當AI成為歧視的放大器
昨天我們見證了GPT-5的推理革命,許多朋友在互動區分享了對AI偏見領域的看法。有人擔心招聘AI會歧視女性,有人關注AI在醫療診斷上的種族偏見,還有人質疑AI是否會加劇社會不平等。
而今天,我要與你們一起揭開一個令人不安的真相:我們創造出來拯救世界的AI,可能正在重複人類最黑暗的偏見。
2018年,亞馬遜宣布停止使用AI篩選求職履歷,因為這個系統嚴重偏好男性應聘者。2024年,華盛頓大學的研究發現,最新的大型語言模型在85%的情況下優先選擇白人姓名,而從未在白人男性姓名存在時選擇黑人男性姓名。
這不是個案,而是一面鏡子,映照出我們社會深層的偏見問題。
逆轉思維:AI不是中性的,它是人類偏見的繼承者
讓我先問你一個問題:你認為AI應該是公正無私的嗎?
大多數人會毫不猶豫地回答「是」。我們總是假設機器比人類更客觀,算法比直覺更公平。但這個假設本身就是一個危險的幻象。
人工智慧偏見是指嵌入AI系統的系統性歧視,可能會強化現有偏見,並擴大歧視、偏見和刻板化。AI模型中的偏見通常有兩個來源:模型本身的設計,以及所使用的訓練資料。
想像一下,如果你要教一個孩子認識世界,但你給他的所有書籍都充滿了偏見和刻板印象,這個孩子長大後會怎麼看世界?AI就是這樣的孩子,而我們的數據就是那些有偏見的書籍。
偏見陷阱的三大根源
在我們共同探索AI偏見的過程中,發現了三個核心的偏見來源: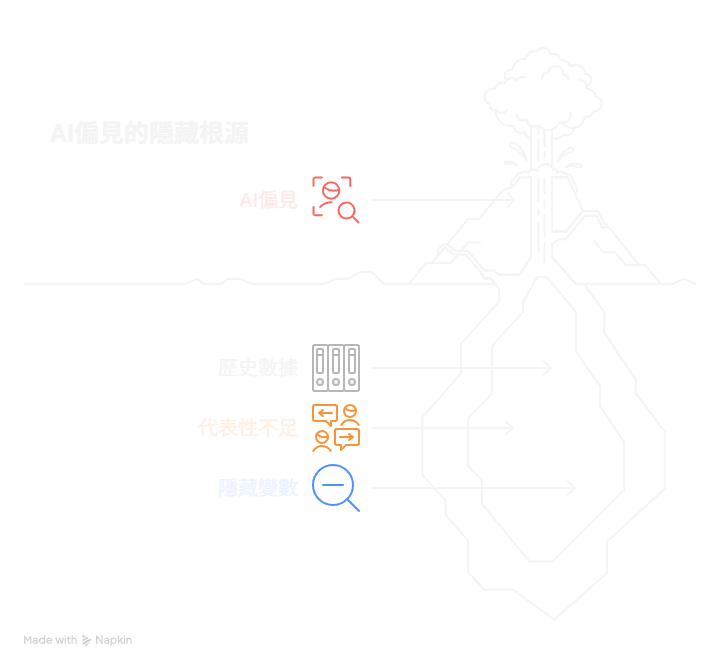
根源一:歷史數據的詛咒
AI模型學習的是過去的數據,而過去的數據往往反映了社會的不平等。當AI學習歷史上男性主導的管理職位數據時,它會「合理」地推斷出男性更適合領導職位。
**實例:**Amazon的招聘AI因為學習了過去十年以男性為主的履歷數據,開始自動降低包含「女性」相關詞彙(如「女子國際象棋俱樂部隊長」)的履歷評分。
根源二:代表性不足的偏差
訓練數據如果缺乏多樣性,AI就會對少數群體產生偏見。這不是惡意,而是「無知」——AI沒有足夠的數據來理解和公平對待所有群體。
**實例:**早期的人臉識別系統在識別深膚色女性時錯誤率高達35%,但識別淺膚色男性時錯誤率僅為0.8%,因為訓練數據主要來自淺膚色男性的照片。
根源三:隱藏變數的陷阱
有時候,看似中性的數據背後隱藏著歧視性的關聯。郵遞區號可能與種族相關,學校名稱可能與社經地位相關,這些「代理變數」讓歧視以隱蔽的方式延續。
**實例:**貸款審核AI可能不直接考慮種族,但通過郵遞區號和購物習慣等間接指標,仍然對特定族群產生系統性歧視。
偏見的真實面孔:五個震撼案例
讓我們一起審視AI偏見在現實世界中的具體表現:
案例一:招聘歧視的數位化
華盛頓大學的最新研究分析了550份真實履歷,發現AI工具在篩選求職者時存在顯著的種族和性別偏見:
85%的情況下優先選擇白人相關姓名
僅11%的情況下偏好女性姓名
白人男性姓名最受青睞,黑人男性姓名偏好率僅15%
研究涵蓋超過300萬次履歷比對
案例二:廣告投放的不平等
Google廣告系統會根據性別推送不同類型的職位廣告,男性更容易看到高薪主管職位的廣告,女性則更多接收普通職位廣告,這意味著AI在機會分配上就開始了不平等。
案例三:司法系統的偏見循環
美國的COMPAS系統用於預測罪犯再犯率,但分析發現該系統對黑人被告的再犯風險評估偏高,對白人被告偏低,直接影響刑期判決和保釋決定。
案例四:醫療診斷的種族盲點
一些醫療AI系統在診斷皮膚癌時,對深膚色患者的準確率明顯低於淺膚色患者,因為訓練數據主要來自淺膚色人群的病例。
案例五:語音識別的語言歧視
主流語音識別系統對非標準口音的識別率較低,這在客服、面試等場景中可能對特定族群造成不利影響。
破解偏見的五大策略
面對這些挑戰,我們該如何建立更公平的AI系統?在探索過程中,我們發現了五個關鍵策略: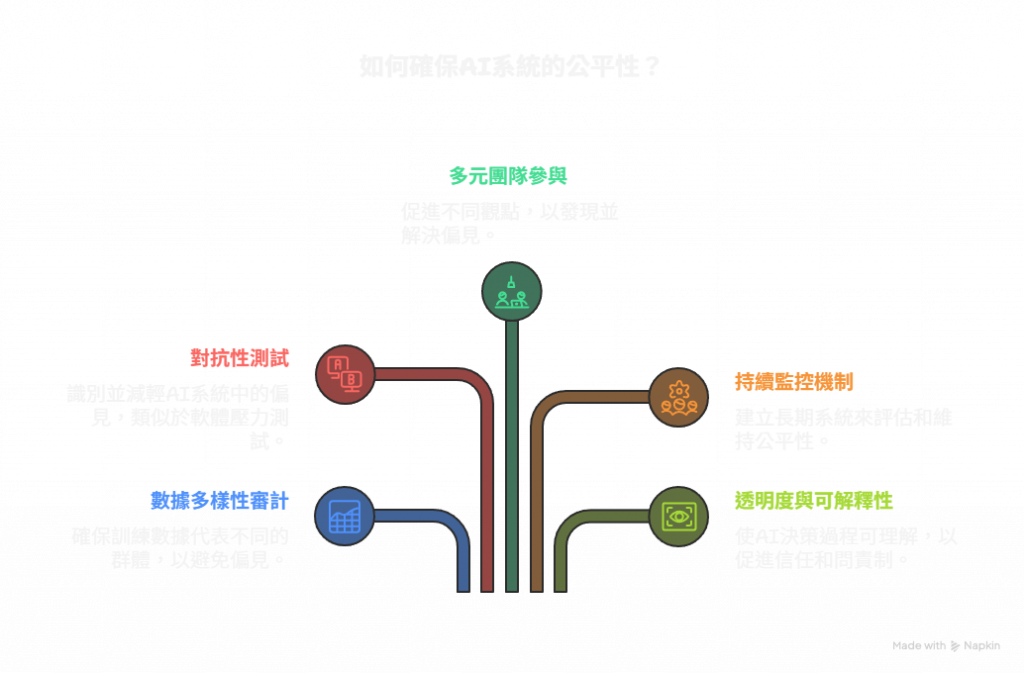
策略一:數據多樣性審計
定期檢視訓練數據的組成,確保各個群體都有足夠的代表性。這不只是數量問題,更是質量問題——要確保數據真實反映不同群體的多樣性。
實用技巧:
建立數據組成檢核表,包含性別、種族、年齡、地理分布、社經地位等維度的統計分析。
策略二:對抗性測試
刻意設計測試案例來探測AI系統的偏見,就像軟體的壓力測試一樣。
測試方法:
性別切換測試:將履歷中的性別資訊對調,觀察評分變化
種族名稱測試:使用不同族群的典型姓名測試同樣的履歷
地區偏見測試:測試不同地區背景對結果的影響
策略三:多元團隊參與
確保AI開發團隊本身就具有多樣性,不同背景的人更容易發現潛在的偏見問題。
策略四:持續監控機制
建立長期的偏見監控系統,定期評估AI系統在實際應用中的公平性表現。
策略五:透明度與可解釋性
讓AI的決策過程可以被審查和理解,這樣偏見問題才能被及時發現和修正。
公平性的哲學思辨
在這個探索過程中,我們遇到了一個更深層的問題:什麼是「公平」?
**機會均等:**每個人都有相同的機會被AI系統公平對待
**結果均等:**AI系統的結果在不同群體間保持平衡
**個體公平:**相似的個體應該得到相似的對待
**群體公平:**不同群體整體上應該得到公平對待
這些定義之間有時會產生衝突。追求結果均等可能會犯「逆向歧視」的錯誤,而堅持機會均等可能會延續既有的不平等。
企業的偏見責任與AI驗證
2025年,隨著AI技術的普及,偏見問題已經成為企業必須面對的關鍵挑戰。企業不只要增強數據多樣性、採用公平性指標,更要建立系統性的AI決策驗證機制。
企業級的多模型驗證框架:
當企業使用AI做重要決策時(如人才招聘、貸款審核、產品推薦),應該:
建立AI委員會:使用多個不同供應商的AI模型進行交叉驗證
統計分析共識:如同前面案例,計算模型間的一致性指標
識別異常值:特別注意某個模型顯著偏離共識的情況
人工最終審核:AI提供建議,人類做最終決策
重要原則:AI輔助,人類負責
正如那位AI專家所警告的:「戰略問題沒有標準答案。用AI來驗證和檢驗,但不應該純粹依賴AI。你的領域知識、同儕意見、客觀數據和人類判斷應該是首要考慮——然後用AI來交叉檢驗。」
這不只是道德責任,更是商業風險管理。偏見問題可能導致:
法律訴訟和監管處罰
品牌形象受損
人才流失
市場機會的喪失
探索航道的轉機
理解了AI偏見的複雜性後,我們面臨著一個更根本的問題:在AI時代,隱私的邊界在哪裡?
明天,我們將一起探索隱私與監控的邊界。當AI能夠分析我們的每一個行為模式時,我們該如何保護個人隱私?當便利性與隱私性產生衝突時,我們該如何選擇?
這個問題比偏見更加隱蔽,也更加危險。
偏見覺醒的意義
今天的探索讓我們理解:AI偏見不是技術問題,而是人性問題。我們創造的AI系統反映了我們社會的價值觀和偏見。
改變AI偏見的關鍵,不只在於改進算法,更在於改變我們自己。當我們開始審視AI系統的偏見時,我們其實是在審視自己內心的偏見。
這面鏡子可能讓人不舒服,但這是我們走向更公平未來的必經之路。
未完待續 —— Day 10,「誰在看你?隱私與監控的戰爭即將開始,而你可能已經輸了。」
互動交流:你最在意的隱私是什麼?
【30天AI終極挑戰】Day 9 完成 | 明日預告:《隱私之盾 — 個資與監控的邊界》


 iThome鐵人賽
iThome鐵人賽