前幾篇我們介紹了如何運用大語言模型(LLM)作為標註員,以及如何選擇合適的預訓練模型(如 BERT)。本篇將進一步說明,如何實際串接 LLM API,設計提示詞(prompt),並進行大規模資料標註的完整流程。
首先,需選擇想要串接的 LLM API。若你已經擁有付費版 ChatGPT,可直接使用其 API,本範例則以 Google Gemini 為例。
⚠️ 請注意:每個平台每日皆有免費使用額度及取用次數限制,若超過限制將遇到
429 error(Too Many Requests)。
在正式大量標註前,建議先設計並測試提示詞,確認模型回應品質,避免一次性用盡每日額度。
from google.colab import userdata
import os
os.environ["GEMINI_API_KEY"] = userdata.get('GOOGLE_API_KEY')
import os
from google import genai
from google.genai import types
def send_message_gemini(prompt):
# 讀取 API KEY
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemini-2.5-flash" # 建議用新版模型
# 將 prompt 包裝成 Content 格式
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text=prompt),
],
),
]
# 呼叫 Gemini API 並取得回應
response_text = ""
for chunk in client.models.generate_content_stream(
model=model,
contents=contents
):
response_text += chunk.text
return response_text
prompt = """
請將顧客評論分辨其情緒分類,標記為「正面」、「中性」或「負面」,並說明分類理由。若無法判定分類,請歸類為"中性"。
#顧客評論
"有夠爛"
#請為每個評論提供以下格式的回答:
情緒分類:
理由:
#限制條件
"每個評論僅能歸類為一種情緒分類。如果評論內容涉及多個不同面向,請綜合考量整段內容,並根據其主要情緒進行整體判斷。"
請確保回答完整涵蓋所有顧客評論,並依照提供的格式以繁體中文回答問題。
"""
if __name__ == "__main__":
print(send_message_gemini(prompt))
除了情緒標註之外,許多實務情境需自定義分類。以下示範如何建立自定義類別字典,並設計標註流程。
issue_categories = {
"1": [
"帳號與認證",
"涵蓋所有與用戶帳號建立、登入及安全性相關的問題,包括:\n"
"- 新用戶註冊流程(手機、Email、第三方登入等)\n"
"- 登入障礙(帳號/密碼錯誤、多重驗證、忘記密碼)\n"
"- 帳號安全(異常登入警示、凍結、解鎖、資料修正)\n"
"- 登出、切換帳號等操作問題"
],
"2": [
"商品搜尋與瀏覽",
"涵蓋用戶搜尋、瀏覽商品時的所有操作與體驗,包括:\n"
"- 搜尋欄關鍵字查詢、推薦詞\n"
"- 商品分類、主題館、品牌館瀏覽\n"
"- 篩選條件(價格、品牌、評價等)與排序功能\n"
"- 搜尋結果與商品列表的呈現、載入速度"
],
"3": [
"商品資訊與庫存",
"涵蓋商品詳細頁面與庫存相關的問題,包括:\n"
"- 商品資訊展示(名稱、圖片、價格、規格、促銷、評價)\n"
"- 商品狀態(缺貨、限購、停售、預購)\n"
"- 加入購物車按鈕功能、數量調整、已加入提醒\n"
"- 購物車內容檢視與編輯"
],
"4": [
"購物車與結帳",
"涵蓋從購物車到完成訂單的所有流程,包括:\n"
"- 購物車頁面操作(增加/刪除商品、套用優惠券、計算金額)\n"
"- 結帳流程啟動、配送地址填寫與選擇\n"
"- 支付方式選擇(信用卡、電子支付、貨到付款等)\n"
"- 訂單金額、折扣、運費確認\n"
"- 下單後的即時回饋(成功頁、失敗處理、訂單編號顯示)"
],
"5": [
"售後服務與會員權益",
"涵蓋訂單成立後的服務與會員專屬功能,包括:\n"
"- 訂單狀態查詢、物流追蹤、配送進度\n"
"- 客服聯繫(即時聊天、電話、Email、留言板)\n"
"- 退換貨申請與流程、退款進度\n"
"- 推播通知(優惠、訂單更新、系統公告)\n"
"- 會員專屬權益(積分、優惠券、等級制度、專屬活動)"
],
"6": [
"其他/特殊問題",
"不屬於上述分類的案例,包括:\n"
"- 問題描述不明確、資訊不足需補充\n"
"- 同時涉及多個分類、難以歸類的複合型問題\n"
"- 系統更新或新功能上線後的新興問題\n"
"- 特殊個案需跨部門協調或進一步釐清"
]
}
建議將資料集切分為多批,每批量不宜過大,並設計速率限制器(Rate Limiter)防止 API 超量。
實作時可加入指數退避(Exponential Backoff)機制,提升穩定性。
import pandas as pd
from typing import List, Dict, Optional, Union
from dataclasses import dataclass
from time import sleep, time
import json
from datetime import datetime, timedelta
import logging
from tqdm import tqdm
from litellm import completion
import threading
from collections import deque
import random
import time
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@dataclass
class IssueCategory:
id: int
category: str
description: str
class RateLimiter:
"""自訂速率限制器,實行抖動指數退避"""
def __init__(self, max_calls: int, time_window: float, max_backoff: float = 60):
self.max_calls = max_calls
self.time_window = time_window
self.max_backoff = max_backoff
self.calls = deque()
self._lock = threading.Lock()
def __call__(self, func):
def wrapper(*args, **kwargs):
with self._lock:
now = time.time()
# 移除時間窗口外的舊呼叫
while self.calls and now - self.calls[0] >= self.time_window:
self.calls.popleft()
# 如果達到最大呼叫數,使用抖動退避
if len(self.calls) >= self.max_calls:
backoff = min(2 ** len(self.calls) * random.uniform(0.5, 1.5), self.max_backoff)
logger.info(f"已達速率限制,睡眠 {backoff:.2f} 秒")
time.sleep(backoff)
self.calls.append(now)
return func(*args, **kwargs)
return wrapper
class ReviewClassifier:
def __init__(self, model_name: str = "gemini/gemini-2.5-flash-lite",
max_retries: int = 3, base_delay: float = 1.0,
rate_limit_calls: int = 10, rate_limit_period: int = 60):
self.model_name = model_name
self.max_retries = max_retries
self.base_delay = base_delay
self.categories = self._load_categories()
self.rate_limiter = RateLimiter(rate_limit_calls, rate_limit_period)
self._request = self.rate_limiter(self._make_api_request)
@staticmethod
def _load_categories() -> Dict[int, IssueCategory]:
"""Load issue categories from predefined dictionaries"""
categories = {}
for id_, (cat) in issue_categories.items():
description = issue_categories.get(id_, ("", ""))[1]
categories[id_] = IssueCategory(
id=id_,
category=cat,
description=description
)
return categories
def _format_categories(self) -> str:
"""Format categories for prompt"""
return "\n".join([
f"{k}: {v.category}"
for k, v in self.categories.items()
])
def _format_categories_info(self) -> str:
"""Format category descriptions for prompt"""
return "\n".join([
f"{k}: {v.category} - {v.description}"
for k, v in self.categories.items()
])
def _create_prompt(self, review: str) -> str:
"""Create classification prompt"""
return f"""
請將顧客評論分辨其自定義分類。請使用以下預定義的類別進行分類,並說明分類理由。每個評論可能涉及多個分類,請根據此評論影響程度較高的分類,給定一個分類。若無法判定分類,請留"其他"。
#自定義分類表
{self._format_categories()}
#顧客評論
{review}
#請為每個評論提供以下格式的回答:(自定義分類不需要加入編號)
自定義分類: [自定義類別]
理由:
綜合自定義分類:[根據所有評論內容只給定一個自定義類別]
#限制條件
1. 無法分類的範例:
"Good."
"方便"
"超爛的app"
這些範例並無明確的描述,因此歸類為"其他"。
2. 一個評論有多個分類範例:
"1. 登入時卡住,改了密碼也一樣 2. 購物車的東西時不時會消失 3. 整天在那邊吵要二階段認證,然後認證又不會通過,只好用電腦秒成功 到底是美學素養還是專業能力出了問題"
此範例會歸類為"會員登入"(影響最大的問題),當有多個分類時,請評估影響最高的給定一個分類。
3. "每個評論僅能歸類為一種自定義分類。如果評論內容涉及多個不同面向,請綜合考量整段內容,並根據其主要內容進行整體判斷。"
請確保回答完整涵蓋所有顧客評論,並依照提供的格式以繁體中文回答問題。
"""
def _make_api_request(self, review: str) -> str:
"""Make API request with retries"""
for attempt in range(self.max_retries):
try:
response = completion(
model=self.model_name,
messages=[{"role": "user", "content": self._create_prompt(review)}],
temperature=0.3
)
return response.choices[0].message.content
except Exception as e:
delay = self.base_delay * (2 ** attempt) # Exponential backoff
logger.warning(f"Attempt {attempt + 1} failed: {str(e)}. "
f"Retrying in {delay} seconds...")
sleep(delay)
logger.error(f"All attempts failed for review: {review[:100]}...")
return "Error after retries"
def process_batch(self, reviews: List[str],
batch_size: int = 5) -> List[str]:
"""Process a batch of reviews"""
results = []
for i in tqdm(range(0, len(reviews), batch_size)):
batch = reviews[i:i + batch_size]
batch_results = [self._request(review) for review in batch]
results.extend(batch_results)
return results
def classify_dataframe(self, df: pd.DataFrame,
review_column: str = 'verbatim',
batch_size: int = 5) -> pd.DataFrame:
"""Classify all reviews in a DataFrame"""
reviews = df[review_column].tolist()
classifications = self.process_batch(reviews, batch_size)
df['classification'] = classifications
return df
def main():
try:
# Example usage
classifier = ReviewClassifier(
rate_limit_calls=10,
rate_limit_period=60
)
# Load your DataFrame
df = pd.read_excel('/content/drive/MyDrive/20250823_pchome.xlsx', sheet_name='cleaned_data')
df1=df[:200].copy()
df2=df[200:400].copy()
# 初始化一個空的 DataFrame 用於存放結果
final_results_df = pd.DataFrame()
# 使用分類器處理樣本資料
for df_sample in [df1, df2]:
results_df = classifier.classify_dataframe(
df_sample, # 使用分割後的 dataframe
review_column='review', # 指定評論的欄位名稱
batch_size=5
)
# 將當前結果合併到最終的 DataFrame
final_results_df = pd.concat([final_results_df, results_df], ignore_index=True)
# 儲存結果
final_results_df.to_excel('/content/drive/MyDrive/20250830_sentiment_pchome_2.xlsx', index=False)
return final_results_df
except Exception as e:
logger.error(f"Error in main function: {str(e)}")
raise
if __name__ == "__main__":
classified_df = main()
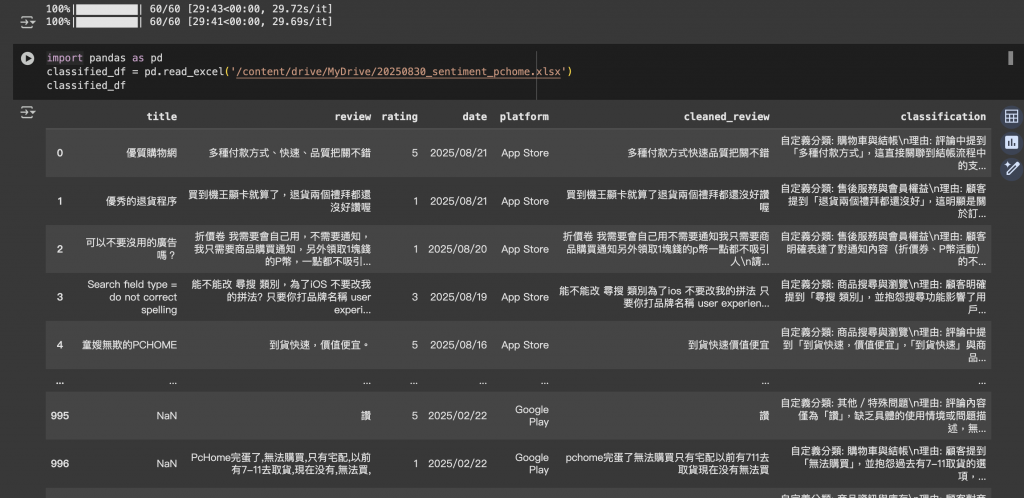
import pandas as pd
classified_df = pd.read_excel('/content/drive/MyDrive/20250830_sentiment_pchome.xlsx')
classified_df
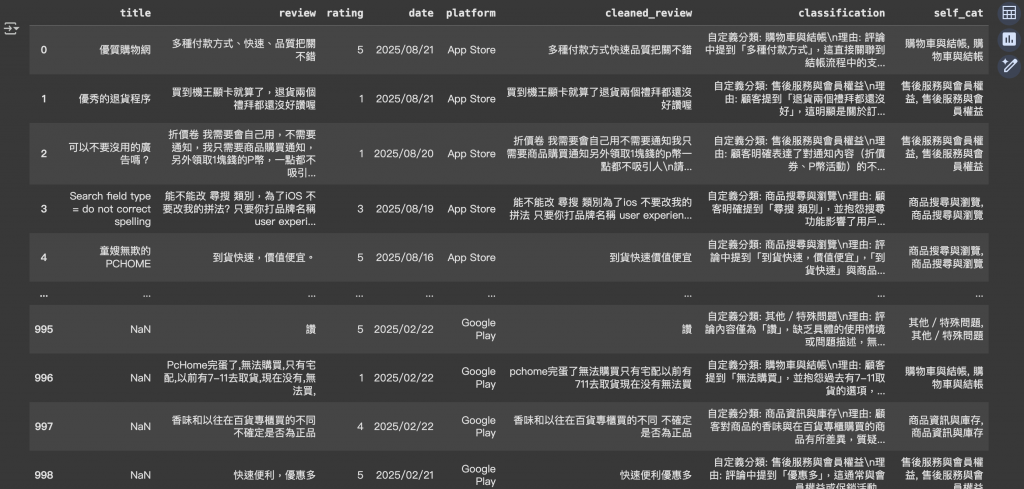
利用正則表達式自動抽取 LLM 回傳的分類結果,便於後續分析。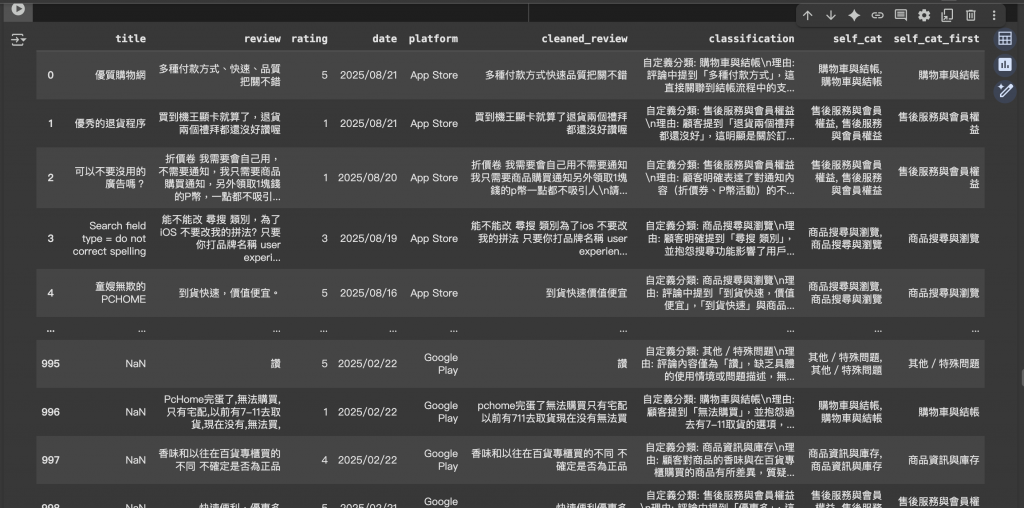
在本篇文章中,介紹如何運用大語言模型(LLM)進行自動化標註,從 API 串接、提示詞設計,到批量資料處理與結果解析,但需要注意免費版本的用量限制。
隨著 LLM 技術持續進步,我相信未來自動化標註將在各種資料分析、客服回饋、產品優化等場域發揮更大影響力。但仍建議在實務應用時,持續優化提示詞、監控模型表現,並結合人工審核,建立一個可靠且有效的標記流程。


 iThome鐵人賽
iThome鐵人賽