延續昨天的議題,我想從另外一個角度來聊一下 Microservice Architecture Pattern 這件事。在昨天提到這個是一系列模式組成的 Pattern Language,你可以把它看成一種「地圖」,指引我們思考相關的問題。
再來,我們以下圖來討論關於微服務的議題:
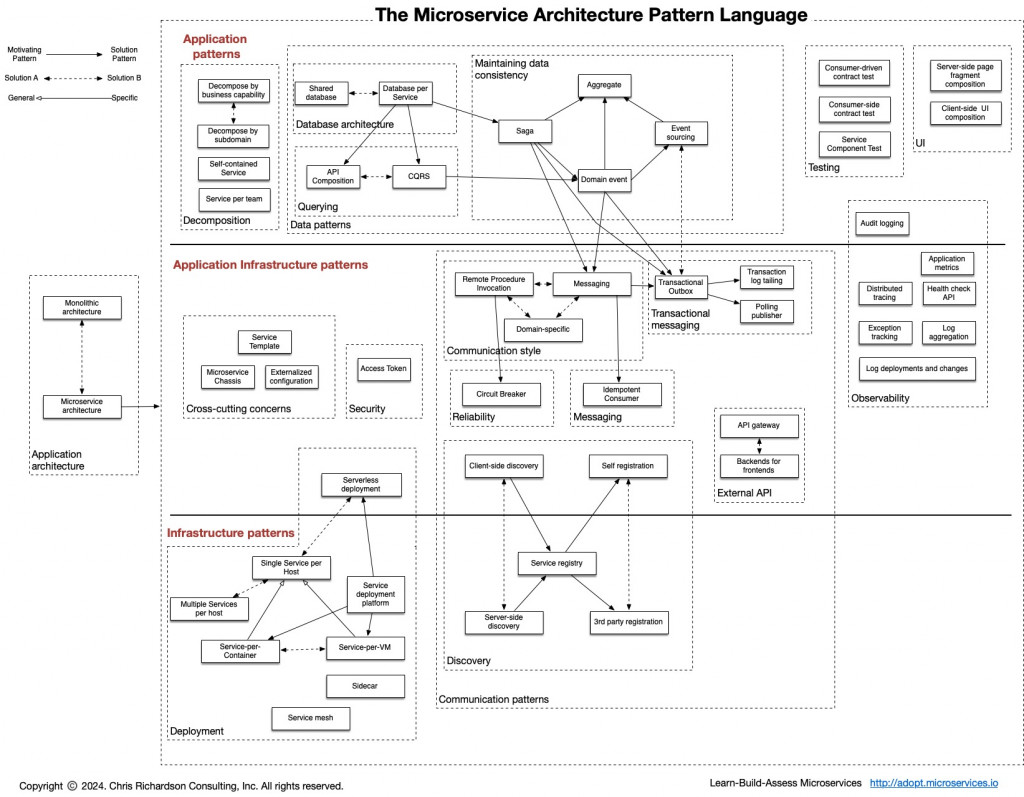
有別於前一篇我們拿了一張 Releated Pattern 的圖來說明,那張圖想表達的是「問題」到「解決」方案的模型,而這張圖我們可以用另外一個維度來看。
從這張圖上,首先我們可以分成三層式的分割點「Application Patterns」、「Application Infrastructure Patterns」及「Infrastructure Patterns」,我們將分幾個片段逐一說明。
應用模式,主要關注點在於應用程式開發的部分,屬於 Developer 關注的議題,底下是在應用模式層的幾個模式。所以,作為應用程式的開發人員可能會先從這部分理解「微服務」。
通常來說,這部分可能也是在導入微服務的時候「第一個層面」會被接觸跟考慮的幾個問題點。
老問題,怎樣切割才是一個「微服務」,應該多小才是「微」服務 (我聽過最極致的是一個 Function 是一個服務)。如先前所示,一個合適的大小對於不同公司、不同團隊其實都代表著不同意義,不會有標準答案。
在這個模式中,有幾個可以做為服務拆分的原則:
依據業務能力拆分
企業做生意所需的「能力」下刀,強調「公司能做什麼」,與資料/流程無關,例如「獲客」「下單」「收款」「配送」「客服」。這個拆分方式通常與「康威定律」所描述的很像,與組織、KPI、預算容易對齊,穩定度高(除非你們公司一天到晚改)。
依據子領域拆分
從 DDD 的子網域/界限上下文(Bounded Context)下刀,例如在「銷售」這個大能力之內再分成:定價、促銷規則、訂單、付款、庫存等語意獨立的子網域。這裡就會點出為什麼在談微服務的時候都會討論到「領域驅動設計,Domain Driven Design」的議題。可視為在「業務能力」底下再進一步的分割(通常也不會有一個系統涵蓋整個公司所有業務的,所以微服務也可能針對特定業務領域來做子領域的切割)。
自治服務
這個模式可能不是像前兩個模式一樣是告訴你如何從既有系統中分割出服務的方法。它的主旨是「降低同步的耦合」,以達到獨立部署的能力。所以,可以說是一個我們在設計微服務方案是可以檢視的「設計原則」,越是可以做到服務的自治,系統在面對修改時會產生的 side effect 就越小 (這就是一個夢想中的設計模型,但不好達到)。
專屬團隊維護
很多時候,會聽到微服務適合用敏捷的方法論來開發,這點我也是蠻認同的。先別扯那麼遠,這個議題是談「團隊」,我引用「敏捷的概念」主要是想表示一件事「跨職能團隊」。這個團隊應該具備完成這個微服務的一切技能。再來,就是一個服務只有一個團隊來維護,代表的是改變來源只有一個,這個團隊知道服務內的所有事。
「Service per Team」將服務所有權與團隊邊界對齊,讓團隊能以最少協調成本,快速而可靠地交付價值,同時維持架構的鬆耦合與可演進性。
(很多人看到這個模式就很高興,但想仔細一點,這個模式並沒有交代一個團隊只能做一個微服務!)
在 Data Patterns 這個區段中,是我們討論微服務架構中我覺得第一個遇到的障礙門檻,知道要做這件事,但很不好做。
共享資料庫 (Shared Database)
很多時候,我們會開始處理既有系統服務的分拆,當我們在應用層抽離出新的服務之後,通常就是還在使用原本資料庫的狀態,這時候兩個系統還在使用同一個資料庫的情境就是「共用資料庫」。基本上,共用資料庫在微服務中通常是一個「反模式」,因為代表兩個系統之間可能存在高度的耦合而不能獨立修改、獨立部署。
所以,通常會建議拆成每一個服務有獨立的資料庫,很多建構微服務的文獻跟書籍都是這樣講的,但是目前我經手的相關專案都很難完成這個任務。當然,當共享資料庫沒有真的形成問題之前,或許也無坊。畢竟,很多時候其實也不是真的需要「微服務」來解決問題。
服務獨立資料庫 (Database per service)
講大白話就是每一個服務有自己的資料庫,通常此話一出,業主就會開始問你講認真的嗎 (因為很多業主的資料庫都是需要商業授權的,這意味著更多的授權費用)?這時候,我們就要反思這個模式想要解決的問題到底是什麼?
Services must be loosely coupled so that they can be developed, deployed and scaled independently
所以,目的是「獨立開發」、「獨立部署」、「獨立擴容」而不是讓資料庫的 Vendor 發大財 (不過,說不定這是不是資料庫原廠提出的就不得而知了!陰謀論 ....)。所以,在同一個 DBMS 中啟用多的 DB Instance 或是用 Schema 等來做到邏輯隔離,其實也就滿足此一概念。
原則上是這樣,拆分資料庫可能是一件很難的事情,但 Database per service 是被認為是微服務中資料庫處理模式較好的一個 (至少,目前只有看到 Shared Database 跟 Database per service)。所以,可以的話就盡量往這個模式走。
談點實際的,如果你想對既有系統拆分資料庫,這件事情風險也很大!尤其是系統又大又複雜的時候,你也無法確定這個部分的資料是否被既有系統中的其他應用程式參照,改東壞西的問題可能會經常冒出。除非,你很有把握,不然通常這樣做的結果可能付出的比得到的多(但,你的系統已經高度模組化,且從被依賴性比較低的模組處理或許還可行)。
所以,把抽出的服務直接用新的資料庫而不是去動既有系統或許才是比較可行的!只是,這樣就又會有「資料同步」的問題需要額外處理。難怪這麼多人不想面對這個問題,因為他是一個一個問題緊扣的情境,需要過五關斬六將才能做好這件事吧!
這件事知道很簡單,但要做很難
那,上面的「關卡」其實就在下面,而且都是 Data Patterns 中的一個相關模式中。分別有「服務組合」、「讀寫分離」、「資料一致性」等概念。基本上,你往 Database per service 這步邁進的時候,「坑」早就準備好了!
你要很「自律」地完成下列相關的模式一一解決產生的副作用,才會到達一個比較好的狀態。
對於,服務獨立資料庫引發的副作用及解決方案,可能就要下回分解了!
針對「微服物架構模式」才剛開始的篇章,交代了「服務拆解」與「資料模式」兩個最初的概念後,發現篇幅已經拉這麼長了!還有許多模式的「概念」還沒交代,礙於時間跟篇幅只好先在這邊做一個段落,待下一篇文章再來看看「服務獨立資料庫」引發的相關問題該如何處置。
微服務的改造重點不是一次到位,而是有紀律的演進:先釐清服務邊界與擁有權,保守引入 Database per service,配合查詢與一致性的配套模式;我們有可能永遠不會把整個系統完全微服務化,找出你最重要的部分來進行這件事情持續觀察這樣的改變是否有更加協助你接近想要的商業目標才是關鍵。
都說是 VUCA 時代,市場變化非常快速,沒有人會等你把系統都重構完後才開始商場上的競爭,隨時關注當下最重要的事情比把整個系統都「微服務」來得重要。


 iThome鐵人賽
iThome鐵人賽