
ClickHouse 是由 Yandex 開發的 開源分布式列式資料庫管理系統(Column-oriented DBMS)。
主要針對 即時數據分析 (Real-Time Analytics) 場景設計,能夠在秒級內處理 PB 級數據。
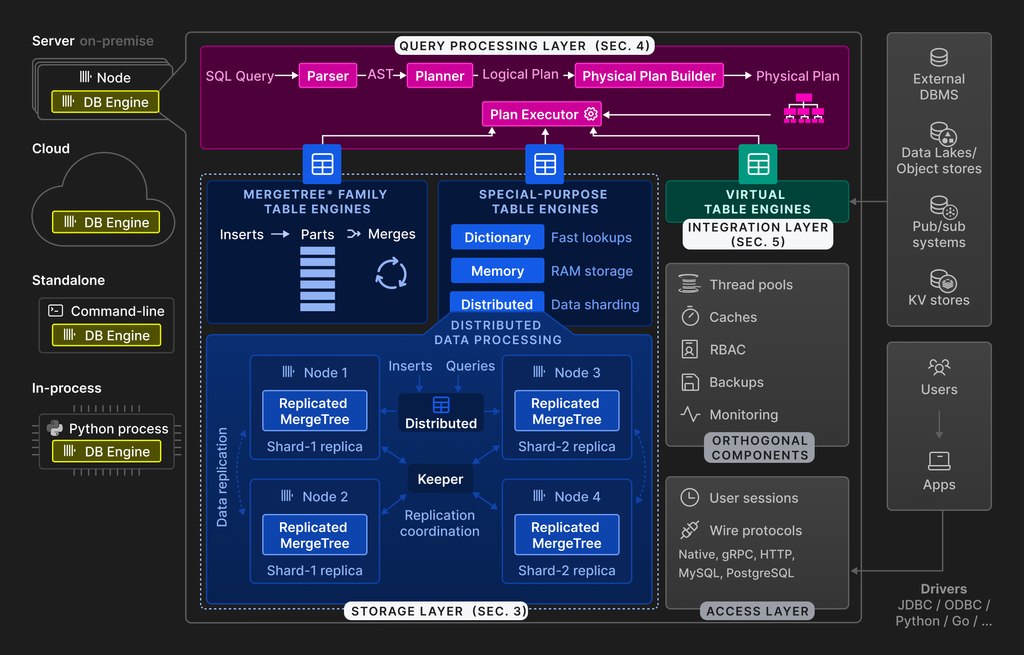
ClickHouse 的整體設計邏輯非常清晰:以高效能讀取為核心,透過分散式架構與儲存最佳化,讓秒級查詢在 PB 級數據中成為可能。
從資料寫入、儲存、索引到查詢回傳,ClickHouse 有著一套完全為 OLAP 場景最佳化的底層架構。
我們可以將流程稍微簡化成以下步驟:
資料寫入 → 拆分成 Data Parts → Partition 劃分 → Primary Key 排序 → 壓縮 → Merge → 索引裁剪 → 向量化查詢 → 回傳結果
看不懂?沒關係,追完系列文章就全都懂了 😎
| ClickHouse 技術特性 | 說明 |
|---|---|
| Columnar Storage | 只讀取需要的欄位,避免不必要的 I/O。 |
| Vectorized Execution | 將資料轉成 SIMD 批次處理,加速 CPU 運算效率。 |
| Compression | 各種編碼方式 (LZ4, ZSTD, Delta Encoding) 提供高壓縮比,降低儲存成本。 |
| Data Skipping Indexes | 不需掃描全部資料,可根據索引直接跳過不相關的數據區塊,查詢更快。 |
| MergeTree 儲存引擎 | 強大靈活的底層結構,支援分區、排序鍵、TTL 清理機制,適合大量數據分析。 |
| Materialized Views | 可將複雜查詢結果預先計算並實時更新,大幅加快查詢速度。 |
| 分布式架構 | 支援 Sharding 與 Replica ,易於擴展到 PB 級數據處理規模。 |
| Near-Real-Time Ingestion | 支援高吞吐量寫入 (如 Kafka Stream),數據可秒級查詢分析。 |
| 分類 | OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) |
|---|---|---|
| 主要用途 | 交易處理 (CRUD 操作) | 數據分析、統計報表 |
| 操作特性 | 少量資料的頻繁寫入 | 大量資料的批次查詢 |
| 查詢型態 | 單筆/少量記錄查詢 | 大範圍聚合查詢 (Aggregation) |
| 儲存結構 | 行式存儲 (Row-based) | 列式存儲 (Column-based) |
| 代表產品 | MySQL, PostgreSQL, Oracle | ClickHouse, Druid, Redshift |
| 項目 | ClickHouse | 傳統 Data Warehouse (如 Oracle DW, Teradata) |
|---|---|---|
| 架構 | 分布式列式存儲 | 多數為行式存儲或需額外配置列式引擎 |
| 查詢速度 | 毫秒級到秒級回應 | 通常需數秒到數分鐘 |
| 硬體需求 | 可用商用硬體 | 多數需昂貴專用伺服器 |
| 成本 | 開源免費/雲端計價模式 | 軟硬體成本高昂 |
| 延展性 | 支援線性水平擴展 (Sharding/Replication) | 擴展成本高 |
各位好,我是 Vic,這是我第一次投遞鐵人賽,會有參賽的原因是因為實習有用到 ClickHouse 這個資料庫服務,於是便一股腦鑽進來學習了,這個系列會著重於底層設計架構、優化...等細節,程式碼展示篇幅較少,內容應該會滿硬的XD(當然,我也同時在學習中),若你對這個系列感興趣,歡迎到我的部落格,上面更新速度比較快 XD,也會有其他的主題出現,對 軟體/前端/後端/AI Agent 開發有研究歡迎 Connect!
Vic 您好!非常感謝您在鐵人賽分享 ClickHouse 的系列文章,這篇開宗明義的介紹非常詳盡且易懂!
文章清楚地闡述了 ClickHouse 作為一個專為即時數據分析設計的 OLAP 資料庫,其列式儲存、向量化執行、高效壓縮等特色,如何結合分散式架構達到秒級查詢 PB 級數據。您整理的 OLAP/OLTP 基本概念以及 ClickHouse 與傳統資料庫的差異比較,對於像我這樣想快速掌握其核心價值與應用場景的讀者來說,提供了非常清晰的指引。
特別期待您後續深入探討底層設計架構與優化細節,相信這些內容對於實務應用上會非常有啟發。再次感謝您的用心分享!
也歡迎版主有空參考我的系列文「南桃AI重生記」:
https://ithelp.ithome.com.tw/users/20046160/ironman/8311

 iThome鐵人賽
iThome鐵人賽