距離上次使用 n8n 的 HTTP Request 節點有段時間了,今天我們又要用到它,先來複習一下現在的 n8n 工作區有哪些節點已經連接好了吧! (下圖為目前 n8n 的樣子)

今天我們會在用來取一則新聞的 Code 節點後面串接一個新節點 HTTP Request 用來取得新聞的 HTML 內容。
這邊要暫停說明一下,還記得我們在 Day 4 的時候第一次使用 HTTP Request 這個節點嗎?
回顧:【Day 4】自動化第一步成功!用 n8n 把新聞推送到 LINE
當時我們是用它來將新聞傳送給 LINE,所以我們的 Method 是 Post,而今天我們是要用來取得新聞的HTML**,**所以和上次有些不一樣,這次要用的是 Get 這個 Method。
下面來簡單說明一下「Post」和「Get」的差異:
HTTP Request 抓取 HTML在 Code 後面新增 HTTP Request 節點。

Get
{{ $json.link }}
執行完前面的節點,在左側 INPUT 中找到「link」 拖曳到此欄位
None
因為 CNA 的新聞網頁是公開資訊,不需要 API 金鑰或登入驗證,所以選 None。
Options: 選擇 Response
Text
html
把整個 HTML 存在 html 屬性中
確定上面的設定都正確後,執行此節點可在右側看到抓到的新聞 HTML 內容。
(若執行時發生錯誤,可以看看上面的錯誤資訊,再從中去尋找是哪裡出錯了。)
仔細看看,是不是覺得內容很雜,有一堆看不懂的外星文?
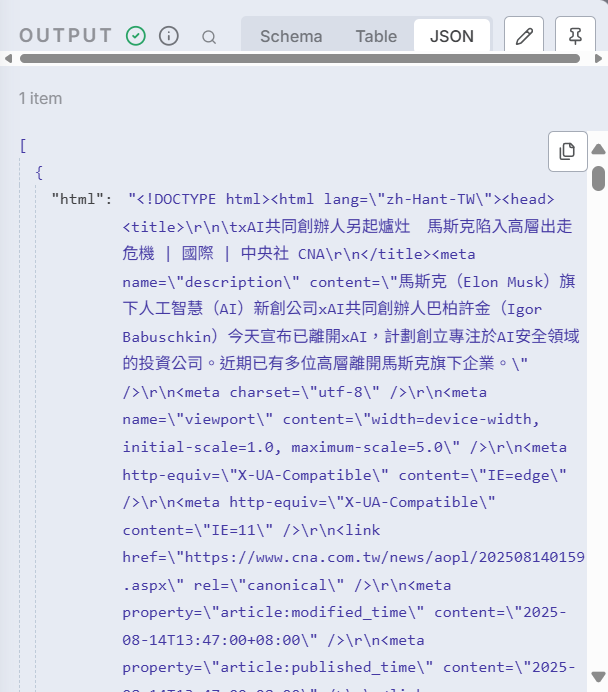
因為這個節點抓到的是新聞完整 HTML,也就是裡面包含了一堆元素資訊和各種標籤等。
HTML 除了正文外,還包含廣告、圖片標籤、CSS、JavaScript 等內容。
所以我們昨天才說要把多餘的內容篩掉,讓 HTML 只留下我們需要的文字。
如果直接將這麼一大串內容丟給 AI,別說摘要的內容精不精準了,它連輸入這些資訊去摘要都有問題。
既然已經知道完整的 HTML 內容有很多資訊,那我們要怎麼篩掉那些不要的東西呢?
接下來我們要利用 Code 節點來寫一段程式碼,目標是只留下需要的文字,開始吧!
HTTP Request 節點後新增 Code 節點
Run Once for All items(保持預設就好)JavaScript
const html = $input.first().json["html"];
// 找出所有 <p> ... </p> 之間的文字
const paragraphs = [...html.matchAll(/<p>([\s\S]*?)<\/p>/g)]
.map(p =>
p[1]
.replace(/<[^>]+>/g, '') // 去掉 HTML 標籤
.trim() //去掉段落開頭與結尾的空白與換行
)
.filter(t => !/本網站之文字、圖片及影音,非經授權,不得轉載、公開播送或公開傳輸及利用。/i.test(t));
// 合併成完整純文字
const cleanedText = paragraphs.join(' ');
return [{
json: {
fullContent: cleanedText
}
}];
上面的程式碼已經有做一些註解,這邊我們來說明一下比較細節的部分:
const html = $input.first().json["html"];
$input.first().json 取得上一個節點輸出的第一筆 JSON 資料。["html"] 讀取上一個節點中存放 HTML 原始碼的欄位(Put Output in Field → html 設定的那個欄位)。html,後面好直接分析。<p> 標籤內容
const paragraphs = [...html.matchAll(/<p>([\s\S]*?)<\/p>/gs)]
/ <p> ( [\s\S]*? ) <\/p> /g
<p> 與 </p>:精確鎖定段落標籤。([\s\S]*?):避免遇到空白或是換行就停止匹配(不管是字、空格還是換行都抓)。
g:全域匹配(找出所有 <p>)。
作用:抓出每一段 <p> 中的 HTML 內容(不含 <p> 與 </p> 本身)。
為什麼不直接抓 <div class="paragraph">?
因為有些 <p> 可能藏在更深的層級裡(例如 <div class="paragraph"><div class="media"><p>...</p></div></div>),直接找 <p> 比較保險。
.filter(t => !/本網站之文字、圖片及影音,非經授權,不得轉載、公開播送或公開傳輸及利用。/i.test(t))
.filter(...):篩選陣列元素,移除不需要的內容。! ... .test(t):反向判斷 → 只保留不符合版權聲明的段落。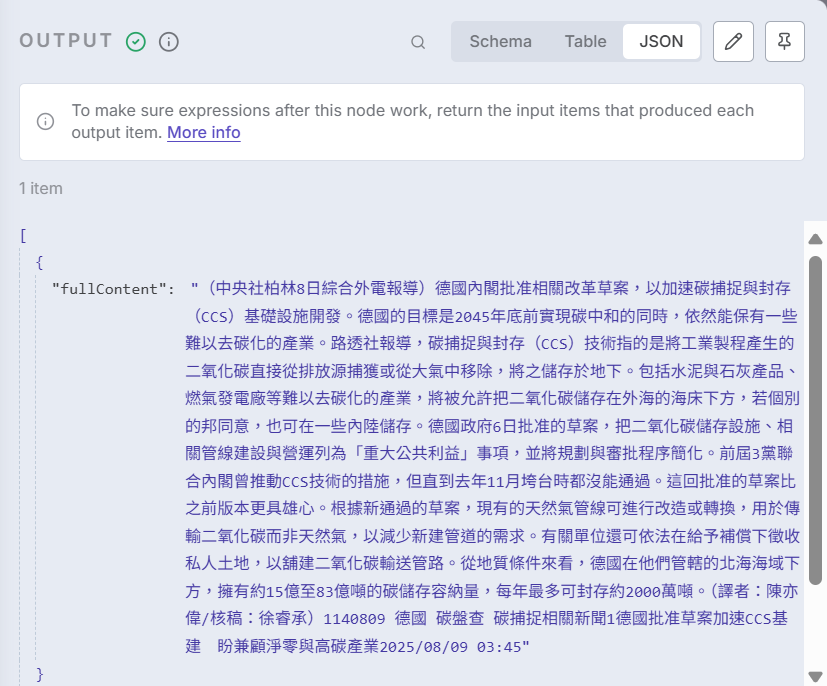
確認完就可以將這個節點和之前建立的 HTTP Request (to Gemini)串接起來,並執行看看:
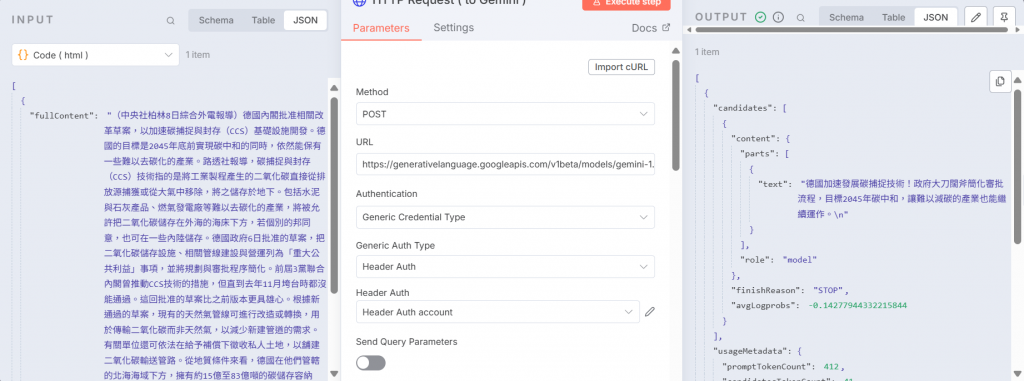
右側的 OUTPUT 裡的 “text” 就是 Gemini 摘要出來的內容。
❗同樣的新聞你每次執行都是重新送給 AI 摘要,所以執行出來的摘要都會長不一樣。
今天完成了新聞 HTML 的抓取與清理,明天我們就能讓乾淨的文字直接進入 AI 摘要流程。
這篇內容有些複雜,尤其是程式碼的部分,可能要多花點時間去了解,看完這篇文章且成功執行出結果的你很棒!
明天(Day 8)我們將為 AI 小編系統進行最後的調整!一個微小的細節,卻是決定訊息能否順利傳送的關鍵。


 iThome鐵人賽
iThome鐵人賽