本篇文章我們將介紹如何處理與分析儲存在AWS 裡的資料。資料處理最重要的階段是資料流水線(data pipeline)與分析流水線( analytics pipeline)。AWS提供各種的技術工具讓我們來處理資料,後面我們會介紹 Glue, EMR,Redshift,Athena。這些技術工具會應因不同的場景或資料處裡型態而有不同的使用方式。
整個資料處理與分析要解決的大都圍繞在一些因素上,像是資料的大小,結構,處理速度的需求,SLA要求與skill level。資料處理與分析是一連串的流程 — 資料的”辨識、清理、轉換”,資料架構,從而辨別出有用的資訊,下定論,並支持我們的決策。下面我們來介紹不同的分析需求型態。
分析需求的型態
以下為五種的分析需求的作業型態
Batch Workload
這通常是查詢大量的”cold” data,並且可能花幾分鐘到幾個小時來分析。像是我們都跑日報,周報,月報等報表作業都屬此類。batch worload通過處理相同的資料會有一些效益存在,主要是能夠對部分的資料或半結構化或非結構化資料集進行處理。batch job作業範例包含了像Hadoop MapReduce jobs,這就非常適合處理大量的結構化/半結構化/非結構化的資料。而Redshift能夠使用SQL語法進行大量資料的轉換。
Interactive Analysis
這是一種具週期的分析作業,意思是我們會對資料進行實驗,而實驗是靠假設,確認其假設,與調整實驗過程來達到我們需要的業務目標。這一類的interactive analysis包含了 特設式查詢(ad hoc querying)。這一類的使用技術工具像是AWS Athena 與Apache Presto。
Messaging
這是Application-to-Application之間的溝通,主要是高速低延遲的資料傳輸處理。資料的低延遲是這一類最重要的處理因素像是 IoT message的資料處裡。
Streaming Workloads
這是擷取資料序列和回應每個data record增量更新功能的作業。這一類不斷輸入的資料像是量測資料(例如天氣),監控資料,稽核logs,GPS位置追蹤等等。這一類的資料會因為持續不斷匯入資料的速度而變得很大,但最重要的是如何能夠及時不斷的接收這些資料(沒有遺失任何一筆資料)並盡可能的快速做出回應。這一類的處理需求場景,像是詐欺偵測或即時推薦系統。使用的AWS技術工具有 Kinesis Data Streams 與 Kinesis Data Analytics。
streaming workload通常需要支援以下需求或條件
需要對半結構化data streams中的內容進行近乎即時的回應
通常需要相對簡單的計算
能夠使用workflow的方式來移動資料
適合用在大規模並且較難預測資料量大小
需要streams(ingest)工具將單獨產生的records轉換為較少的sequential streams sets
支援sequential streams與容易處理
有簡單的大規模擴展機制
AWS Athena
Athena是一個interactive querying services,其分析的資料是放在S3上。所以Athenta是一個分析的服務,本身並不儲存要分析的資料。它是serverless的。Athena支援 schema-on-read的概念,這個效用是在於現在我們的資料有越來越多是半結構化與多結構化的資料。它同時也支援ANSI SQL的功能語法,意思是這一個查詢語法可以被其他的分析工具所使用。Athena由於是serverless的所以如果query的資料量越大它的底層運算資源就會自行增長到所需要的處理量能。Athean也可以讓我們實行 cross-region queries。
Athena有著以下功能
Athena背後所採用的技術: SQL query 是Apache Presto,DDL功能則是 Apache Hive。
Apache Presto
這是一種開源的分散式 SQL query engine,專門用於低延遲與特設(ad hoc)的資料分析。Presto的資料處理量能從幾TB到PB等級的資料量。Presto具有跨平台的資料查詢能力。
Apache Presto是一種主從式架構(類似Hadoop或一些 MPP的DB),下圖為Presto的架構圖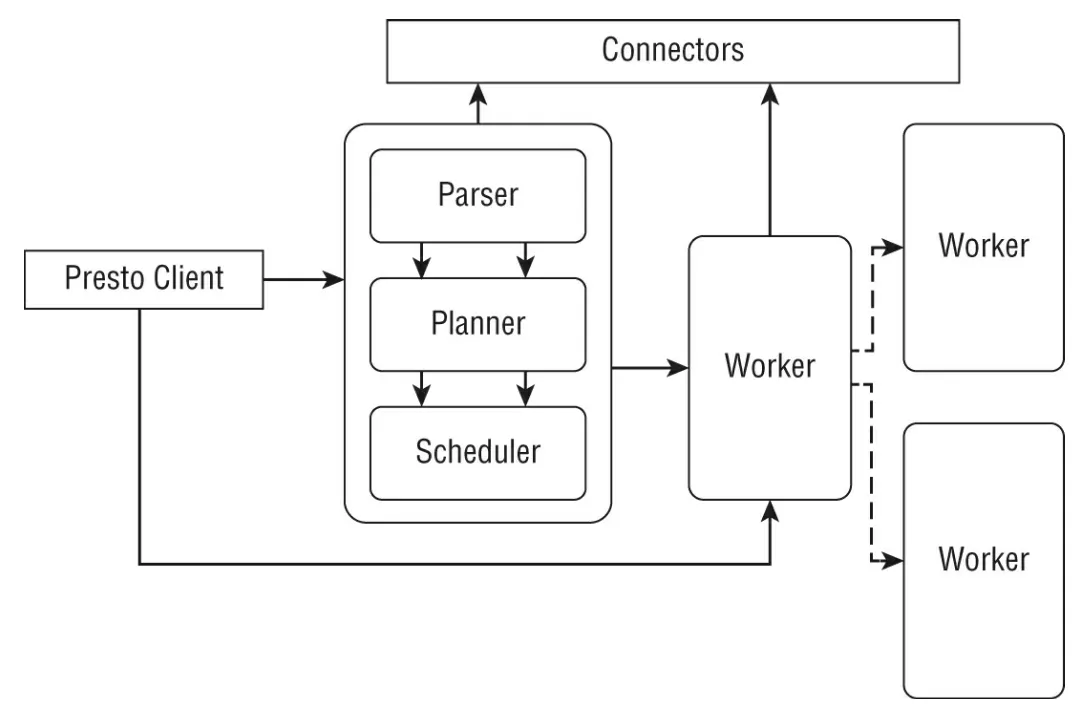
在上圖中的Presto架構中的主要元件有:
Coordinator:這使整個cluster的大腦部分。它會接收來自presto client的查詢要求。coordinator有三個資源子元件,分別是 Parser,Planner, Scheduler。
Worker:
負責在worker node上調度作業的組件。 worker node是 Presto 實際工作的主力。 它們能夠使用connector連接到data source。 coordinator負責從worker node獲取結果並將它們返回給client。
Connector:
Presto提供多種的連結器可以讓我們連接到不同的data source,內建的連結器有 Hive, Kafka, MySQL, MongoDB, Redsshift, Elasticsearch, SQL server, Redis與 cassandra。當然我們也可以客製化自己未被內建的其他data source連結器。
Presto能夠執行如此大量與快速資料查詢的原因在於它除了MPP DB有的功能外,還使用了 flat-memory結構來最小化 garbage collection。另外若我們使用 檔案格式為Parquest/ORC(Columnar format)則能得到更快速資料查詢(比起其他資料格式)。
當然我們可以自建Apache presto,不過若是我們沒有人也想用計次付費的方式來使用Apache presto,選擇serverless的Athena則是一種好的選擇。
Apache Hive
這一是要用在運行在Apache Hadoop的Data warehousing的功能。會產生這個功能是因為Hadoop主要是使用MapReduce來處理資料的,但這需要很好的Java技能與把資料處理問題轉成是 key/value pairs的想法。這對習慣使用SQL語法來處理資料的人產生的一些挑戰。於是Hive 應運而生,它將SQL語法轉化為MapReduce的框架來處理資料。
Hive支援的資料型態從簡單的integers, floating-point numbers, string, date, time, binary到 structs, maps(key/value tuples)與 arrays(indexable list)。支援的檔案格式有Apache的 Parquet 與 Apache ORC。
Athena 的使用場景
Athena適合用來分析logs,從web servers到Application logs都可以,它能夠對資料進行探索以此來了解資料與發掘資料的模式,之後可以用AWS QuickSight或其他BI tools對其進行ad hoc analysis。又或者在資料進入Redshift(data warehousing)之前query stage data。
在這裡要提一下Athena與AWS EMR的使用(後面會詳細講解EMR)對資料處理與分析的分別。AWS EMR提供不只SQL語法的處理(Anthena只有SQL語法),它還提供的其他的framework,像是Jive, Pig, Presto, Spark, Hbase與Hadoop。EMR適合用在我們要自行開發 Java/Python/Scala code在上面運行,意思是我們會比Athena (serverless)得到更多的控制權。
Athena的主要使用場景如下:
直到 2019 年 11 月,AWS Athena 僅限於使用managed data catalog來存儲有關 S3 中可用資料的DB和schema的資訊,並且在提供 AWS Glue 的region,我們實際上可以使用 AWS Glue catalog,這通常是使用 AWS Glue crawlers程序製作的。在非 AWS Glue regions, Athena 使用internal data catalog,這是一個符合 hive-metastore 的存儲。 Athena 的internal data catalog存儲tables和columns的所有metadata,具有HA功能,並且不需要我們來管理。這個catalog符合 hive-metastore,因此我們可以對 DDL 使用 hive 查詢。
2019 年 11 月,在 AWS re:Invent 之前,AWS推出了對自定義metadata存儲的支援,這意味著我們可以使用data source connector 將Athena 連接到任何選擇的metastore。Athena 現在可以跨 Hive Metastore、Glue catalog或任何其他federated data source掃描資料的查詢。
Athena的DDL, DML與DCL
Athena針對DDL(data definitional language)使用了Apache Hive。 我們要在Anthena中create table有以下幾種方式
我們之前提到Athena採用的是 schema-on-read的概念來產生schema,這樣就消除了load data或data transformation的需求。Athena不會修改我們在S3任何的資料。當我們create table時,我們同時也指向了資料實際的所在地。
以下為一個create table的範例
Athena透過SerDes(Serializer/Deserializer 是 Apache Hive 用於input和out以及轉換不同資料格式的interface)支援 JSON, TXT, CSV, Parquet與 ROC的資料格式。這種方式一樣用於來自S3的資料。
剛剛有提到Athena處理columnar 格式的資料(Apache Parquet與ORC)能取得極好的處理效能。這是因為資料的處理從row變成column,這種方式會減少需要處理資料的大小並且加強整體IO與CPU的需求。下表為同樣的資料內容以不同的資料格式儲存在S3所要花費的代價
對資料Partition
partition主要是對我們的資料做分區,這樣可以減少我們在實行查詢時scan到我們所不需要的資料量。partition用的是tables中的column,而且基於時間定義多級partition是很常見的。下表為一個比較表,比較有partition跟沒有的效能與代價。一樣的資料量大小一樣的SQL語法。
Athena Workgroup
我們有提到Anthena是以scan在S3的資料量來計費的,所以我們可以用Anthena來分隔不同群組或團隊的使用量。並且可以設定query資料量的上限。每一個workgroup可以有它自己的query history/ Data limits/ IAM policies/encryption setting。
Athena worgroups可提供以下的量測指標紀錄,像是
我們也可以訂義每個query的threshold,超過的話就會被取消該次Query。
Athena Federated Query
我們可以使用federated query這個功能去query資料在其他關聯式/非關聯式/object或其他自訂義的資料所在位置。這個可以讓我們的query engine與實際資料 是分開的。下圖為Athena的各種data source。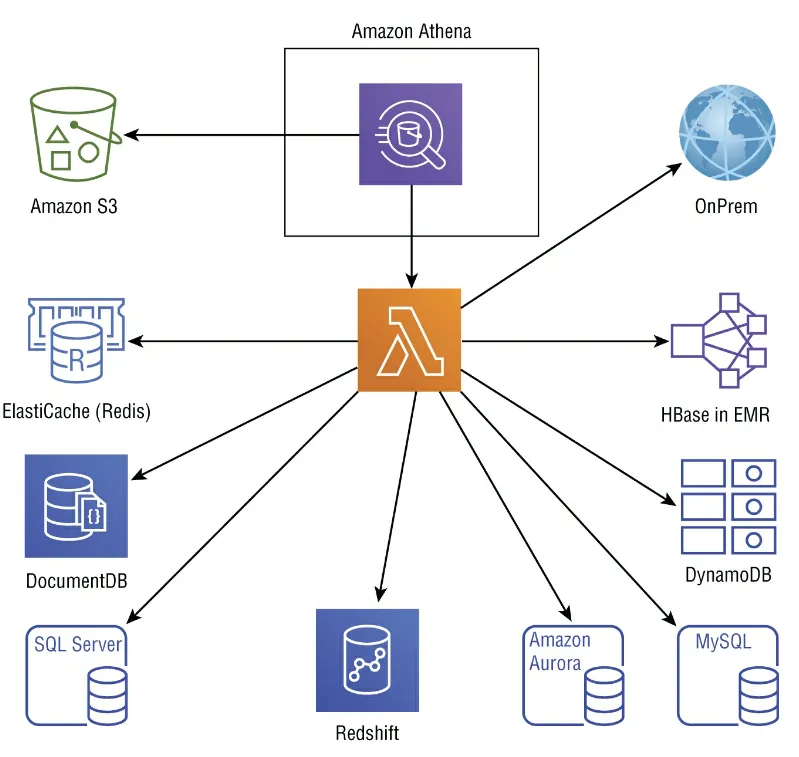
使用方式很簡單,我們只要deploy data source connector,註冊 connector,輸入 catalog名稱就可以寫SQL query去access data。
Athena 客製化 UDFs
我們可以建立客製化 user-defined functions(UDF)功能(就是一段處理資料的scripts)。這個功能主要是在資料的預處理或事後處理的功能,還有access control與在data access時訂出一些邏輯規則。我們在Athean query的select or filter 階段時可以加上我們訂出的UDF。UDF的主要功能有:
使用Lambda來執行UDF功能
支援 network calls
UDF invocation可用於query的select and(or) filter階段
Athean會優化效能,所以我們只要專心我們的scripts的業務邏輯
AWS EMR(Elastic MapReduce)
AWS在雲端上提供的一個大規模分佈式工作負載。使用的是開源專案像是Apache Hadoop、Apache Spark、Apache Hive、Apache Presto、Apache Pig等。
Apache Hadoop概觀
Apache Hadoop 是 Apache上的一個開源專案,它允許使用簡單的編程模型跨電腦集群分佈式地處理大型資料集。 它的設計考慮了線性可擴展性、高可用性和容錯性。 Apache Hadoop 是最受歡迎的開源項目之一,也是 AWS EMR 的關鍵部分。
Apache Hadoop包含了以下一些重要模組
Hadoop Common 這些是 Apache Hadoop 專案中支持其他 Hadoop 模組的common utilities。
Hadoop Distributed File system(HDFS) 這是Haddop的檔案系統,提供high throughput的資料存取並且會自動複製三份資料在cluster 的電腦群中。
Hadoop MapReduce Hadoop 最根本的預設資料處理框架,之後再發展出兩部分 YARN(resource handling)與MapReduce(processing)
YARN(Yet Another Resource Negotiator) 這是一個在 Hadoop cluster中調度(schedule)作業和管理資源的框架
Apache Hadoop 現今成為一種流行的資料處理框架,有望取代傳統的大規模資料處理系統,這些系統不僅效率低下,而且成本高昂。雖然該技術在規模和效能方面承諾了很多,但它的可用性還有很多不足之處。希望替換其傳統內部資料處理系統的一般企業正在運行許多不同的workload,並且通過 MapReduce 在 Hadoop 上對其進行改造似乎非常具有挑戰性。
例如,傳統資料處理系統最常見的使用者是更熟悉 SQL語法 的資料分析人員,用 Java 編程語言編寫 MapReduce 不是他們的專長或強項。這就產生了 Apache Hive 和 Apache Pig 等專案。除此之外,資料科學家希望使用這個可擴展的平台進行機器學習,但在這個平台上開發、訓練和部署模型變得有困難性,這又產生 Apache Mahout 和 Spark ML 等專案。
由於有如此多的開源專案,整個Hadoop環境變得很雜,並且由於每個專案團隊都在各自的發布週期內獨立工作,因此部署 Hadoop 平台變得有困難性。這為 Hortonworks、Cloudera、MapR 等公司以及 Teradata、IBM 等data warehosuing廠商提供了推出 Hadoop 商業版的機會,這些商業版將打包最常見的專案並添加額外的管理平台以進行部署、保護和管理各種專案的生態系統。
Hadoop 的初衷是以可擴展的方式處理大型資料集。 但是,在地端環境中部署平台,在這種環境中,可擴展性是一個挑戰,添加和刪除硬體可能會出現問題; 而公有雲是部署 Hadoop 平台的最佳場所。 在像 AWS 這樣的公有雲中,我們可以擴展到任意數量的資源,在幾分鐘內啟動/關閉cluster,並根據資源的實際使用情況付費。
雖然我們可以在地端環境來 運作任何Hadoop的商業版,但AWS提供了 EMR(Elastic MapReduce)作為雲端的託管 Hadoop ,主要是讓我們在更輕鬆地在 AWS平台上部署、管理和擴展 Hadoop。 EMR 的首要目標是將Hadoop 商業版的集成和測試嚴格性與雲端的規模、簡單性和成本效益相結合。
AWS EMR概觀
這是由AWS提供的託管式 Hadoop與 Spark環境,能夠讓我們在幾分鐘內把整個Hadoop的環境架起來。
使用EMR可以讓我們用到最新版的Hadoop並且經過AWS測試過的企業等級的hadoop架構。EMR可以根據我們要分析資料的大小自動的擴展Hadoop and Spark cluster並且在工作完成後縮回到我們想要的機器數量來幫我們節省不必要的花費。
若我們將S3當作我們的資料湖(Data lake)我們就可以將原始資料與分析完的資料存在這裡,不會因為cluster的node的動態增減而損失資料。CloudWatch可以幫我們收集追蹤量化指標,設定告警。EMR也提供多種安全保護,包含用VPC提供網路層保護,使用KMS將分析完的資料在S3中加密。甚至可以使用AWS Macie機器學習模型來偵測,分類,保護EMR裡的資料。存取控制可以用IAM而驗證則能使用Kerberos。
如果我們要長期使用EMR,哪我們可以購買EC2的RI節省我們的費用。如果是中度使用者則可以用RI + Spot instance來處理我們的資料分析工作。
Apache Hadoop on AWS EMR
接下來介紹Hadoop的架構,與使用場景,還有在Hadoop專案裡的整個生態系,像是Hive, Tez, Pig,與 Mahout 以及對Apache SPark的需求。
Hadoop是一種主從式(master-slave)架構, master node稱為name nodes而slave nodes稱為data node。這種架構源自於MPP(massively parallel processing)-一種大規模的資料處理。MPP架構的主要目標就是將 storage與compute在一群的電腦(data node)中把它分開,而由單一的master node(name node)來管控這些作業。
name node(master node)負責管理namespace,例如整個filesystem metadata,以及node的位置和特定file的block位置。 該資訊是在系統啟動時從data node重建的。 由於name node的重要性,考慮到它具有file和block的location map,使其對故障具有韌性是很重要的。 這通常通過備份filesystem metadata或運行secondary name node process(通常在單獨的機器上)來實現。 但是,secondary name node在發生故障時不提供高可用性。 我們需要通過啟動一個新的name node來recovery 掛掉的name node,並使用metadata 副本來重建name node,這個過程可能需要 30 分鐘到 1 小時。
Data node是cluster中的實際worker,它們存取實際資料並與name node通訊以在name node level下保持namespace是最新的。
主要的元件如下
Hadoop MapReduce Hadoop(HDFS) 稍早有提到過了。不過 HDFS本身不是設計來進行低延遲的資料存取,如果需要的話應該是用Hbase。HDFS的設計是用使用一般商用硬碟來提供資料的High throughput。下圖顯示了client端讀取和client端寫入的 HDFS 架構和剖析。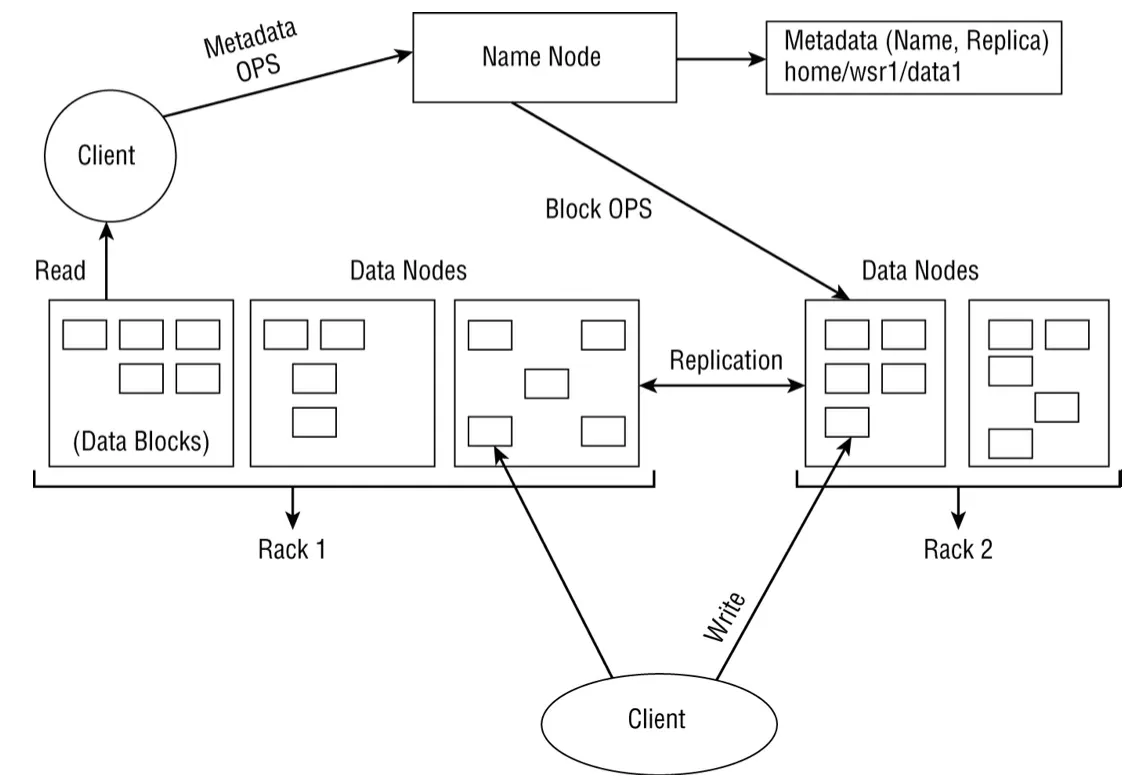
上圖中 filesystem 的metadata是運行在name node的memory中,意思是如果我們的資料都是些小檔案的話對Hadoop就會是一個問題。因為這樣會讓name node用完它的memory,其結果就是整個cluster掛掉,因為filesystem的metadata都不見了(存了太多小檔案的metadata)。HDFS對其要放上filesystem的檔案大小有其建議。
由於 IO 是導致latency的最重要因素之一,典型的filesystem處理data block以優化disk reads/write。 block大小是可以讀取或寫入的最小資料量,雖然disk的block大小為 512 bytes,但大多數filesystem將處理幾個KB的block大小。 HDFS 也使用block size,但default block大小為 128 MB。 HDFS使用大的block的原因是它旨在處理大量資料,因此我們需要最小化搜巡成本並通過每一次的 IO 獲取更多資料。而且每個Block都會被複製成三份(這可以手動更改)散落在不同的data node中。
MapReduce MapReduce 是 Hadoop 2.0 之前在 Hadoop 上進行資料處理實際上的編程模型,當時它衍生出 Apache YARN。 MapReduce job基本上是一個問題的解決方案,例如,資料轉換作業或應用程序想要在cluster上執行的一些基本分析(通常對存儲在 HDFS 或任何其他shared storage)在 MapReduce 編程模型中。 Map Reduce job分為兩個主要任務:Map 和 Reduce。這些任務由 YARN 橫跨cluster上的node調度,YARN 不僅調度任務,而且與 Application Master 一起作業以重新調度跨cluster的失敗作業.
Mapper將output寫入local disk而不是 HDFS,因為output是中繼的,然後由 reducer 階段收取以進行最終output。 作業完成後,mapper的output將被丟棄。 一般而言,reduce 作業從多個mapper 任務接收資料,並將output存儲到HDFS 進行持久化。 mapper作業的數量取決於拆分的數量(輸入拆分由 Hadoop 定義),而 reduce作業的數量是獨立定義的,不直接取決於輸入的大小。 選擇reducer的數量被認為是一門藝術而不是一門科學,因為reducer太少會影響整體並行度,從而減慢工作速度,而reducer太多可能會創建很多較小的file和大量的inter mapper-reducer traffic(the shuffle/sort)。
下圖描述了 MapReduce job的解析結構以及所涉及的主要步驟,例如將輸入資料轉換為拆分、運行mapper階段、使用combiner、shuffle和sort,然後再進行reduce階段以建立要存儲在 HDFS 上的output data。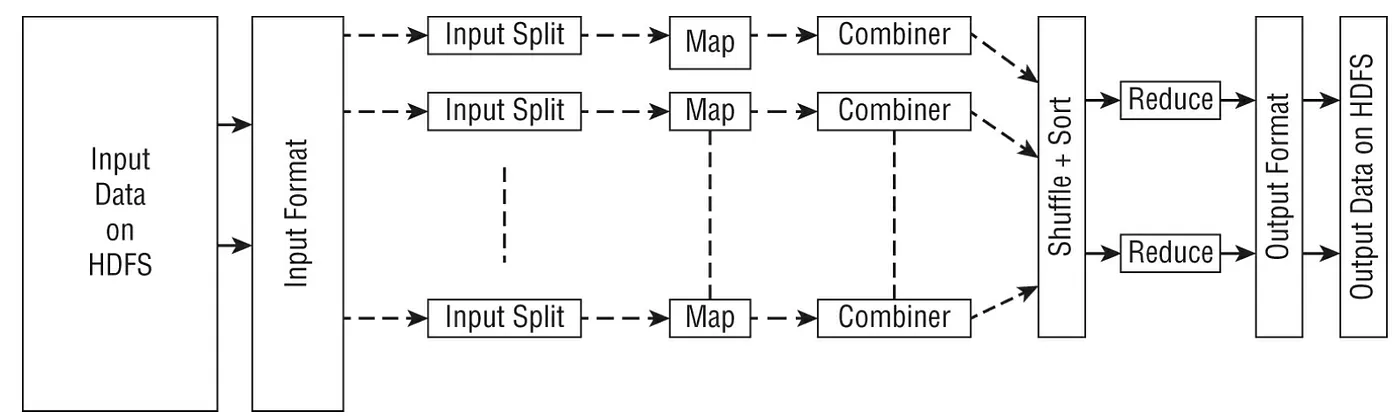
YARN(Yet Another Resource Negotiator) 如同它的名字一樣,這是在Hadoop 平台與Cluster resource內進行的一種資源管理。在 MapReduce 1.0時它是在computing framework內的,後來2.0後獨立出來。主要目標是把資源管理與compute engines(像是Apache Tez, Apache Spark)兩種作業分開來。
下圖為將兩種作業分隔開後這些上層的Application 可以直接使用下層的Frameworks而不需要與YARN整合在一起。
 不明
不明

 iThome鐵人賽
iThome鐵人賽