「AI 不可怕,可怕的是它回我那句話的邏輯我看不懂。」
欸,老實說,現在做 LLM 應用,有一種 déjà vu 的感覺。
就像你以前寫微服務,一切都很美好,直到第一個「timeout」出現。
你打開監控,看著那條紅線一路飆升,然後開始懷疑人生。
RAG(Retrieval-Augmented Generation)也是。
模型不是不會講話,它只是講話講太多。
有時你問它「台灣最熱門的資料庫是什麼?」
它會回答你「MongoDB 是一種熱帶水果。」
你愣了一下,懷疑是不是 prompt 壞了、embedding 爆了、retrieval 出 bug 了——
但更可能的是:你根本看不到裡面到底發生了什麼。
而 Langfuse,就是那副「觀測之眼」。
它不會幫你修 bug,但會讓你知道 bug 正在微笑。
(就像人生一樣,你改不了它,但至少你能看見它。)
這篇文章會示範如何把 Langfuse 用在 RAG Pipeline 中,並介紹實務封裝與 Self-host 架構設計,讓你能從黑箱中獲得清晰的運行視角。
你知道那種人嗎?
開會的時候總是說:「我們要強化 observability!」
然後你看了一眼,他的系統連基本 log rotation 都沒設。
Langfuse 就是為了避免這種尷尬。
它讓你能看到整個 LLM 應用的「呼吸」——
從 token、prompt、embedding 到 RAG pipeline 的每一環節。
講人話就是:
「Langfuse 幫你追蹤每次模型怎麼被調用、花了多久、花了多少錢、講了什麼幹話。」
「萬物皆可追蹤」——在 AI / LLM 應用中,若你無法觀察,那就無法優化。
今天我們要把 Langfuse 當成魔法觀測鏡,記錄每一次 LLM 調用,每一段 prompt、token 使用、延遲、錯誤,通通攤在眼前。
在傳統後端系統中,我們會記 log、監控 CPU / memory、做 metrics(如響應時間、錯誤率)。但在 LLM 應用中,加入「語言模型呼叫」「prompt 選擇」「生成輸出」「cost / token 使用」等層次後,系統變成黑箱。
可觀測性不只是「有 log 就算了」——而是要 Trace / Span / Metrics / Alert / 深入關聯,才能真正找到瓶頸、診斷異常、優化模型。
Langfuse 正是為這類場景設計的觀測平台,它與 OpenTelemetry(OTel)兼容、提供 LLM 專用觀察(generation / span / trace)等觀測物件。
| 名稱 | 角色 / 功能 | 備註 |
|---|---|---|
| Trace | 一次完整操作流程(從入口到出口) | 包含多個 Span / Generation;可跨服務 / 跨模組追蹤 (Langfuse) |
| Span / Observation | 單一操作單元 | 如資料前處理、LLM 呼叫、資料庫查詢等,每個操作可成為一個 span (Langfuse) |
| Generation | 專屬 LLM 呼叫的 span 類型 | 帶有模型名稱、token 使用量、cost 等欄位 (Langfuse) |
| Trace ID / Observation ID | 用來關聯 Trace / Span 的唯一識別碼 | 可以使用自己的 domain ID (如 correlationId) 或讓 Langfuse 自動產生 (Langfuse) |
| Session / Tags / Metadata | 對 Trace 做標籤、分類 | 幫助後續搜尋、分群、過濾 |
舉例:假設你有一個用戶請求觸發 LLM 回答,你可以為這個請求開一個 Trace,裡面包含:
這樣整條流程的每一環節都有可觀察性,若某一環延遲過高或 token 使用異常,就可以快速定位是哪一段出了問題。
Langfuse 是一個開源的 LLM 工程平台,旨在幫助團隊協作開發、監控、評估和調試 AI 應用。它提供了全鏈路可觀察性、Prompt 管理、評測工具和數據集管理等功能,讓開發者能夠更高效地進行模型開發和優化。
🧩Trace:記錄一次完整的 LLM 調用鏈
在 Langfuse 中,Trace 是記錄一次完整的 LLM 調用鏈的核心單位。它包含了用戶的 Prompt、系統的回應、調用的模型、生成的內容等信息,幫助開發者全面了解每一次模型調用的過程。
🧪 Span:細化每一步操作的追蹤
每個 Trace 可以包含多個 Span,用於細化記錄每一步操作的過程。例如,在一個多輪對話中,每一次模型的生成都可以作為一個 Span 進行記錄,幫助開發者分析每一步的行為。
📊 可視化界面:直觀展示模型行為
Langfuse 提供了直觀的可視化界面,開發者可以通過 Trace、Span、Session 等視圖,直觀地查看模型的行為和性能指標,幫助快速定位問題和進行優化。
🛠️ 集成與 SDK:靈活接入各種應用場景
Langfuse 提供了多種 SDK,包括 Python、JavaScript、OpenAI 等,支持與 LangChain、LlamaIndex、Litellm 等框架的集成,方便開發者在不同的應用場景中使用。
假設使用者問你:
「LangChain 比 LlamaIndex 好在哪?」
在系統裡,這次請求可能經歷以下階段:
Trace ID: a1b2c3d4
├── [embedding_span] query -> vector
├── [retrieval_span] 搜尋 15 筆文件
├── [rerank_span] 根據分數排序
├── [prompt_span] 組合 context + query
└── [generation_span] GPT 回答 128 token (🔥 cost: $0.0021)
那感覺就像你第一次在 Google Photos 找到前任的合照——
不一定愉快,但至少「終於知道為什麼當初會那樣了」。
我們從一個簡化版 pipeline 開始。
(放心,這不是官方文件的翻譯,而是實際工程師罵完髒話後能跑的版本。)
from langfuse import Langfuse
from langfuse.decorators import observe
langfuse = Langfuse(public_key="pk_xxx", secret_key="sk_xxx")
@observe(name="rag_pipeline")
def ask_question(query):
trace = langfuse.trace(name="user_query", metadata={"query": query})
with trace.span(name="embedding_span"):
query_vector = get_embedding(query)
with trace.span(name="retrieval_span"):
docs = search_db(query_vector)
with trace.span(name="rerank_span"):
sorted_docs = rerank_docs(docs)
with trace.span(name="prompt_span"):
prompt = build_prompt(query, sorted_docs)
with trace.generation(name="llm_generation", model="gpt-4"):
answer = call_llm(prompt)
trace.end()
return answer
結果畫面(在 Langfuse dashboard)大概長這樣:
Trace: rag_pipeline
Duration: 2.87s
Token Usage: 540
Cost: $0.0049
😎 Status: completed
那瞬間真的有點爽,因為你終於能回答 PM 那句靈魂拷問:
「欸,為什麼有時候 GPT 會慢一點?」
——「因為 embedding 那段花了 1.3 秒,你的 query 太像垃圾話了。」
很多人把 observability 當成「KPI 追蹤」——錯。
那只是管理層的夢。
對工程師來說,觀測是一種心理治療。
你能看到系統怎麼崩、哪裡慢、為什麼爛。
那是一種控制感。
(至少比你在感情裡有更多可控變數。)
我們來看完整例子(這是我實際封裝的 RAGTracer 流程)👇
ask_flow
langfuse_tracer = LangfuseTracer(settings)
rag_tracer = RAGTracer(langfuse_tracer)
with rag_tracer.trace_request(request.user_id, ask_r.query) as trace:
├── embedding_span : get_embedding
├── search_span : search relevant chunks
├── rerank_span : re_rank
├── prompt_span : build prompt
├── gen_span : generate response
rag_tracer.end_request(trace, response.answer, time.time() - start_time)
每一個 step 都有對應的 trace / span:
嵌入、檢索、重排、生成。
看起來像流水帳,但每一段都有故事。
尤其是當某個 span 突然飆高時,那代表什麼?
——有時代表系統出錯,有時代表工程師忘了睡覺。
在 Langfuse 後台,我們能看到這次請求的完整樹狀結構(如下圖):
第一步是將 Query 轉換成向量:
with rag_tracer.trace_embedding(trace, query=query) as embedding_span:
query_embedding = get_embedding(query)
rag_tracer.end_embedding(embedding_span, query_embedding)
這裡的 embedding_span 記錄了輸入查詢與生成的向量,用於後續檢索。
接著進行向量與文本檢索:
with rag_tracer.trace_search(trace, query=query, top_k=top_k, search_mode=search_mode) as search_span:
chunks, sources, msg, arxiv_ids, total_hits = qdrant_client.search(
query=query,
query_vector=query_embedding,
size=top_k * 2,
min_score=0.3,
hybrid=system_settings.hybrid_search,
categories=categories,
)
rag_tracer.end_search(search_span, chunks, arxiv_ids, total_hits)
將檢索到的 chunks 根據相關性重新排序:
with rag_tracer.trace_rerank(trace, query=query, vector_weight=vector_weight, bm25_weight=bm25_weight) as rerank_span:
reranked = re_ranking(
chunks,
query,
vector_weight=vector_weight,
bm25_weight=bm25_weight,
)
rag_tracer.end_rerank(rerank_span, reranked)
這一步的 rerank_span 幫助我們比較不同演算法(如 BM25 與向量檢索)的權重影響。
根據排序後的 chunks 構建最終提示詞:
with rag_tracer.trace_prompt_construction(trace, chunks) as prompt_span:
prompt_data = ollama_client.prompt_builder.create_structured_prompt(query, chunks, system_settings.user_language)
final_prompt = prompt_data["prompt"]
rag_tracer.end_prompt(prompt_span, final_prompt)
這裡的 prompt_span 不只記錄了原始 chunks,還能看到最終的 prompt 字串,用於後續的 LLM 呼叫。
最後,將 prompt 送入模型產生答案:
with rag_tracer.trace_generation(trace, model, final_prompt) as gen_span:
parsed_response, response = await ollama_client.generate_rag_answer(
query=query,
chunks=chunks,
user_language=system_settings.user_language,
use_structured_output=False,
temperature=system_settings.temperature,
)
rag_tracer.end_generation(gen_span, response, model)
在這個 gen_span 裡,我們能觀測:
gpt-oss:20b)你知道工程師最怕什麼嗎?不是 bug,是「被監控」。
所以很多人會自己 host Langfuse,確保資料不出公司。
Langfuse 的自架構中,主要由兩大類服務與儲存系統組成:
下面是官方 Self-hosting 文件中對架構的描述:
Langfuse consists of two application containers (Web + Worker)、儲存組件(Postgres, ClickHouse, Redis / 缓存, S3 / Blob Storage)等。(Langfuse)
附錄的 docker-compose 配置映射這樣的組件:worker / web / PostgreSQL / ClickHouse / MinIO / Redis,並且共用一個網路 langfuse-otel-net 以利內部通訊。
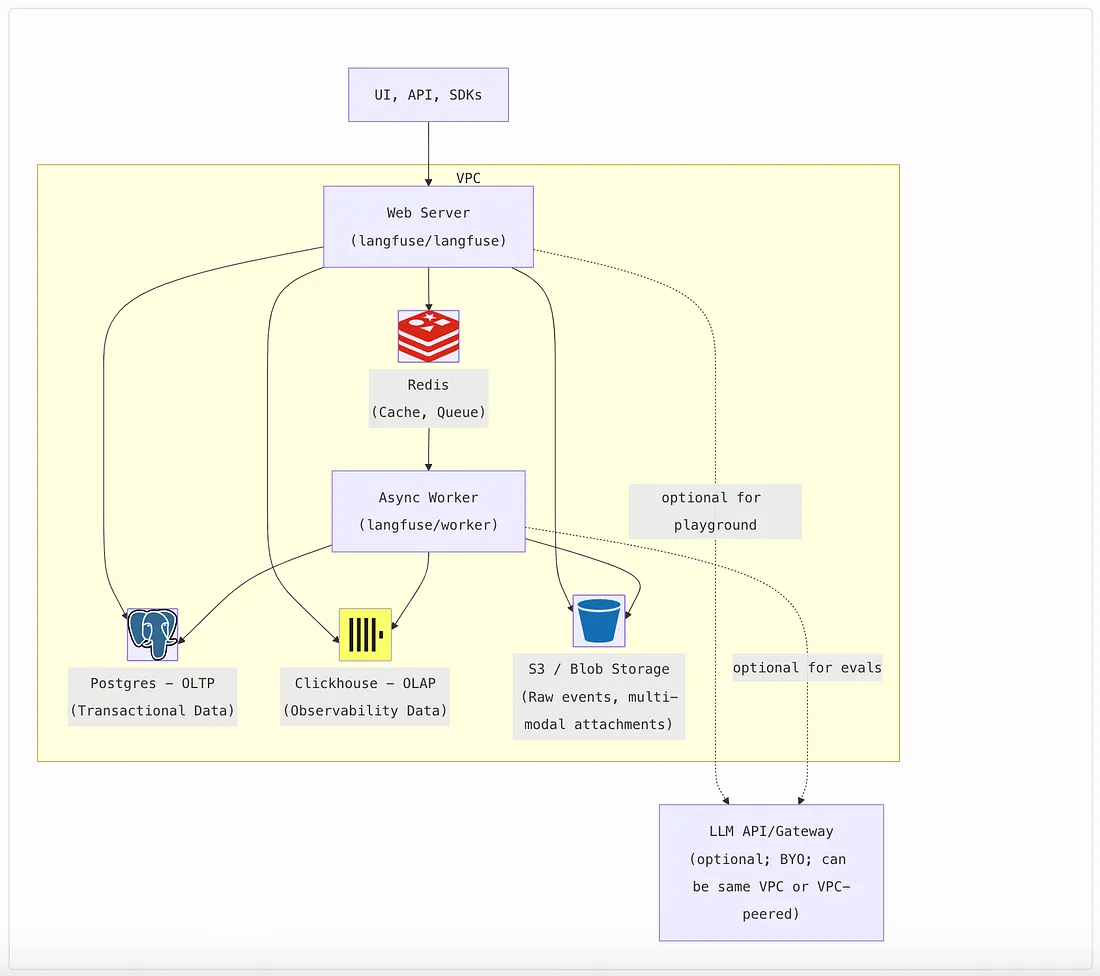
以上流程對應的是:
| 組件 | 角色 | 人類比喻 |
|---|---|---|
| langfuse-web | 提供 UI 與 API 入口 | 門面工讀生(負責接客) |
| langfuse-worker | 後台資料 ingestion / 處理 | 無名英雄(凌晨三點在清 log) |
| PostgreSQL | 儲存使用者與設定 | 那個幫你記帳的朋友 |
| ClickHouse | 儲存大規模 Trace 分析資料 | 記性超好但不講話的怪人 |
| Redis | Queue / 快取層 | 傳話小弟 |
| MinIO | 儲存原始事件與大檔案 | 倉庫管理員 |
架構圖看起來很帥,但部署起來超煩。
每次 docker-compose up 都像召喚惡靈,
不是 ClickHouse 沒啟,就是 Redis 密碼忘改。
CLICKHOUSE_URL、DATABASE_URL、LANGFUSE_S3_EVENT_UPLOAD_* 等以下是一段能實際跑的 Langfuse self-host 配置(節錄):
networks:
langfuse-otel-net:
external: true
services:
langfuse-worker:
image: docker.io/langfuse/langfuse-worker:3
restart: always
depends_on: &langfuse-depends-on
langfuse-postgres:
condition: service_healthy
langfuse-minio:
condition: service_healthy
langfuse-redis:
condition: service_healthy
langfuse-clickhouse:
condition: service_healthy
ports:
- 127.0.0.1:3030:3030
environment: &langfuse-worker-env
NEXTAUTH_URL: http://localhost:3000
DATABASE_URL: postgresql://postgres:postgres@langfuse-postgres:5432/postgres # CHANGEME
SALT: "mysalt" # CHANGEME
ENCRYPTION_KEY: "0000000000000000000000000000000000000000000000000000000000000000" # CHANGEME: generate via `openssl rand -hex 32`
TELEMETRY_ENABLED: ${TELEMETRY_ENABLED:-true}
LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES: ${LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES:-true}
CLICKHOUSE_MIGRATION_URL: ${CLICKHOUSE_MIGRATION_URL:-clickhouse://langfuse-clickhouse:9000}
CLICKHOUSE_URL: ${CLICKHOUSE_URL:-http://langfuse-clickhouse:8123}
CLICKHOUSE_USER: ${CLICKHOUSE_USER:-clickhouse}
CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD:-clickhouse} # CHANGEME
CLICKHOUSE_CLUSTER_ENABLED: ${CLICKHOUSE_CLUSTER_ENABLED:-false}
LANGFUSE_USE_AZURE_BLOB: ${LANGFUSE_USE_AZURE_BLOB:-false}
LANGFUSE_S3_EVENT_UPLOAD_BUCKET: ${LANGFUSE_S3_EVENT_UPLOAD_BUCKET:-langfuse}
LANGFUSE_S3_EVENT_UPLOAD_REGION: ${LANGFUSE_S3_EVENT_UPLOAD_REGION:-auto}
LANGFUSE_S3_EVENT_UPLOAD_ACCESS_KEY_ID: ${LANGFUSE_S3_EVENT_UPLOAD_ACCESS_KEY_ID:-minio}
LANGFUSE_S3_EVENT_UPLOAD_SECRET_ACCESS_KEY: ${LANGFUSE_S3_EVENT_UPLOAD_SECRET_ACCESS_KEY:-miniosecret} # CHANGEME
LANGFUSE_S3_EVENT_UPLOAD_ENDPOINT: ${LANGFUSE_S3_EVENT_UPLOAD_ENDPOINT:-http://langfuse-minio:9000}
LANGFUSE_S3_EVENT_UPLOAD_FORCE_PATH_STYLE: ${LANGFUSE_S3_EVENT_UPLOAD_FORCE_PATH_STYLE:-true}
LANGFUSE_S3_EVENT_UPLOAD_PREFIX: ${LANGFUSE_S3_EVENT_UPLOAD_PREFIX:-events/}
LANGFUSE_S3_MEDIA_UPLOAD_BUCKET: ${LANGFUSE_S3_MEDIA_UPLOAD_BUCKET:-langfuse}
LANGFUSE_S3_MEDIA_UPLOAD_REGION: ${LANGFUSE_S3_MEDIA_UPLOAD_REGION:-auto}
LANGFUSE_S3_MEDIA_UPLOAD_ACCESS_KEY_ID: ${LANGFUSE_S3_MEDIA_UPLOAD_ACCESS_KEY_ID:-minio}
LANGFUSE_S3_MEDIA_UPLOAD_SECRET_ACCESS_KEY: ${LANGFUSE_S3_MEDIA_UPLOAD_SECRET_ACCESS_KEY:-miniosecret} # CHANGEME
LANGFUSE_S3_MEDIA_UPLOAD_ENDPOINT: ${LANGFUSE_S3_MEDIA_UPLOAD_ENDPOINT:-http://localhost:9091}
LANGFUSE_S3_MEDIA_UPLOAD_FORCE_PATH_STYLE: ${LANGFUSE_S3_MEDIA_UPLOAD_FORCE_PATH_STYLE:-true}
LANGFUSE_S3_MEDIA_UPLOAD_PREFIX: ${LANGFUSE_S3_MEDIA_UPLOAD_PREFIX:-media/}
LANGFUSE_S3_BATCH_EXPORT_ENABLED: ${LANGFUSE_S3_BATCH_EXPORT_ENABLED:-false}
LANGFUSE_S3_BATCH_EXPORT_BUCKET: ${LANGFUSE_S3_BATCH_EXPORT_BUCKET:-langfuse}
LANGFUSE_S3_BATCH_EXPORT_PREFIX: ${LANGFUSE_S3_BATCH_EXPORT_PREFIX:-exports/}
LANGFUSE_S3_BATCH_EXPORT_REGION: ${LANGFUSE_S3_BATCH_EXPORT_REGION:-auto}
LANGFUSE_S3_BATCH_EXPORT_ENDPOINT: ${LANGFUSE_S3_BATCH_EXPORT_ENDPOINT:-http://minio:9000}
LANGFUSE_S3_BATCH_EXPORT_EXTERNAL_ENDPOINT: ${LANGFUSE_S3_BATCH_EXPORT_EXTERNAL_ENDPOINT:-http://localhost:9092}
LANGFUSE_S3_BATCH_EXPORT_ACCESS_KEY_ID: ${LANGFUSE_S3_BATCH_EXPORT_ACCESS_KEY_ID:-minio}
LANGFUSE_S3_BATCH_EXPORT_SECRET_ACCESS_KEY: ${LANGFUSE_S3_BATCH_EXPORT_SECRET_ACCESS_KEY:-miniosecret} # CHANGEME
LANGFUSE_S3_BATCH_EXPORT_FORCE_PATH_STYLE: ${LANGFUSE_S3_BATCH_EXPORT_FORCE_PATH_STYLE:-true}
LANGFUSE_INGESTION_QUEUE_DELAY_MS: ${LANGFUSE_INGESTION_QUEUE_DELAY_MS:-}
LANGFUSE_INGESTION_CLICKHOUSE_WRITE_INTERVAL_MS: ${LANGFUSE_INGESTION_CLICKHOUSE_WRITE_INTERVAL_MS:-}
REDIS_HOST: ${REDIS_HOST:-langfuse-redis}
REDIS_PORT: ${REDIS_PORT:-6379}
REDIS_AUTH: ${REDIS_AUTH:-myredissecret} # CHANGEME
REDIS_TLS_ENABLED: ${REDIS_TLS_ENABLED:-false}
REDIS_TLS_CA: ${REDIS_TLS_CA:-/certs/ca.crt}
REDIS_TLS_CERT: ${REDIS_TLS_CERT:-/certs/redis.crt}
REDIS_TLS_KEY: ${REDIS_TLS_KEY:-/certs/redis.key}
EMAIL_FROM_ADDRESS: ${EMAIL_FROM_ADDRESS:-}
SMTP_CONNECTION_URL: ${SMTP_CONNECTION_URL:-}
networks:
- langfuse-otel-net
langfuse-web:
image: docker.io/langfuse/langfuse:3
restart: always
depends_on: *langfuse-depends-on
ports:
- 3000:3000
environment:
<<: *langfuse-worker-env
NEXTAUTH_SECRET: ${NEXTAUTH_SECRET:-mysecret}
# 初始化 Org / Project
LANGFUSE_INIT_ORG_ID: ${LANGFUSE_INIT_ORG_ID:-llm-assistance}
LANGFUSE_INIT_ORG_NAME: ${LANGFUSE_INIT_ORG_NAME:-LLM Assistance Org}
LANGFUSE_INIT_PROJECT_ID: ${LANGFUSE_INIT_PROJECT_ID:-llm-assistance}
LANGFUSE_INIT_PROJECT_NAME: ${LANGFUSE_INIT_PROJECT_NAME:-LLM Assistance Project}
LANGFUSE_INIT_PROJECT_PUBLIC_KEY: ${LANGFUSE_PUBLIC_KEY}
LANGFUSE_INIT_PROJECT_SECRET_KEY: ${LANGFUSE_SECRET_KEY}
# 初始化使用者 (選填)
LANGFUSE_INIT_USER_EMAIL: ${LANGFUSE_INIT_USER_EMAIL:-admin@example.com}
LANGFUSE_INIT_USER_NAME: ${LANGFUSE_INIT_USER_NAME:-admin}
LANGFUSE_INIT_USER_PASSWORD: ${LANGFUSE_INIT_USER_PASSWORD:-changeme123}
networks:
- langfuse-otel-net
env_file:
- .env
langfuse-clickhouse:
image: docker.io/clickhouse/clickhouse-server
restart: always
# user: "101:101"
environment:
CLICKHOUSE_DB: default
CLICKHOUSE_USER: clickhouse
CLICKHOUSE_PASSWORD: clickhouse # CHANGEME
volumes:
- ./obs_data/langfuse_clickhouse_data:/var/lib/clickhouse
- ./obs_data/langfuse_clickhouse_logs:/var/log/clickhouse-server
ports:
- 127.0.0.1:8123:8123
- 127.0.0.1:9000:9000
healthcheck:
test: wget --no-verbose --tries=1 --spider http://localhost:8123/ping || exit 1
interval: 5s
timeout: 5s
retries: 10
start_period: 1s
networks:
- langfuse-otel-net
langfuse-minio:
image: docker.io/minio/minio
restart: always
entrypoint: sh
# create the 'langfuse' bucket before starting the service
command: -c 'mkdir -p /data/langfuse && minio server --address ":9000" --console-address ":9001" /data'
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: miniosecret # CHANGEME
ports:
- 9091:9000
- 127.0.0.1:9092:9001
volumes:
- ./obs_data/langfuse_minio_data:/data
healthcheck:
test: [ "CMD", "mc", "ready", "local" ]
interval: 1s
timeout: 5s
retries: 5
start_period: 1s
networks:
- langfuse-otel-net
langfuse-redis:
image: docker.io/redis:7
restart: always
# CHANGEME: row below to secure redis password
command: >
--requirepass ${REDIS_AUTH:-myredissecret}
ports:
- 127.0.0.1:6380:6379
healthcheck:
test: [ "CMD", "redis-cli", "ping" ]
interval: 3s
timeout: 10s
retries: 10
networks:
- langfuse-otel-net
langfuse-postgres:
image: docker.io/postgres:${POSTGRES_VERSION:-latest}
restart: always
healthcheck:
test: [ "CMD-SHELL", "pg_isready -U postgres" ]
interval: 3s
timeout: 3s
retries: 10
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres # CHANGEME
POSTGRES_DB: postgres
ports:
- 127.0.0.1:5432:5432
volumes:
- ./obs_data/langfuse_postgres_data:/var/lib/postgresql/data
networks:
- langfuse-otel-net
注意,這樣我就不用再去 langfuse-web localhost:3000 取得 key,變成我的key 我自己設定
LANGFUSE_INIT_PROJECT_PUBLIC_KEY: ${LANGFUSE_PUBLIC_KEY}
LANGFUSE_INIT_PROJECT_SECRET_KEY: ${LANGFUSE_SECRET_KEY}
就是先前介紹的 FastAPI
Dockerfile.noteserver 參考補充部分 Day16 | RAG 的全流程(上):用 FastAPI 將 RAG 魔法包裝成後端 API
.env
LANGFUSE_HOST=http://langfuse-web:3000 # Self-hosted Langfuse URL
# LANGFUSE_HOST = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# Generate these keys from your self-hosted Langfuse UI at http://localhost:3000
LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
pip show langfuse
Name: langfuse
Version: 2.60.9
Summary: A client library for accessing langfuse
Home-page:
Author: langfuse
Author-email: developers@langfuse.com
License: MIT
Location: /usr/local/lib/python3.10/site-packages
Requires: anyio, backoff, httpx, idna, packaging, pydantic, requests, wrapt
Required-by:
第一次跑起來看到 dashboard,那瞬間就像第一次成功連上 production DB 一樣——
緊張、興奮、還有一絲絲後悔。
觀測這件事,其實跟人生很像。
當你不觀測自己,錯誤就會重複。
你只會以為「啊,這次只是運氣不好」,
但其實是「embedding latency 爆炸」。
Langfuse 給了我們那面鏡子,
讓你看到自己系統裡那些微妙又致命的小缺陷。
它不會讓模型更聰明,
但會讓你更冷靜。
而在這個 prompt 每天都在變、token 每天都在漲價的世界裡,
「冷靜」本身,就是最珍貴的能力。
你知道嗎?
有時候我在 Langfuse dashboard 裡,看著那些 trace,
就像在看自己一整天的 debug 流程。
embedding_span:早上試著理解人生。
retrieval_span:查資料。
rerank_span:重新思考選擇。
generation_span:終於開口說話。
每一次 trace 都是一次「思考的 replay」。
而我發現,系統能觀測、自己也能觀測。
不只是看執行時間,也看那段卡住的地方。
所以啊,
下一次你的模型開始胡說八道,
別急著罵它笨。
也許它只是在演你。
觀測不只是為了找錯誤,而是為了理解。
Langfuse 讓我們從黑箱中走出來,看到整個 RAG pipeline 的「呼吸」。
而理解系統的那一刻,也許你也會更理解自己。
client - factory - tracer
client:class LangfuseTracer
tracer:class RAGTracer
class LangfuseTracer:
def __init__(self, settings: Settings):
self.settings = settings.langfuse
self.client: Optional[Langfuse] = None
if (
self.settings.enabled
and self.settings.public_key
and self.settings.secret_key
):
try:
self.client = Langfuse(
public_key=self.settings.public_key,
secret_key=self.settings.secret_key,
host=self.settings.host,
flush_at=self.settings.flush_at,
flush_interval=self.settings.flush_interval,
debug=self.settings.debug,
)
logger.info(
f"Langfuse tracingclient initialized (host: {self.settings.host})"
)
except Exception as e:
logger.error(f"Failed to initialize Langfuse: {e}")
self.client = None
else:
logger.info("Langfuse tracing disabled or missing credentials")
@contextmanager
def trace_rag_request(
self,
query: str,
user_id: Optional[str] = None,
session_id: Optional[str] = None,
metadata: Optional[Dict[str, Any]] = None,
):
if not self.client:
yield None
return
try:
# Create a trace using v2 API
trace = self.client.trace(
name="rag_request",
input={"query": query},
metadata=metadata or {},
user_id=user_id,
session_id=session_id,
)
yield trace
except Exception as e:
logger.error(f"Error creating Langfuse trace: {e}")
yield None
def create_span(
self,
trace,
name: str,
input_data: Optional[Dict[str, Any]] = None,
metadata: Optional[Dict[str, Any]] = None,
):
if not trace or not self.client:
return None
try:
# Create a span using v2 API
return self.client.span(
trace_id=trace.trace_id,
name=name,
input=input_data,
metadata=metadata or {},
)
except Exception as e:
logger.error(f"Error creating span {name}: {e}")
return None
def update_span(
self,
span,
output: Optional[Any] = None,
metadata: Optional[Dict[str, Any]] = None,
level: Optional[str] = None,
status_message: Optional[str] = None,
):
if not span:
return
try:
# For v2 API, we can update spans with end_time and output
if output is not None:
# Update the span with output data
span.update(output=output)
if metadata:
span.update(metadata=metadata)
if level:
span.update(level=level)
if status_message:
span.update(status_message=status_message)
except Exception as e:
logger.error(f"Error updating span: {e}")
def end_span(
self,
span,
output: Optional[Any] = None,
metadata: Optional[Dict[str, Any]] = None,
):
if not span:
return
try:
# Update with final data if provided
if output is not None or metadata is not None:
self.update_span(span, output=output, metadata=metadata)
# End the span to capture proper timing
span.end()
except Exception as e:
logger.error(f"Error ending span: {e}")
def flush(self):
if self.client:
try:
self.client.flush()
except Exception as e:
logger.error(f"Error flushing Langfuse: {e}")
from functools import lru_cache
from config import get_settings
from services.langfuse.client import LangfuseTracer
@lru_cache(maxsize=1)
def make_langfuse_tracer() -> LangfuseTracer:
settings = get_settings()
return LangfuseTracer(settings)
@lru_cache(maxsize=1) singleton可以自己增加,要trace 甚麼,最基本的 LLM
from contextlib import contextmanager
from typing import Dict, List
from services.langfuse.client import LangfuseTracer
class RAGTracer:
def __init__(self, tracer: LangfuseTracer):
self.tracer = tracer
@contextmanager
def trace_request(self, user_id: str, query: str):
with self.tracer.trace_rag_request(
query=query,
user_id=user_id,
session_id=f"session_{user_id}",
metadata={"simplified_tracing": True},
) as trace:
try:
yield trace
finally:
if trace:
self.tracer.flush()
@contextmanager
def trace_embedding(self, trace, query: str):
span = self.tracer.create_span(
trace=trace,
name="query_embedding",
input_data={"query": query, "query_length": len(query)},
)
try:
yield span
finally:
if span:
self.tracer.update_span(
span=span,
output={
"success": True,
},
)
span.end()
def end_embedding(self, span, embedding_vector: list[float]):
if not span:
return
self.tracer.update_span(
span=span,
output={
"embedding_length": len(embedding_vector),
"embedding_vector_preview": embedding_vector[
:10
], # 只取前10個元素避免過長
},
)
span.end()
@contextmanager
def trace_search(self, trace, query: str, top_k: int, search_mode: str):
span = self.tracer.create_span(
trace=trace,
name="search_retrieval",
input_data={"query": query, "top_k": top_k, "search_mode": search_mode},
)
try:
yield span
finally:
if span:
span.end()
def end_search(
self, span, chunks: List[Dict], arxiv_ids: List[str], total_hits: int
):
if not span:
return
self.tracer.update_span(
span=span,
output={
"chunks_returned": len(chunks),
"unique_papers": len(set(arxiv_ids)),
"total_hits": total_hits,
"arxiv_ids": list(set(arxiv_ids)),
},
)
@contextmanager
def trace_rerank(
self, trace, query: str, vector_weight: float = 0.6, bm25_weight: float = 0.3
):
span = self.tracer.create_span(
trace=trace,
name="rerank",
input_data={
"query": query,
"vector_weight": vector_weight,
"bm25_weight": bm25_weight,
},
)
try:
yield span
finally:
if span:
span.end()
def end_rerank(self, span, reranked_chunks: list[dict]):
if not span:
return
self.tracer.update_span(
span=span,
output={
"reranked_chunk_count": len(reranked_chunks),
"top_chunk_ids": [c.get("arxiv_id") for c in reranked_chunks[:10]],
"top_scores": [c.get("total_score") for c in reranked_chunks[:10]],
},
)
@contextmanager
def trace_prompt_construction(self, trace, chunks: List[Dict]):
"""Prompt building with timing."""
span = self.tracer.create_span(
trace=trace,
name="prompt_construction",
input_data={"chunk_count": len(chunks)},
)
try:
yield span
finally:
if span:
span.end()
def end_prompt(self, span, prompt: str):
if not span:
return
self.tracer.update_span(
span=span,
output={
"prompt_length": len(prompt),
# Don't duplicate the full prompt here since it's in llm_generation input
"prompt_preview": prompt[:200] + "..." if len(prompt) > 200 else prompt,
},
)
@contextmanager
def trace_generation(self, trace, model: str, prompt: str):
span = self.tracer.create_span(
trace=trace,
name="llm_generation",
input_data={"model": model, "prompt_length": len(prompt), "prompt": prompt},
)
try:
yield span
finally:
if span:
span.end()
def end_generation(self, span, response: str, model: str):
if not span:
return
self.tracer.update_span(
span=span,
output={
"response": response,
"response_length": len(response),
"model_used": model,
},
)
def end_request(self, trace, response: str, total_duration: float):
"""End main request trace."""
if not trace:
return
try:
trace.update(
output={
"answer": response,
"total_duration_seconds": round(total_duration, 3),
"response_length": len(response),
}
)
except Exception:
pass
ask_flow
langfuse_tracer = LangfuseTracer(settings)
rag_tracer = RAGTracer(langfuse_tracer)
with rag_tracer.trace_request(request.user_id, ask_r.query) as trace:
├── embedding_span : get_embedding
├── search_span : search relevant chunks
├── rerank_span : re_rank
├── prompt_span: build prompt
├── gen_span : generate reponse
rag_tracer.end_request(trace, response.answer, time.time() - start_time)
with rag_tracer.trace_embedding(trace, query=query) as embedding_span:
query_embedding = get_embedding(query)
rag_tracer.end_embedding(embedding_span, query_embedding)
with rag_tracer.trace_search(
trace, query=query, top_k=top_k, search_mode=search_mode
) as search_span:
logger.info(f"Hybrid search enabled: {system_settings.hybrid_search}")
chunks, sources, msg, arxiv_ids, total_hits = qdrant_client.search(
query=query,
query_vector=query_embedding,
size=top_k * 2, # retrieve more for reranking
min_score=0.3,
hybrid=system_settings.hybrid_search,
categories=categories,
)
rag_tracer.end_search(search_span, chunks, arxiv_ids, total_hits)
with rag_tracer.trace_rerank(
trace, query=query, vector_weight=vector_weight, bm25_weight=bm25_weight
) as rerank_span:
reranked = re_ranking(
chunks,
query,
vector_weight=vector_weight,
bm25_weight=bm25_weight,
)
rag_tracer.end_rerank(rerank_span, reranked)
with rag_tracer.trace_prompt_construction(trace, chunks) as prompt_span:
try:
prompt_data = ollama_client.prompt_builder.create_structured_prompt(
query, chunks, system_settings.user_language
)
final_prompt = prompt_data["prompt"]
except Exception:
final_prompt = ollama_client.prompt_builder.create_rag_prompt(
query, chunks, system_settings.user_language
)
rag_tracer.end_prompt(prompt_span, final_prompt)
with rag_tracer.trace_generation(trace, model, final_prompt) as gen_span:
parsed_response, response = await ollama_client.generate_rag_answer(
query=query,
chunks=chunks,
user_language=system_settings.user_language,
use_structured_output=False,
temperature=system_settings.temperature,
)
rag_tracer.end_generation(gen_span, response, model)


 iThome鐵人賽
iThome鐵人賽