這一篇我們會介紹GCP託管的資料處理(運算資料)的服務,例如App engine, Cloud Functions, Dataflow. 如何使用GCP的監控機制Stackdriver(metrics/logging/trace)來監控整個資料處理的infrastructure效能。
啟用與調整 Processing Resources
GCP有多種的processing resource. 這一篇我們將它們分成兩個種類,分別是server-based and serverless resource. Server-based resource 基本上就是你需要指定要使用的VM或是cluster; serverless resources則是不用管這些底層的資源管理,但還是需要設定configuration.
GCP的Server-based有以下服務
GCP的serverless 的服務如下
啟用與調整 Compute engine
Compute engine可以使用單一instance 或是一群instance(instance groups).Instance groups可以是託管式或非託管的。 Managed instance groups(MIGs)是包含著一群完全相同設定的VM; 非託管式的insatcne groups怎允許有著不同設定的VM, 但除非有特殊需求我們應該盡量的使用託管式VM。因為這一些在託管式方式產生出來的VM都是透過一個instance template所產生的。
提供單一的 VM instances
compute engine的基本單位就是Virtual machine. 我們可以使用console/command-line SDK/REST API來產生,但不論用哪種方式我們都要只指定機器一些參數,這些參數包含以下
此外我們還可以加上一些額外功能,像是Shielded VMs(security 功能)或是加GPU or TPU(tensor processing units).當VM關機時你可以對其做硬體規格的調整。
啟用Managed instance Groups
這邊我們所需要管理的是單一個logical resource, MIGs有著以下好用的properties:
在MIGs裡定義這些VM instance的參數稱為instance template(檔案型式)。這個template可以用gcloud的方式產生出來,例如我們要用gcloud產生一個machine type是 n1-standard-4, OS是Debian 9,250G boot disk
gcloud compute instance-template create jason-template
— machine-type n1-standard-4
— image-family debain-9
— image-project jason
— boot-disk-size 250GB
而當我們要用這個template來產生VM時的command 如下
gcloud compute instances create jason-vm — source-instance-template=jason-template
當然以上的作業也都可以在GCP的console中完成。
當我們在create instance group時要明定是要綁定哪一個 instance template,同時指定當CPU的使用率達到了某個程度後就會自動的加instance進去。然後也可定義instance 的數量最多能有幾個,當然也可以定義最小數量。為了避免insatnce 的數量的變化頻率太高我們也可以調整cooldown 的週期時間,cooldown period是讓GCP有時間去收集效能資料。這是因為從機器開機到完全ready能開始服務是需要時間的,在開始服務之後再來計算工作負載後效能資料才比較準確。
調整compute engine resource達到剛好的需求
該用sigle VM還是instance group則取決於需求,像是開發或測試環境啟用單一的VM就不會有浪費資源的狀況。而若是production環境則必須考慮到HA還有工作負載,這時選instance group是比較合理的做法。
instance group其中一個好處是當工作負載變大時它可以有autoscaling的功能。而instance group的autoscaling是屬於scale out(horizontal scaling)的方式。當然也有另一種的scaling方式: scale up(vertical scaling),不過這通常需要機器停機。而就要將Application or Services移動到其他VM上。
啟用與調整 Kubernetes engine(GKE)
GEK是一個託管式服務。GKE工作負載越大container的數量就越多,與VM不一樣的是它的overhead是小於VM的並且它對resource控制的精細度是優於VM的。
Kubernetes(K8s) 架構概觀
k8s cluster有兩種的instance type: cluster masters and nodes. Cluster master運行的控制整個k8s cluster的核心服務: controller manager, API server, scheduler, 與etcd。 Controller manager運作的是管理k8s abstract components的服務,像是deployments and replica sets. Application運行在k8s時是使用API server來呼叫master。 Scheduler是負責決定Pod要跑在哪裡。etcd則是分散式key-value的資料庫,是儲存cluster內的所有狀態資訊。Nodes則是實際處理工作負載;它是用 compute engine 的MIGs來架構底層。
K8s是一種abstractions, 這種方式可以管理到cluster裡的 containers, Applications, storages services, 一些重要的運作components如下
Pods是K8s的最小單位,它可以包含一個或一個以上的container。通常是一個Pod一個Container.但如果有一個以上的container,哪麼這個Pods裡的container關係就是tightly coupled。例如,一個Pods裡的一個container負責資料的extraction, transformation, and load process而另一個container負責資料的解壓縮與資料格式變更。會將多個container放在一個Pods裡的原因只有一個,它們各自的功能是高度相關的而且會有相似的scaling與lifecycle的特徵。
Pods被部屬到nodes是靠scheduler來完成的。它們通常被部署在groups 或replicas中。這可以讓我們的Application/service具有HA,因為Pods的特性是臨時性(ephemeral)的。可能會因為運作不正常或底層機器有問題而會消失,k8s則會監控這些狀況。因為Pods會有多個replica,所以即使其中一兩個Pods有問題後就被消除掉也不會中斷服務。因為k8s會根據定義好的Pods的數量再長出新的Pods.也因為replica的特性,當工作負載變大時Pods的數量就可以自動增加以應付工作量。
既然Pods的特性是臨時性(ephemeral)的,所以當有新的Pod或有舊的Pod被移除我們就需要一種機制來知道要去探索那些消失那些長出來了。K8s使用 service abstraction來達到這個目的。 Service是一種abstraction伴隨著穩定API endpoint與固定的IP. Application 使用service來跟API endpoint溝通。Services會持續追蹤與它關連到的Pods, 所以當有外部呼叫到Service時,它就可以將這個呼叫轉到有正常運作的Pods.
ReplicaSet是一種controllers,它可以控制pod 的replica數量。通常都是附屬在deployment中。而deployment是一種higher-level概念,它通常有管理到ReplicaSets與提供宣告式updates. 每一個Pod在deployment被create是使用相同的template,這個template定義了如何來運行Pods. 這個定義稱為pod specification.
k8s的deployments可以設定你想要多少數量的pod運作。假若實際運作的數量跟你規定的有落差 — 例如因為底層的機器壞了所以上面的Pod也消失了,ReplicaSet就會自動補上或刪除到你規定的數量。
Pods有時需要使用到persistent storage來儲存運算過後的資料,不過由於Pod的特質是臨時性的(ephemeral),所以比較好的作法還是將Pods與persistent storage分離。在K8s中 PersistentVolumes是提供給Pods做永久性資料儲存的地方。但PersistentVolumes比較像是一個硬碟還沒分割磁區狀態,但Pods真的要用到儲存資料時我們必須再從PersistentVolumes分隔一個邏輯磁碟區PersistentVolimeClaim出來。
Pods的特性從上面的描述來看就是一個stateless的applications, 不過當狀態是被Apppication所管理的話哪麼stateless的特性可能就會讓Application 的功能有問題。所以K8s提供了StatefulSets abstraction使Pods的狀態是stateful並且這個具有statefule的pods會有unique identifier. k8s 使用這些來跟踪哪些client端正在使用哪些 pod 並保持它們配對.
Ingress可以控制external access to service到k8s cluster內部的object。Ingress controller必須是運作在cluster中才能使Ingress 功能是正常運作的。
啟用一個 K8s engine Cluster(GKE)
你可以用GCP的console/ command line / REST API來啟用一個 k8s engine cluster.下圖為一個用console的範例來create 一個GKE cluster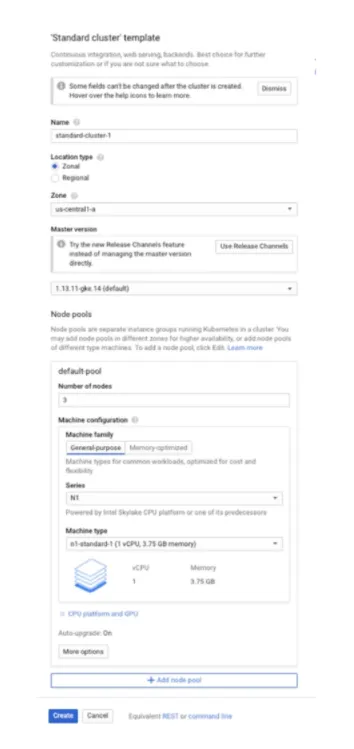
當我們create一個cluster時我們需要只指定 cluster name, 然後這個cluster是要運行在單獨一個zone或是多個zone, 然後GKE的version是多少跟設定node pools. 如果是用command line的方式範例可參考如下
gcloud container clusters create “jason-kao-1”
— zone “asia-east-1a” — cluster-version “1.13.11-gke.14”
— machine-type “n1-syandard-1”
— image-type “COS”
— disk-type “pd-standard”
— disk-size “100”
— num-nodes “5” — enable-autoupgrade — enable-autorepair
用coomand line的方式create cluster使已 gcloud container cluster create的命令列開頭. 上面的command line我們指定了 zone, cluster versions, machine type, disk configuration 與在這個cluster有多少的nodes. 最後的autoupgrade與autorepair則是option.
Node pools是一個VM的集合,這個集合是由MIGs(managed instance group)來管控的。既然是由MIGs來管控的,哪麼裡面所有的VM的規格設定都會是一樣的。如果你沒有指定或命名其他pool,哪default pool就會被使用。create不同pool的好處在於你可以用不同的machine type來運行你要的application, 例如web service可以run在machine type比較小的而Redis cache可以run在比較大台的machine(所以可以create另一個pool).
當有job被submit到 K8s時, scheduler會決定哪一個或哪一些node是有資源可以run這些Pods的。當然你也可以指定那些Pod要run在哪一個node上(若你確定該node資源是足夠的),這在K8s abstraction稱為taints. 通過將tainrs分配給node pool並將taints的tolerance分配給 Pod,我們可以控制 Pod 何時運行。
調整Kubernetes engine resource達到剛好的需求
在K8s中有兩種方式來達成資源調整,一種是scaling application另一個是scaling cluster本身。
Autoscaling Applications
你的Application可以靠著指定有多少個replicas運作,replicas可以根據你workload的需求來增加或減少replicas. 這個可以自動也可以手動,手動調整可以使kubectl這一個command 來調整。這裡樣說明一下,kubectl是用來控制k8s 的component,而我們剛才create k8s cluster的command gcloud container是用來控制 kubernetes engine的。
假設我們要用kubectl來調整replicas,以下為一個示範的範例
kubect scale deployment jason-kao-1 — replicas 8
另外你也可以永久性的調整這個參數。可以到deployment的YAML檔修改並再次部署這一個deployment.
另外我們也可以根據CPU的負載自動稱加Pod, 例如我們定義Pod的數量最少是兩個最大是10個,只要這些Pod的平均使用率高於70就會自動增加直到加到10個Pod為止。
kubectl autoscale deployment jason-kao-1 — min 2 — max 10 — cpu-percent 70
Autoscaling cluster
剛剛我們的autoscaling是在cluster裡面的Application.萬一要是底層的資源不夠呢?也就是底層的VM資源不夠需要加VM呢?
Cluster Autoscaling的設定會是在node pool level中。當你create pool時,你可以指定在這個pool中最小與最大的VM數量。之後autoscaler會根據resource request(注意:不是根據真實使用量)來調整VM的數量。假若是在node pool裡的node數量導致Pod被pending,哪麼node的數量就會自動的增加上去直到達到你規定的數量。若是之後Pod減少了需求沒哪麼多,node的數量也會自動在減低下來。
在GKE的預設中,GKE會假定所有的Pod都可以被restart在其他的node上。架設你的Application沒有辦法應付這一種短暫的中斷,哪麼你這一類的Application就會建議不要使用autoscaling這一種功能。另外若cluster是運行在跨多個zone並且有多個MIGs,autoscaler會嘗試在scaling up時做平衡資源的工作。
底下為一個當我們create 一個cluster時指定autoscaling的參數範例
gcloud conatiner clusters jason-kao-1
— zone asia-east1-a
— node-location asia-east1–a, asia-east1–b, asia-east1–c
— num-node 2 — enable-autoscaling — min-nodes 1 — max-nodes 6
Kubernetes YAML 設定檔
當然GKE也支援一般Kubernetes會使用到的YAML檔案來部署你的Application,以下為一個使用YAML檔來部署有三個replicas的Nginx server範例
啟用與調整 Cloud Bigtable
Cloud Bigtable 是一種託管式的wide-column NoSQL DB,用於需要high-volume、low-latency random write的Application(例如 IoT Application)和analytic use case(例如存儲用於訓練機器學習的大量資料)models。 Bigtable 有一個 HBase interface,因此它也是在 Hadoop cluster上使用 Hadoop HBase 的一個很好的替代方案。
啟用Bigtable instances
你可以用GCP的console/ command-line SDK/ REST API來啟用 bigtable instance。當啟用bigtable insatnce時我們需要指定instance name(instance ID)/ instance type/ storage type / cluster specification.
這個instance type可以指定為Production or development. Production instance最少需要三個node;而development只要一個node即可但也因為這樣就沒有HA的功能。
Storage type 有兩種, SSD or HDD. 如果需要low-latency I/O就需要選SSD。會選HDD就是你有費用上的考量,但HDD效能就會不太好。
使用command-line來create bigtable的範例可參考如下,這個範例我們會create一個名為 jason-kao-1的 production instance並且底層會有8個node, cluster使用SSD這個cluster位置會在台灣region.
gcloud bigtable instance create jason-kao-1
— cluster= jason-kao-1
— cluster-zone=asia-east1-a
— display-name=jason-kao-1
— cluster-num-nodes=8
— cluster-storage-type=SSD
— instance-type=PRODUCTION
Bigtable本身有一個command-line工具稱作cbt. 可以用來create 多個bigtable instance, 範例如下
cbt createinstance jason-kao-instance1 jason-kao-instance2 jason-kao-instance3 asia-east1-a 8 SSD
在我們完成create insatnce之後有些參數我們可以事後調整如下的參數
Replication in Bigtable
當我們使用多個bigtable cluster時,我們可以使用replication(primary-primary configuration with eventual consistency)功能來將資料同時寫到多個clutser中. BigtableZ可以support到4個replicated cluster,所有的cluster可以在不同的zone甚至是不同的region中。但是如果是在不同的region時,你就必需考量到這樣會增加資料的replication latency; 不過這樣卻也能增加當某一個region failure時的HA功能。
雖然會有write latency不過卻同時增加了read 的效能。因為當有大量的資料要寫入某一個cluster時,我們可以read另一個cluster的資料以免所有的loading都在一組cluster上。
Bigtable允許關於data consistency的設定調整。預設上bigtabl的提供的是eventual consistency,意思是資料需要一段時間才能在整個cluster的node中完成同步。但假如你的Application需要讀取到最新的一筆資料,你就需要設定為read-your-writes consistency. 若所有使用這個cluster的user都需要讀取到一致性的資料時,我們就需要設定成為 strong consistency. 這個設定將會把所有的read 導到同一個cluster(這個設定要與read-your-writes consistency一起設定)。但其他的cluster只會被使用在當read的cluster failure時使用到(failover only)。
啟用與調整 Cloud Dataproc
你可以用GCP的console/ command-line SDK/ REST API來啟用 bigtable instance。當啟用 Cloud dataproc resource時,我們需要指定 name/region/zone/cluster mode/machine type/ autoscaling policy.
Cluster mode 會決定 msater node的數量與可能的worker node數量。如果是Standard mode, 哪master node就會只有一個而其他的就會是worker node. Single mode則是只有一個master node而沒有worker node. 而HA mode則會有三個master nodes與一定數量的worker nodes. Master nodes與worker nodes的設定是分開的。這兩種的node都需要指定machine typr/ disk size/ disk type.
以下為一個用command line 來create dataproc cluster的範例
gcloud dataproc create jason-kao-1
— region asia-east1
— zone asia-east1-b
— master-machine-type n1-standard-1
— master-boot-disk-size 500
— num-workers 6
— worker-machine-type n1-standard-1
— worker-boot-disk-size 500\
完成create cluster後worker node可以被事後調整(但maste node設定無法再更動了),像是preemptible node的數量。我們也可以用autoscaling policy來自動調整worker nodes的最大數量與scale-up/scale-down rate.
Cloud Dataflow的設定
Cloud dataflow執行的是streaming and batch Application(像是Apache Beam runner). 我們可以指定是pipeline options. 可以設定的參數如下
我們還可以指定在執行pipeline時的使用的workers數量(設定成預設值),架設我們在設定時有多餘的worker可使用,哪workload的實行效能將會好非常多。另外我們如果要run的batch job需儲存大量的資料在workers(VM)裡時,我們可以定義disk size(boot disk)。
Cloud Dataflow是一個全託管的服務,通常我們不需要對它指定machine type這一類的資訊,但如果我們需要再客製化這一類的環境我們是可以指定machine type and worker 的disk type.
 不明
不明

 iThome鐵人賽
iThome鐵人賽