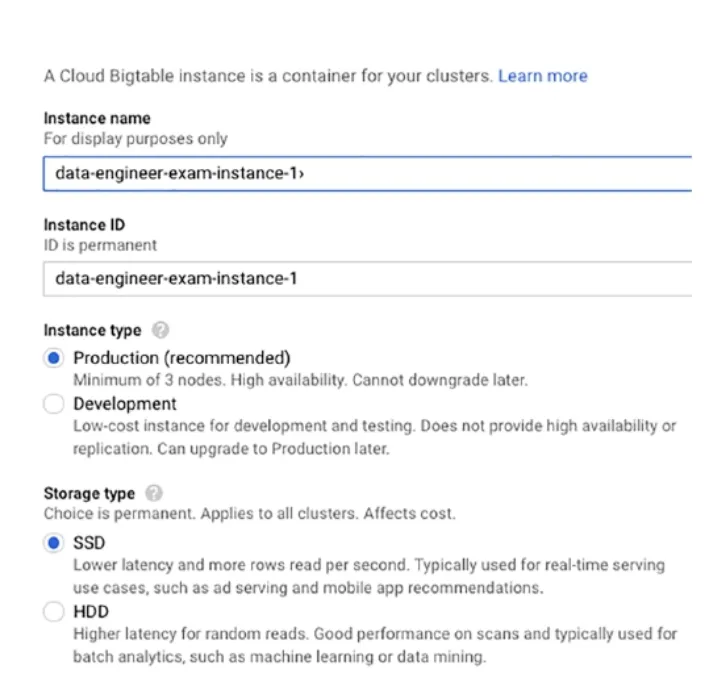
當Create cluster時我們需要提供cluster ID/ region/ zone/nodes的數量等資料。Bigtable的效能與nodes的數量呈線性關係,也就是說node數量越多效能越好。例如production cluster使用三個nodes並也採用SSD硬碟,哪麼每秒鐘可以同時read and write 3000筆row。如果有6 nodes則row的數量就加倍到6000。
雖然Bigtable的 cluster的node都在同一個region,但是你可以為這一個preoduction cluster在另一個region 做一個replica cluster, 資料會同步在這兩個cluster之間,你的cluster HA功能就可以到region level。如果你的primary cluster沒有反應它你可以手動的fail over過去。若是你的Application有multicluster routing功能,哪Application就會自動切換過去。
但Bigtable是一個稍微貴一點的服務(但若跟你在機房自建跟需要維運的能力技巧,你可以算一算這一筆帳,看哪個比較划算)。下圖是一個範例計算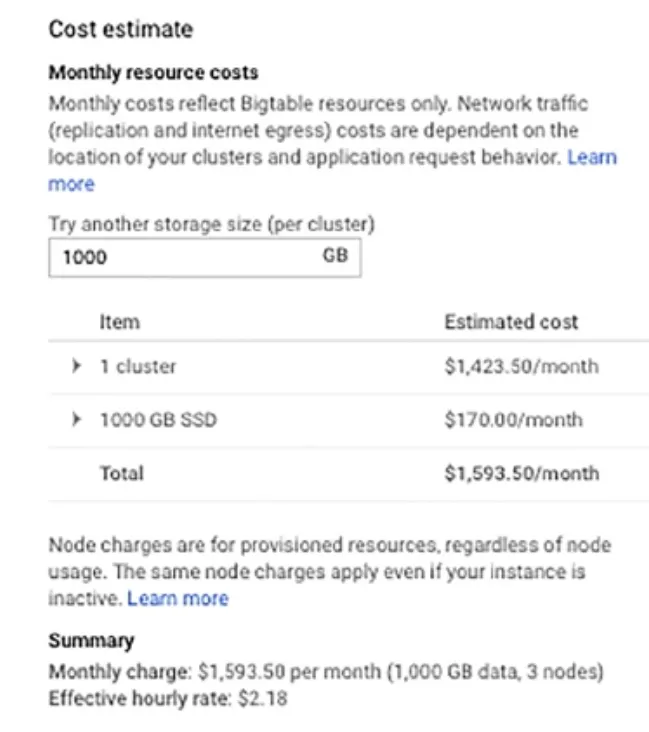
當你migrate 你地端的hadoop 跟Hbase到Bigtable時,如果你的JAVA是用到原來的HBase shell and HBase client則Bigtable提供一模一樣的功能。Bigtable也提供 "cbt"的command-line工具來操作Bigtable。
Bigtable可以被Bigquery access。 資料可以不用存在Bigquery而是以external型式存放在Bigtable。這讓你可以存放經常變動的資料在Bigtable裡(例如IoT資料),這樣做的好處在於如果你要對資料使用有機器學習功能的服務你就不用常常要將資料倒到BigQuery裡。
Database設計考量
這跟設計Relational DB的schema有非常大的不同,Bigtable 的table是非正規化的,一個table裡可能有上千個column。它沒有join table這樣的功能也沒有secondary indexes,資料存放在Bigtable是採用row-key的方式(這個我們股哥的儲存服務介紹文章有介紹過),它是一種在Bigtable的indexed-cloumn. 它會讓相關的資料盡量存放在鄰近的row,因為這樣就可以加快讀取的效能。
所有的operation在row-level都是atomic,而不是transactional level. 例如我們有一個Application 要寫兩筆row進去,有可能會一筆成功一筆失敗。而這樣會造成DB的不一致性發生,為了避免這個問題你的資料在write/update時最好相關的資料都在同一筆row中。
因為Bigtable沒有seconday indexes的功能,所以在查詢資料時只有兩種方式 — row-key-based or full table scan。後者大家都知道是很沒效率的做法,相反的單一的row-key或一個區間的row-key查詢方式才是比較有效的。但這需要你很小心的設計你想要怎麼query data哪row-key就要適合哪種query的方式。在Bigtable設計row-key的目標就是Bigtable儲存資料是有排序順序的。
好的row-key有著以下特徵
另外一個增加效能的方式是column families,它是一組資料相關的columns。這一類的資料會被一起儲存一起讀取。
匯入/匯出資料
Bigtable的data import /export跟Cloud Spanner一樣是用Cloud Dataflow來完成的。資料可以被從Cloud Storage import/export而資料格式則是 Avro或SequenceFile。CSV 檔案也可以用Dataflow完成。
BigQuery(底下會簡稱BQ)
BQ是一個全託管式並且儲存與分析的資料可以到PB等級的Data warehouse解決方案。我們在BQ經常會實行的工作如下
BQ Datasets
Datasets在整個BQ的整個組織裡最基本的單位。datasets裡面可以有很多個tables。當我們在create datasets時需要指定以下資訊
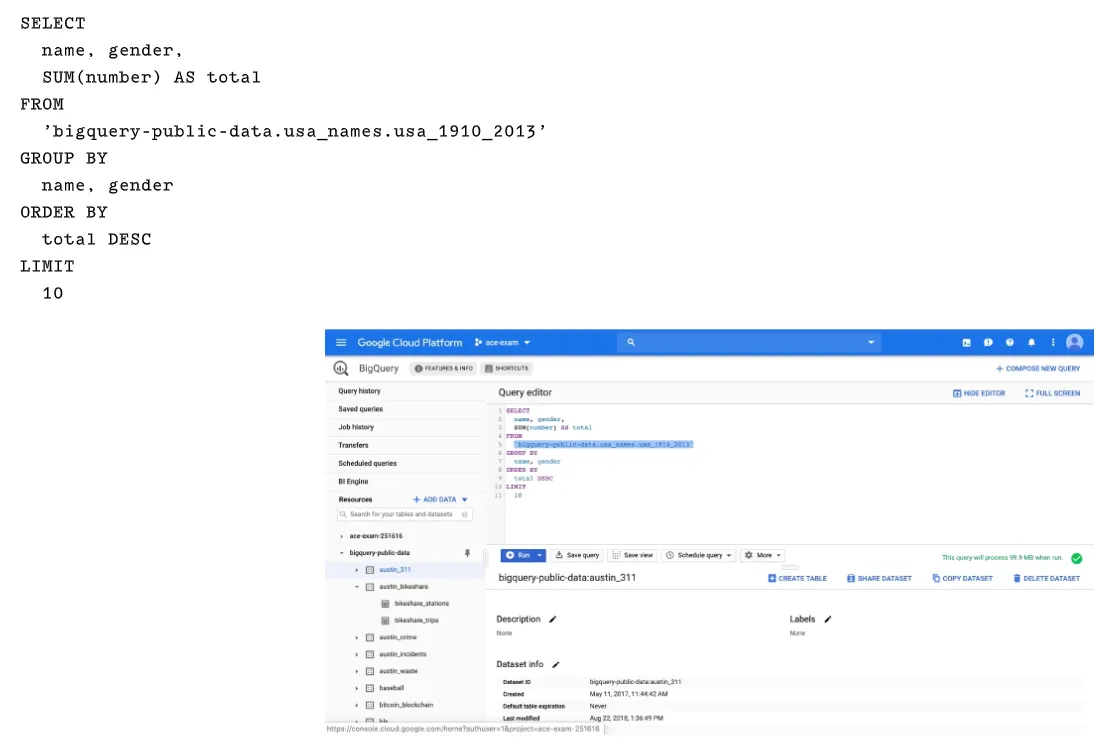
用過SQL語法的人應該很熟悉這一類的語法。唯一不同的是 FROM的table name必須要用full path來指定, 由三種資訊組成
'project_name.dataset_name.table_name'
你也可以在bq command-line模式下使用SQL與法來查詢,如下範例
BQ支援兩種不同的語法 , legacy 跟standard。建議上使用Standardm語法。Standard SQL支援advanced SQL feature,像是 correlated subsqueries, ARRAY與 STRUCT的data type,也支援complex join expressions.
BQ使用一種slots的概念來分配運算資源執行Query. 大部分的人使用預設的slot來查詢資料是足夠的,不過如果你是很非常大量的data query(一次處理的資料不超過100G)或是有很多人經常同時會做查詢,就會需要額外的slot來增加效能。整個slot(預設是2000) 的資源是以股哥的project來計算的.
載入與匯入資料
在現有的datasets中你還可繼續create table並將資料載入。你可以使用UI 或command 介面來做資料查詢,在做查詢時你需要明定以下資訊
BQ在接收資料檔案時會認定它收到的是UTF-8的編碼格式,如果你的CSV檔案不是URF-8格式BQ會試著covert。 但coveret可能永遠不會是正確,所以載入CSV檔案前還是需要檢查一下編碼。但JSON就一定要是HTF-8, BQ不會幫你covert.
Avro檔案則是BQ匯入資料的完美檔案格式(它沒有UTF-8編碼問題),因為data的block可以被平行處理的讀取到BQ中,並且當按在壓縮狀態中也可以被讀取。不過CSV/JSON則是要解壓縮後讀取資料的速度才比快(因為它們無法被平行處理讀取資料)。Parquet也是用cloumn mode的方式來儲存資料。
BQ的Data transfer service則可以從股哥的各項服務自動的將資料載入BQ,例如股歌 Ad manager, 股歌 Ads, 股歌 play, YouTube channel Report. 當然也可以從AWS S3載入資料。
Cloud Dataflow也可以直接將資料載入到BQ中。
Clustering, Partitioning and Sharding Table
BQ提供一種稱為clustered table的功能,它是基於資料的 內容會把一個以上的cloumn 組成一個資料有相關的cluster table. 這樣的作法可以在某些Queries加快讀取的效能,特別是在查詢使用到cloumn來filter row的方式。Cluster tables也可以被partation. 如果你的資料量很大分成很多個小的partation才會加快查詢效能。我們可以用date or timestamp來分割資料。如果是用attribute將資料分割到數個table我們則可以用sharding功能。
sharding利用一種稱為template table,這種table也有定義好的schema只是它是放在template中,這個template會用來create一個或多個以上的table 而這些table會有targer table name與table suffix這些資訊。 target table name就跟在create BQ 的table一樣的table名稱,但 table suffix在create table時會有一些不同。
Streaming Inserts
上面提及的都是Batch loading. BQ也支援streaming insert。但BQ是一個 Data warehosue的solution, 它還是適合analytical的作業而不是transactional作業。
streaming insert提供的是一種best effort de-duplication. 當我們insert每一筆資料(row)時會我們需要對每筆資料有"insertID"來確認資料不會有重複的狀況。但如果該筆資料沒有insertID的話,哪BQ就沒有辦法偵測是不是資料有重複。如果有使用insertID並使用de-duplication功能,哪麼每秒鐘只能寫入100MB資料並且小於100,000 筆row。如果de-duplication沒有enable哪insert資料就可以拉到每秒1GB並且是低於1,000,000筆資料。
使用template tables的好處是你不用預先create全部的tables。例如你有一堆的火災感測器 device每一個device都要有一個table,你可以把每個火災感測器 device的辨識ID當成是suffix ,當第一筆資料進來資料 table會從template自動被create.
所以用Standard SQL來作wildcard的table name來查詢會變得很容易。例如你的table name的命名規則是 ‘fire_device_’ + <device_id>, 哪這一堆device的名稱就可能可以是 fire_device_001, fire_device_002, fire_device_003等。你就可以用where 語法來作查詢全部的devices,範例如下
FROM ‘fire_project.fire_dataset-fire_device_*’
但wildcard不能使用在view or external tables.
Monitoring and Logging in BQ
BQ的相關監控是使用股哥 stackdriver的監控服務。Stackstriver Monitoring提供效能量測,像是query counts and time. Stackdriver Logging 是用來追蹤events,像是running job or create table. Stackdriver monitoring 監控一些以下的維運面的監測資料
你可以在stackdriver monitoring上建立dashboard來追蹤關鍵的效能指標,像是跑最久的查詢作業跟95% query time.
stackdriver lgooing追蹤的events其實就是log entries。Events 有 resource type (project or datasets)跟type-specific attributes, 像是storage events的location. 可以追蹤的指標如下
 不明
不明
