
在上一個篇章,我們走 Data Patterns 剛打開 Database Architecture 的迷宮,談了「Shared Database」以及「Database per service」兩個議題,也發現 Database per service 雖然是大家談論的主軸,但是其所帶來的副作用也不小。
所以,我們回顧 Microsoft Architecture Pattern 的圖示,然後再檢視一下 Data Patterns 的範圍,大概可以知道需要考慮「查詢」與「維護資料一致性」的問題。
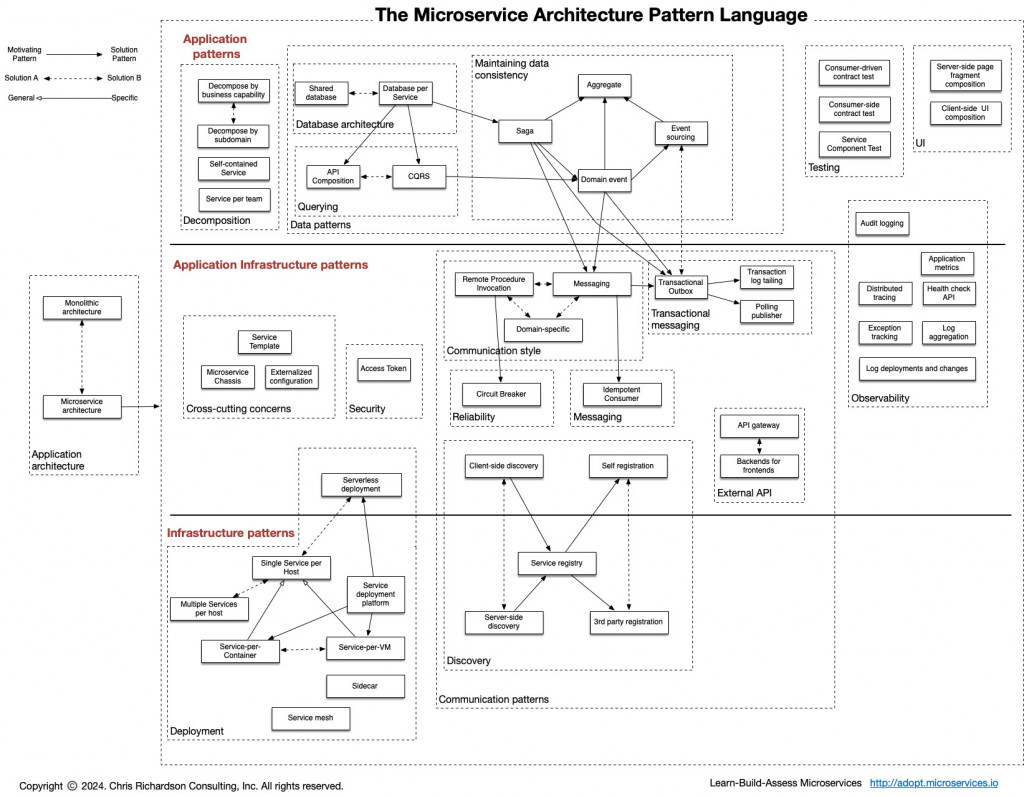
當你不再可以繼續接觸其他服務的資料庫,一切都要從 API 的角度來完成整合的業務。
當我們採用微服務架構並且遵循服務獨立資料庫(Database per service)的設計時,你可能就要開始解決過去在多個服務間進行關聯查詢的問題。因為,Join 這件事已經不復存在了!
這件事情通常是一個關鍵的攻防點!在此時,我接到最多的抱怨就是「這樣效能會變很差」(因為需要 Join)!
這時候,我們應該反思一件事,經常需要 join 的資料應該被放在同一個服務(或同一個 bounded context/聚合);若只是查詢需求而非強一致的交易規則,則只需要建立一個讀取的副本,不把服務邊界硬綁在一起。
所以,效能的問題並不是因為你使用 API 造成的,更多可能源自於「設計」,透過建立資料的副本來換取效率其實也是一種做法。
通常我們導入 API Gateway 就支援著此模式
這個概念在上一個世紀的時候叫 CQS (Command-Query Separation),主旨是「命令改變狀態、不回傳資料;查詢回傳資料、不改變狀態」。在這個時候主要是「物件導向」的世代,提出了「讀寫分離」的核心概念。
2000 年代後期,在 DDD(領域驅動設計)社群中,有人將 CQS 的理念提升到系統層級,主張把寫入模型(命令)與讀取模型(查詢)分離為兩套模型/儲存,以便各自最佳化與獨立擴展,並用最終一致連結兩邊。
這個模式的目的是將「改變狀態的複雜性」與「讀取效率」分離,避免一個通用模型同時滿足兩種衝突需求。
在實作上,我們可以定義一個唯讀資料庫(view database):它是一個「副本」,專門為某個查詢,或一組相關查詢而設計。應用程式透過訂閱由資料擁有服務發布的網域事件(Domain events),來持續更新這個資料庫。其資料庫型態與 Schema 會針對該查詢(或查詢組)做最佳化;常見選擇是 NoSQL,例如文件型資料庫或鍵值儲存。
在這裡揭露了「交易資料庫」與「報表資料庫」分離的概念
當你採用 Database per Service,每個服務都擁有自己的資料庫。此時,單一業務交易(如「建立訂單且需確認有庫存可以發貨」)往往橫跨多個服務/資料庫,無法用一筆本地 ACID 交易完成。
Saga 模式正是為此而生:把一個長交易拆成一串本地交易(Local Transactions),每一步成功後發出事件或呼叫下一步;若其中任一步失敗,則依序執行對應的補償動作(Compensation)來回滾先前已完成的效果,最終達成最終一致(Eventual Consistency)。
在大約 20 年前,我那時候在研究服務導向架構相關產品時,有一個 Business Process Management (BPM)的應用。在 BPM 中,每一個活動都是一個獨立的 Webservice (時空轉換一下就會是 API),這時候 Webservice 也是無狀態的,在 BPM 中也是在每一步成功後往下一步進行。如果中間某個動作失敗了,因為也沒有 ACID 的保護,所以我們必須設定一個 Compensation 的方法,呼叫一個回沖的 Webservice,理念與 Saga 模式如初一徹。
所以,這些概念並不是因為微服務發明出來的,而是因為前人一直解決類似問題所留下智慧的結晶。
Saga 的實作模式可以分成下列兩種類型:
Aggregate(聚合)是 DDD 的一致性邊界:把一組強關聯的實體與 Value Object 包起來,由聚合根(Aggregate Root)對外代表整個聚合並守護不變式(Invariants)。對聚合的所有修改必須透過聚合根,並在單一本地交易中完成,確保狀態始終有效。(以 ACID 為主的範疇)
Event Sourcing 是把事件序列作為唯一真相(source of truth)的持久化方式:每次狀態改變都記為不可變事件(append-only),當前狀態則由「重播(replay)事件」或「快照(snapshot)+增量事件」計算而得。與傳統「只存最新狀態」不同,Event Sourcing 同時保存了完整變更歷史與審計軌跡。
(通常需要一個 Event Store 負責將 Event 儲存起來,最長看見人家討論利用 Apache Kafka 來建置這個事件儲存器)!
Domain Event 是服務在完成本地狀態變更後,對外發布的事實訊息。它讓其他服務在不透過 API 直接連線的情況下,能以訂閱發佈的模式採取後續動作。
常見用途有兩類:
1. 更新 CQRS 讀模型 / 唯讀資料庫
2. Choreography Saga 模式
設計重點
• 語意聚焦於「發生了什麼」而非「要做什麼」:事件是過去事實,當某件事情完成後驅動下遊工作。
• 最終一致:事件傳遞是非同步,訂閱方以重試/去重達到一致。
• 去除重覆:每個事件具 eventId 或業務鍵,消費端必須可重放不重複。
• 順序與版本:在需要順序的聚合上使用序號(version/sequence);
事件向後相容(新增欄位不破壞舊消費者)。
• 邊界清晰:事件只公開自己擁有的資料;避免洩漏內部表結構。
• 可觀測性:事件含 traceId/correlationId,便於跨服務追蹤。
Domain Event 是把「資料變更」轉成可訂閱的事實流,支撐 CQRS 的讀側更新與 Saga 的去中心化協調,同時維持服務邊界與鬆耦合
由「消費該服務」的團隊(消費者)撰寫並維護的契約(請求/回應範本、欄位語意、錯誤碼等),服務提供者必須通過這份測試套件。
這個目的是讓**需求最清楚的一方(消費者)**主導契約,避免提供者單方面變更破壞相容。
何時用:多服務對同一提供者;或前後端/多客戶端對單一 API。
關鍵做法:消費者以測試定義期望行為(例:GET /orders/{id} 回 200、欄位型別與必填)。
容易踩雷:契約描述不完整(只寫 Happy Path)、未版本化、缺少錯誤情境。
針對客戶端程式(消費者)的測試套件,驗證它能正確與服務溝通(序列化/反序列化、路徑與標頭、逾時/重試、錯誤處理)。
目的是在不依賴真實服務的情況下,確保客戶端 SDK 或呼叫邏輯與契約相容。
客戶端邏輯複雜(重試、退版、認證流程),或需穩定在本地/CI 執行測試。
關鍵做法:以 stub/mock server(依契約產生或手工對應)模擬提供者回應。
容易踩雷:stub 與真實行為漂移;未驗證 JSON schema/欄位語意;忽略錯誤碼分支。
在伺服端組裝完整網頁;各業務能力/子網域的 Web 應用各自產生 HTML 片段(partials/tiles),由聚合層(Edge/Web Gateway、Layout Service、SSR 應用)在伺服端合併為一頁輸出給瀏覽器。
(最近的專案比較少看到了)!
在瀏覽器/客戶端組合整體 UI;各業務能力/子網域提供可獨立部署的 UI 元件(micro frontends/widgets),由殼應用(shell/app host)在客戶端載入並排版。
(大多數都採用前後端分離,以 Angular \ Vue \ React 在市場上活躍)
基本上我最常接觸到開發人員,所以對微服務架構模式中 Application Patterns 特別有感而發,花了兩天的篇幅,僅講了三個層次的第一層。
這不難理解正在導入微服務的過程中,一個開發人員必須有多少的歷練才能釐清這些事情,我運氣算比較好,唸書的時候研究服務導向,畢業後就看到微服務這個議題,誰知道過了幾年真的紅了起來。所以,在我實際上開始做這些事情之前算累積了不少的「內功」。
縱使這樣,在這幾年每次在處理這些議題的時候依然會有不同的感觸,光是搞定應用的分拆跟資料的處理我想就耗費掉大量的心神。測試上,我反而比較少提及 Microservice Architecture Pattern 上的這些概念,比較多還是先處理 Unit Test 與 TDD 的議題。總是想說有一個良好的基礎,後面前進才會比較快。現在,我依然很少看到人們在自己寫程式時謹守要有單元測試的習慣。
雖然有這些概念,但怎麼活用還是依據每個人或是團隊實際的狀況來判別,只是想說如果沒有方向,這套 Pattern Language 至少先提供了一段指引。


 iThome鐵人賽
iThome鐵人賽