老實說,第一次聽到 Monitoring 跟 Observability,我的反應跟剛分手時一樣:「蛤?不是都差不多意思嗎?」
結果我去 Google,一堆文章不是在講 metrics、tracing、logging,就是貼幾張雲端架構圖,玄到跟算命一樣。
就好比占卜師對著你說:「你這段感情業障太重,容易斷線。」
呃,對不起,我只是想知道到底是 Redis 掛了還是我程式寫太爛啦。
而我們工程師的日常,就像一個 失戀卻還要上班的勇者:系統會炸,老闆會催,客戶會抱怨,但你還是得打開 Grafana 假裝「一切盡在掌握中」。
所以這系列文章的玩法很簡單:
概念 → 架構 → 工具 → 視覺化 → 告警
就像 RPG 一樣,解鎖技能一路打怪。
想像一下,你去 7-11,頭頂那顆攝影機默默錄你深夜買泡麵的樣子。
監控,就是那顆攝影機。
在 IT 系統裡,Monitoring 的重點就是:
它就是那種:平常你根本不理它,一出事它就跳出來**「欸嘿,我早就知道了」** 的東西。
比方說:
簡單來說:監控不會讓你變快樂,但它至少能提早告訴你「悲劇快要發生了」。
就像交往中那種「感覺她最近很冷淡」的預警指標一樣。
來,給各位一張監控層級小抄:
1. **Application Level**:監控應用程式的效能與指標,如資料庫查詢時間、快取狀態。
2. **Infrastructure Level**:伺服器負載、記憶體、磁碟、網路效率。
3. **Service Provider Level**:第三方提供的可用性、資源使用統計。
4. **User Level**:使用者體驗與滿意度指標。
5. **Full-Stack Observability**:即時監控每個元件,提供整體系統可見性。
指標是量化系統表現的數據:
重點:
Checkpoint:
來到大家最愛的 combo。
Prometheus 是收集數據的,Grafana 是把數據畫成圖的。
就像止痛藥+咖啡:救不了命,但能讓你撐到天亮。

PromQL 是 Prometheus 的查詢語言。
語法雖然直白,但寫久了會懷疑人生。
rate(http_requests_total[5m])
意思是:過去五分鐘的 HTTP 請求速率。
但你心裡真正想問的是:「為什麼使用者要在半夜三點狂打 API?」
另一個範例:
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
意思是:95% 的請求延遲是多少。
但對我來說,這就像問自己:「95% 的人生是不是都在 debug?」
Monitoring ≠ Observability。
| 特性 | Monitoring(監控) | Observability(可觀測性) |
|---|---|---|
| 目標 | 看服務活著沒 | 理解系統內部怎麼活的 |
| 焦點 | 表面指標、已知異常 | 行為流、未知問題 |
| 功能 | 告警、已知問題追蹤 | 分析根因、優化性能 |
| 結果 | 告訴你「發生什麼」 | 告訴你「為什麼發生」 |
講白了:
兩者缺一不可。光有 Monitoring,你只會知道「系統炸了」。
但有 Observability,你才能知道「是 Redis 爆炸還是 DBA 半夜不小心 drop table」。
三者合體,才是真的「全面監控」。
只帶一個去副本?必滅。
| 類別 | Monitoring(監控) | Observability(可觀測性) |
|---|---|---|
| Metrics | CPU/Memory/Disk、API 請求數、Redis/DB 操作次數 | LLM 延遲、Redis/DB latency、API 路由細節 |
| Tracing | - | RAG 問答流程全程追蹤、Prefect Flow / Task 流程分析 |
| Alert / Log | 服務不可用、API 過頻、資源異常告警 | 日誌與異常追蹤、定位未知問題 |
簡單來說,Metrics 量化、Tracing 跟蹤流程、Alert / Log 告訴你系統哪裡出問題。
工具選型
Metrics 收集策略
Tracing 策略
告警設計
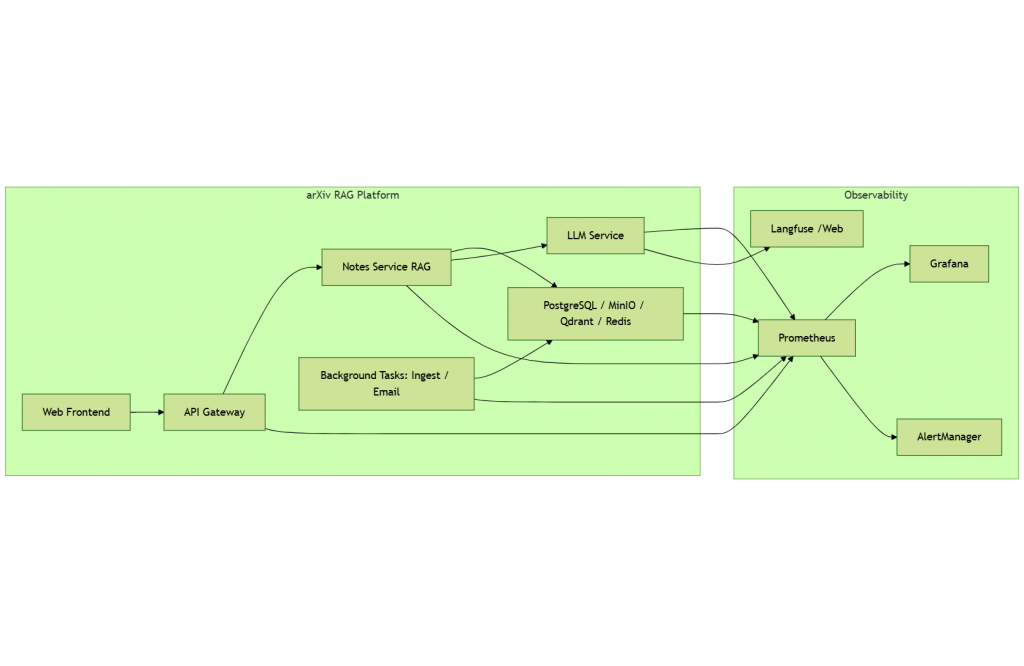
上圖示意整個平台與 Observability 架構關係,Metrics / Tracing 由 Prometheus 收集,Grafana 可視化,AlertManager 負責告警。
總結一下:
沒有 Monitoring,你會突然被老闆半夜叫起來。
沒有 Observability,你會 debug 到懷疑人生。
所以記住:
系統健康管理,不是工具,而是你能不能少掉髮的關鍵。
👉 好啦,這篇寫到這裡,字數也夠讓我懷疑是不是該收個顧問費了。
反正,下次系統炸掉的時候,記得先打開 dashboard,不要先打開冰箱找啤酒。
(雖然我懂,通常兩個會同時打開。)


 iThome鐵人賽
iThome鐵人賽