這一篇我們會將焦點放在機器學習(後面簡稱ML)的概念上。如ML的一些術語與核心概念。ML是一門廣泛的學科在不同的領域在有著不同的應用。在這裡我們是從High Level角度來看google的ML。
機器學習催生了一種全新的服務開發方式。 ML演算法不是手動編寫邏輯,而是使用資料來識別可用於預測值、分類對象和向客戶推薦產品的模式。在本文中我們從High-level的角度下分別討論四個重點簡單概念
三種ML演算法
傳統上ML演算法被分類為三種,它們分別是監督式,非監督式與強化式。
監督式學習
這通常被用來執行預測工作。當ML模型被用於預測離散值,也被稱為classification model。而當ML模型被用於預測連續值,被稱為regission model。
Classification 分類
監督式演算法是從範例(example)來學習。舉例,參考下表格資料,這是有著不同種類動物的資料。我們想要建立一個ML模型來預測這個動物是不是哺乳類,我們使用了下面的範例資料。監督式演算法可以使用了其中一個column的資料來呈現預測值。我們使用Mammal欄位來做為預測值。在ML的術語中這個欄位稱為標籤(label)。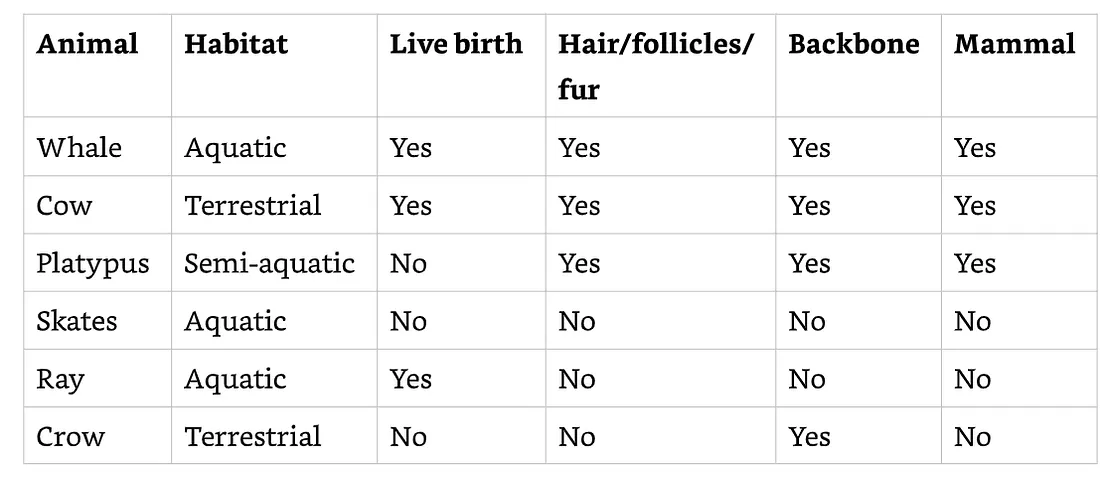
最簡單的分類器稱為二元分類。預測動物是否為哺乳動物的分類器是二元分類器的一個例子。更多實際的案例是使用二元分類器來預測金融交易是否屬於詐欺交易,以及使用有電腦視覺的ML模型來預測醫療影像中是否惡性腫瘤的存在。
而多元分類器則是會使用含兩個以上的值來進行預測。讓我們再回到上面動物表格資料的例子,多元分類器會把habitat再加入分類的特徵值中。若這張表格的資料不夠做多元分類我們可能會再把其他的資料因素加入。
其他的監督式學習還又SVM(支援向量機),決策樹,與邏輯迴歸。
SVM呈現一個多維空間的例子。一個簡單的例子是資料點存在於一個三個維度的空間。SVM可以在這個三維空間內找到每個資料類別之間的邊界,並且使這些類別的距離是最大化的。下圖顯示了一個分隔兩組資料的平面範例。 如果在空間中添加了一個新資料點,則可以根據它位於平面的哪一側對其進行分類。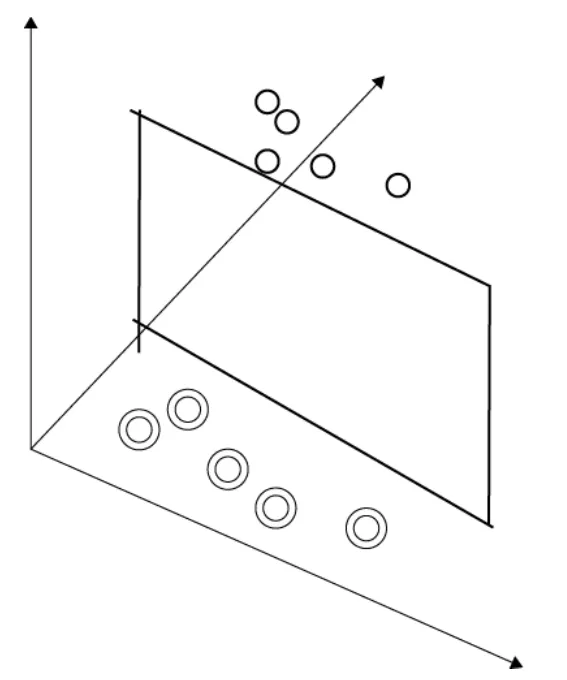
一般來說,當特徵是數值時,我們可以想像每一個實例(instance)是在一個 n-dimensional 空間中,這個n是指這個數值的特徵數量。根據位於空間中的y 資料點來思考實例可以為ML演算法提供一些有用的概念。決策邊界(decision boundary)是能夠分類這些實例的一條線,一個平面,或是超平面。
決策樹是根據特徵進行一連串的決策,總交易數量或一篇文章中的經常出現的特別文字。下圖是一個使用決策樹用來分類動物的例子。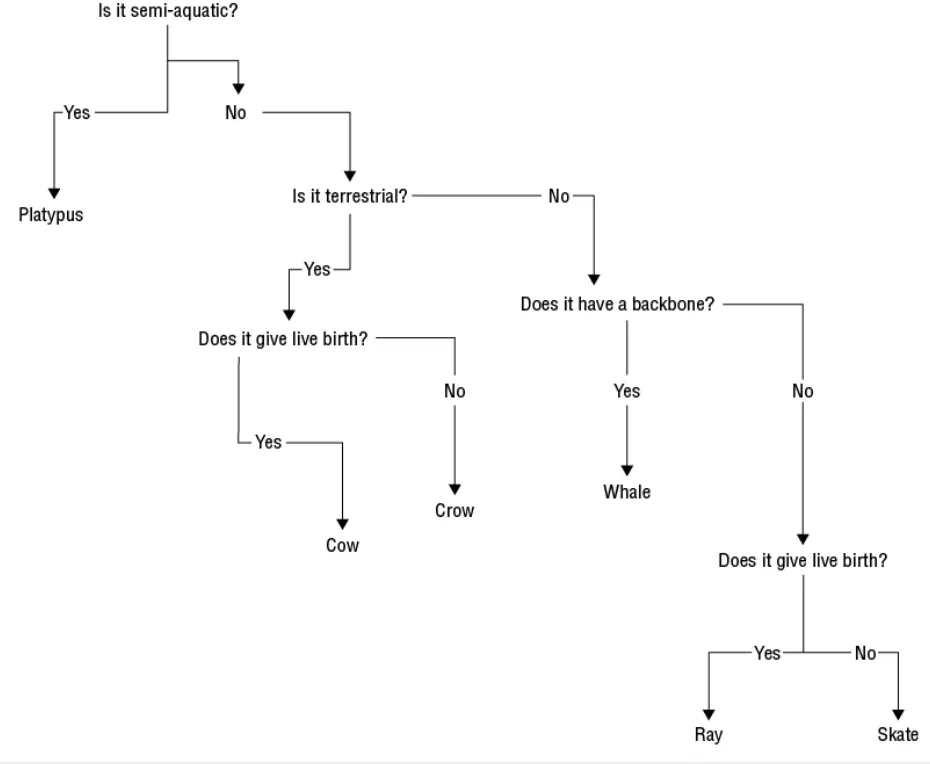
邏輯迴歸則是基於邏輯函數的統計模型,是一種會產生一個 S曲線也稱為sigmoid並被使用在二元分類上。下圖為一個使用邏輯迴歸來進行二元分類的範例。
Regission迴歸
監督式演算法也可以被使用在一個數值上。這些也被稱為迴歸演算法。具如下資料表格的例子,這個資料顯示了人們尋找工作平均需要花幾個月時間才能找到。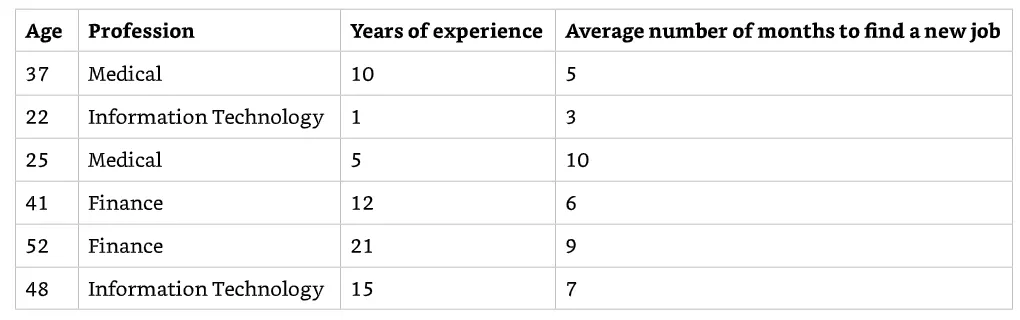
迴歸演算法可以映射一組變數到其他的連續變數。例如,可以使在預測客戶終身價值,可以用在一些特定運作參數的設備來預測設備的哪一個部分即將損壞,或是預測在未來的股票市值。
簡單線性迴歸模型使用一個特徵來預測一個值,例如用年紀來預測身高。如下圖所示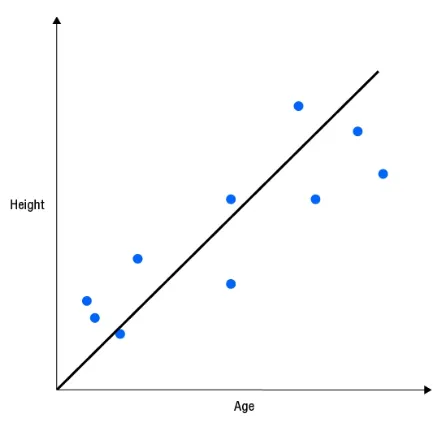
簡單非線性迴規模型使用單一特徵但對應一條非直線資料。例如一個非線性迴歸模型也許對應一個二次曲線(曲線中有一個彎曲)。多重非線性迴歸模型就使用兩個或以上的特徵來對應曲線中的資料。
非監督式學習
簡單來說就是我們不需要預先對資料設立標籤(labels),把資料丟進去,它就會幫我們找到資料的模式。兩種常見的非監督式學習是clustering(集群) 與anomaly detection( 異常偵測)。
非監督式演算法學習的是沒有任何預測標籤的資料然後從中去辨識較突出的資料特徵,像是groups 或clusters,與在資料流中的異常。下面的動物資料表格可以讓我們把類似的動物集群起來。不同監督式學習,我們不需要有一個特徵或標籤來進行預測。在這個範例中,集群演算法用了Habitat把資料分成三個群組(aquatic, semi-aquatic, terrestrial)。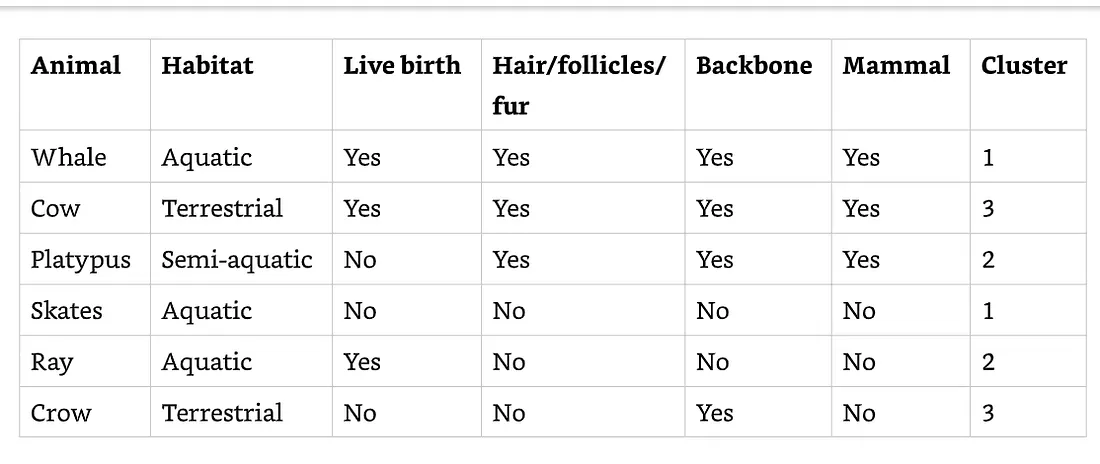
Clustering, 或說是集群分析是一個將基於共同特徵來分群的流程。
K-means clustering是一種將資料集切分成 k個partation的技術並將資料分到這些partation中。它的工作原理是最小化集群(cluster)中資料之間的差異。另一個集群演算法是K-nearest neighbor 演算法,它將 k 個最近的實例作為輸入,並根據最近鄰居的最常見類別為實例分配一個類別。
異常偵測
這是在資料中辨識未預期到的模式。異常來自於型式多樣。Point anomalies是離群值,像是在金融交易中有著不正常的大量金額。 Contextual anomalies是一個資料中有著其他特徵的異常模式。例如,在冬天時期買泳衣。Collective anomalies則是一組資料中的異常,像是一張信用卡在很短的時間內在刷了很多筆的交易,但是這些交易卻是分散在各個國家。
異常偵測演算法使用一種density-based的技術,像是 k-nearest neighbor, cluster analysis與離群值偵測。
強化式學習
這是一種使用agent來跟環境互動並且基於從環境的reward來調整其行為。這種學習方式不是依靠標籤的做法。
強化式學習是建模在一個環境中的一組agents,一組動作, 與採取特定行動後從一種狀態轉換到另一種狀態的一組概率。在一個動作之後從一種狀態轉換到另一種狀態後給予獎勵(reward)。
強化式學習適合用在當我們要解決的問題需要在短期與長期目標平衡兩個目標並做出取捨,人類本身就一個使用強化式學習的例子。不過卻會受到情緒左右這種理性的強化式學習應有的行為。
Deep Learning深度學習
這是基於我們上述所講的傳統三種ML演算法以外的新型態。深度學習不是一種問題,而是一種解決 ML 問題的方法。它可以被使用在我們傳統三種ML演算法中。
深度學習使用人工神經元的概念作為建構區塊(building block)。 這些神經元或節點具有一個或多個輸入和一個輸出。 輸入和輸出是數值。 一個神經元的輸出用作一個或多個其他神經元的輸入。 一個簡單的單神經元模型被稱為感知器,並使用感知器算法進行訓練,通過在彼此之上添加神經元層,我們可以構建更複雜、更深的網路,如圖下所示。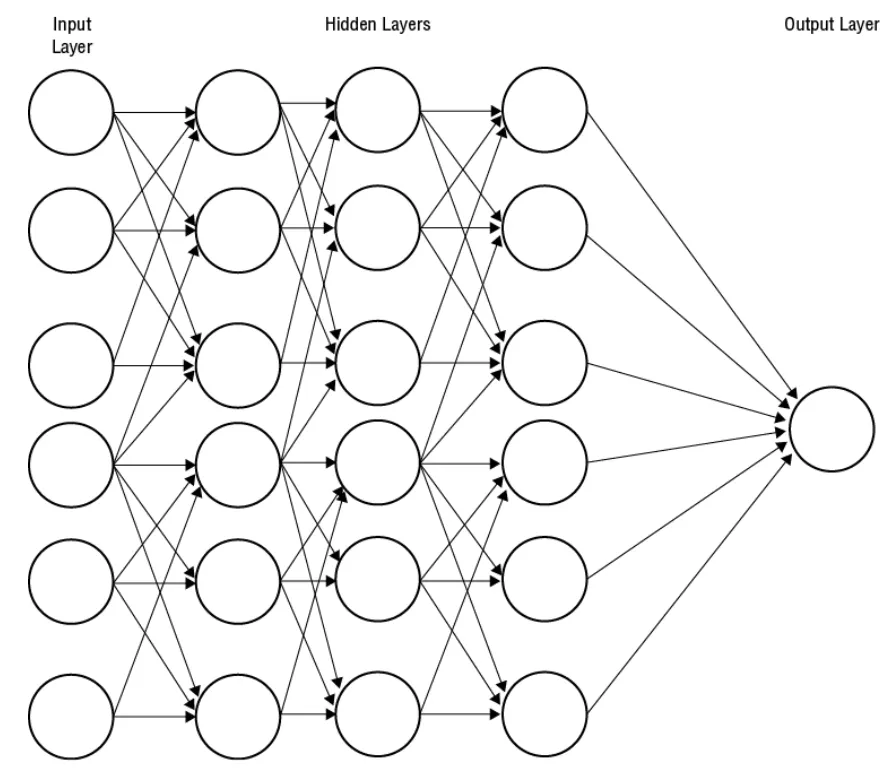
第一層是輸入層。這是特徵值一開始進入神經網路的地方。中間層稱為隱藏層(hidden layer)。最後一層則是輸出層(output layer)。輸出層的節點輸出就是整個模型的輸出。
在訓練深度學習模型時,會調整每個節點中的參數,以便通過網路發送values或信號,輸出節點會產生正確的值。一個神經網路最重要的特徵就是它們幾乎可以學習任何從輸入到輸出的映射函數。
這裡有一些我們可以熟悉的深度學習特有的術語。每個神經元在網路中都有一組的輸入跟一個輸出。從輸入映射到輸出的函數稱為activation function(激勵函數)。一個常用的激勵函數是ReLU(rectified linear unit)函數。當輸入的加權的和等於或小於零時, ReLU 會輸出零。而當輸入的加權的和大於零時,ReLU則輸出該加權的和(sum)值。
其他的激勵函數包含TanH(hyperbolic tangent)函數與 sigmoid 函數。這兩種都是非線性函數。如果神經網路使用線性激勵函數,它將可以組合所有的線性激勵函數進到單一線性函數中,但是不可能組合非線性函數。由於神經網路使用非線性激勵函數,因此它們能夠建立對非線性關係建模的網路,這就是它們如此成功地用於解決不適合使用線性模型解決的問題的原因之一。下圖為三種激勵函數的描述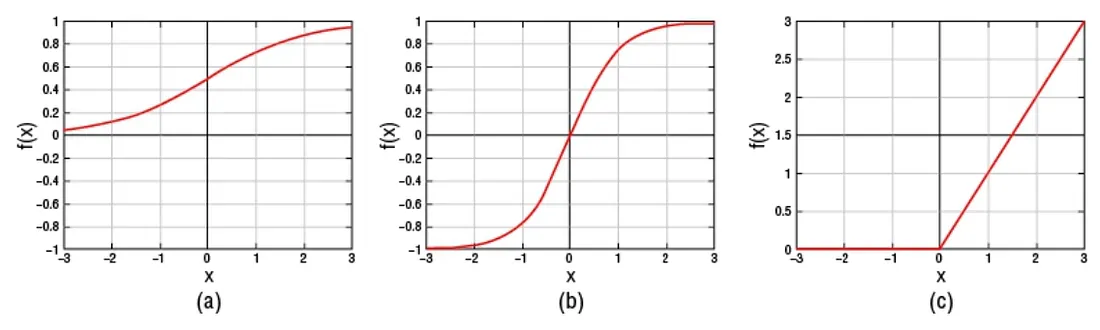
上圖(a)是sigmoid函數,(b)是hyperbolic函數,(c)是rectilinear unit函數
由於深度學習網路幾乎可以學習任何映射函數,因此網路基本上可以統一訓練資料和正確的回應。這是過度擬合(overfitting)的一個極端例子。即使網路不記住訓練資料和標籤,它們仍然可能過度擬合訓練資料。深度學習模型可以利用 dropout,這是一種正則化形式。在訓練期間,計算加權和(sum)時會忽略隨機數量的節點。
這模擬了從網路中刪除一個節點,實際上降低了網路的學習能力,並傾向於生成不太可能由過度擬合所產生的模型。
在訓練期間,預測的誤差通過layer傳播,傳播的誤差隨每一層遞減。在深度網路中,這會導致梯度消失(vanishing gradient)問題,即網路中的早期的layer需要更長的時間來訓練。ML研究人員研究了許多解決梯度消失問題的方法,最常見的解決方案是使用 ReLU 作為激勵函數。
ML模型工程
在整個建立ML model中,運用演算法只是其中一部分。要完成整個模型還需要加上好幾個步驟才能完成。一旦模型開始正式運作在生產環境,它必然要能夠規模化,監控模型的效能,與重新訓練模型。
模型的訓練與評估
以下為要建立一個模型進入生產環境所需要的以下步驟:
資料收集與準備
資料收集的的方式與其他的資料流水線(Data Pipeline)是相似的,但是準備過程有點不太一樣,因為在資料準備階段是要將原始資料映射成適合ML演算法的格式或是可以被用來訓練ML模型。
ML演算法有著特殊的需求條件。例如,深度學習網路需要所有的特徵(feature)都轉化為數字。當特徵是連續值時這不會是問題,像是銷售總額或客戶購買自上次購買商品到現在的天數。當我們是使用分類型的vaule時,商品的種類,銷售地區等我們可以用轉化成數字的方式呈現。
例如,我們的銷售區域可能分為北部,中部,南部,東部。我們就就可以用數字來代表,用1 代表北部,2代表中部,以此類推。這種使用方式是當數字之間的幅度差異不會影響模型訓練時才應使用此映射。當數值之間的大小很重要時,我們應該只用one-hot encoding。
One-hot encoding 是將類別型的資料(如銷售區域的例子)對映成二進制的方式呈現。例如北部是[1,0,0,0] , 中部[0,1,0,0], 南部[0,0,1,0], 東部[0,0,0,1]。這種方式通常使用在包含深度學習網路的神經網路。
另一種資料準備階段的技術是 bucketing,也叫做binning。bucketing是一種將連續型的值轉化成一個"區間"的值, 而它用於減少微小觀測誤差的影響。例如,一個IoT設備回報天氣的相對濕度是從1到100。但是,出於我們的目的,我們可能希望指出測量值屬於 10 個buckets中的哪一個,例如1–10,11–20,21–30依此類推。一個相關的概念是 quantile bucketing, 這是將instances分配給buckets的過程,以便每個bucket具有大致相同數量的instance。 當在小範圍內有許多insatnce並且許多instance分佈在一個大範圍內時,這很有用。
我們也許需要處理原始資料的遺失值或異常值。當資料有遺失時,我們可能會進行以下方式處理
而異常值也可以用一樣的方式來處理,像是我們的values是從1–100,但我們偵測到105這個數值。
特徵工程
這是一個辨認資料中的哪一個特徵是能夠幫助我們建立模型的流程。它同時也能讓我們從資料中既有的特徵衍生出新的特徵。例如,一個資料模型利用過去30天/60天/90天的總購買花費來預測客戶會到競爭者商店購買東西而不會從我們的商店購買。這三個特徵本身可能無法預測,但過去30 天花費的金額與過去60 天和過去 90 天花費的金額的比率是兩個額外的特徵,卻可以提供更多訊息。
我們在前面的三種演算法的章節有提到Recall,某些演算法可以利用線,面,超平面來劃分出資料的種類。但有時候這些使用原有的特徵來劃分這些資料是不可能找出這些資料分界的直線/面/超平面。在這個狀況下我們就需要使用特徵的cross products。 Cross products有兩種: cross products of numeric values 與 使用one-hot encoding的cross products。
cross products of numeric values是一種將values相乘的作法。例如,我們有一個客戶15天前買了價值100元的商品,哪cross product 就會是100x15=1500。這種類型的cross product呈現的就是非線性特徵的資料。
one-hot encoding的cross products則更常見的型式。剛剛提到one-hot encoding是一個二進制,所以回到剛剛的銷售區域例子,假設客戶的銷售區域是在北部,編碼為[1,0,0,0],而偏好的語言是英文,編碼是[0,0,0,1]。而我們將這兩個數字相乘就會得出一個只有一個位元是1其他15個位元都是0的數值。
另一種特徵工程則是消除你知道你不會用來拿來預測的特徵。也許還會移除一些與其他特徵高度相關的特徵。我們也可以使用非監督式學習來協助進行特徵工程。像是Clustering 與維度縮減(dimension reduction)。
在考慮對相關實例進行clustering或分組時,將資料視為空間中的點也很有用。centroid是cluster的均值或中心。當我們使用 K-mean clustering時,我們指定 k,即cluster數量。如果 k 設置為 5,演算法將找到 5 個centroid,每個cluster一個。這些cluster centroid可以用作特徵。
繼續使用空間推理方法,當我們將資料視為空間中的點時,我們通常將空間視為每個特徵有一個維度。這可能會導致大量的維度,進而導致訓練效率低下。在這些情況下,通常使用降維技術來生成一組具有較少維度的特徵。PCA(Principal component analysis)是一種降維技術。
有時,沒有足夠的資料來訓練模型。Data augmentation是通過轉換現有資料來導入人為資料的做法。例如,我們可以對圖像應用變換以創建用於訓練對象檢測模型的新圖像。
訓練模型
這一階段我們需要有訓練用資料來訓練模型。演算法會一次分析一個資料點然後update模型的參數。在某些狀況下,在update 模型的參數前先分析多個範例資料會比較有效率。這是靠使用批量(batch)。 批量是一群資料點並將它們做成一個單一的訓練迭代。資料點的數量多寡也稱為批量大小。
有些演算法可以靠一次分析一個訓練資料集來建立模型,而其他的(像神經網路),可以從多次重複使用訓練資料來得到效益。epoch是用於描述訓練演算法對訓練資料集的一次完整傳遞的術語。在某些ML演算法中,我們可以指定epoch的次數。這是一個超參數,是一個使用指定的epoch數量而不是讓模型學習它的參數。
神經網路訓練的一種簡單方法是,網路通過接受input、將每個input乘以一個稱為權重的值、對這些乘積求和,並將該結果用作稱為激勵函數的函數的input來進行預測。激勵函數的output成為網路下一層的input。這個過程一直持續到最後一層輸出它的output。該output與預期值進行比較。如果output和期望值不同,則這是個差異。這被稱為誤差。例如,如果網路輸出值為 0.5,而預期值為 0.9,則誤差為 0.4。
在這個例子中,網路產生了一個太大的數字,所以應該調整網路中的權重,使它們共同產生一個更小的數字。有很多方法可以調整權重,最常見的方法是根據誤差的大小調整權重。反向傳播(Backpropagation)是最廣泛使用的算法,用於訓練神經網路,它使用"誤差"和"誤差的變化率"來計算權重調整。調整部分的大小由稱為學習率(learning rate)的超參數決定。小的學習率會導致更長的訓練時間,但太大的學習率會超過最佳權重。
模型訓練通常從訓練資料集和生成模型的演算法開始。但也可以從經過訓練的模型開始並在此基礎上進行再次建模。這被稱為transfer learning。這種技術常用於視覺和語言理解,例如識別圖像中的貓或識別文章中的人名,可用於構建其他模型,例如狗的識別模型或識別文章中的地理位置名稱。
正則化是一組通過懲罰項的複雜模型來避免過度概括(overgeneralization)的技術,因此訓練傾向於支持不太複雜的模型,因此不太可能過度擬合。兩種正則化是 L1 和 L2 。 L1 正則化基於權重的絕對值計算懲罰項。 L2 正則化基於權重的平方和計算懲罰項。當我們希望不太相關的特徵的權重接近於零時,應使用 L1 正則化。當我們希望離群值的權重接近於零時,應使用 L2 正則化,這在處理線性模型時特別有用。
 不明
不明

 iThome鐵人賽
iThome鐵人賽