在前幾篇文章中,我們已經成功完成了 Sign Language MNIST 資料集的訓練,並透過 CNN 模型進行手勢分類。接下來會將模型與 MediaPipe Hands 與 OpenCV 結合,讓電腦能夠在即時影像中辨識手勢。要讓這個系統更貼近真實應用場景,僅僅能輸出單次的推論結果還不夠,我們還需要即時的回饋機制,例如:
import cv2
import mediapipe as mp
import torch
import torchvision.transforms as transforms
from PIL import Image
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self, num_classes=24):
super(SimpleCNN, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1), nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(),
nn.MaxPool2d(2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(128 * 3 * 3, 256), nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, num_classes)
)
def forward(self, x):
return self.fc(self.cnn(x))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleCNN().to(device)
model.load_state_dict(torch.load("model.pth", map_location=device))
model.eval()
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(static_image_mode=False, max_num_hands=1)
mp_draw = mp.solutions.drawing_utils
cap = cv2.VideoCapture(0)
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.Grayscale(),
transforms.ToTensor(),
])
while True:
ret, frame = cap.read()
if not ret:
break
img_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(img_rgb)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
h, w, _ = frame.shape
x_list = [lm.x for lm in hand_landmarks.landmark]
y_list = [lm.y for lm in hand_landmarks.landmark]
xmin, xmax = int(min(x_list)*w), int(max(x_list)*w)
ymin, ymax = int(min(y_list)*h), int(max(y_list)*h)
### 加 margin
margin = 20
xmin, ymin = max(xmin - margin, 0), max(ymin - margin, 0)
xmax, ymax = min(xmax + margin, w), min(ymax + margin, h)
### ===== ROI 過小略過 =====
if xmax - xmin < 50 or ymax - ymin < 50:
continue
### 擷取 ROI
hand_roi = frame[ymin:ymax, xmin:xmax]
hand_pil = Image.fromarray(cv2.cvtColor(hand_roi, cv2.COLOR_BGR2RGB))
input_tensor = transform(hand_pil).unsqueeze(0).to(device)
### CNN 推論
with torch.no_grad():
output = model(input_tensor)
probs = torch.softmax(output, dim=1)
conf, pred = torch.max(probs, dim=1)
pred, conf = pred.item(), conf.item()
### ===== 信心度過低略過 =====
if conf < 0.7:
continue
### Label 編碼轉字母(跳過 J)
label_char = chr(pred + 65 if pred < 9 else pred + 66)
### ===== 顯示結果 =====
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
text = f"{label_char} ({conf*100:.1f}%)"
cv2.putText(frame, text, (xmin, ymin - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
mp_draw.draw_landmarks(frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)
cv2.imshow("Hand Sign Prediction", frame)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
即時辨識:使用 MediaPipe 精準追蹤手部,CNN 模型負責分類手勢。
即時回饋:在畫面上顯示手勢字母與信心度。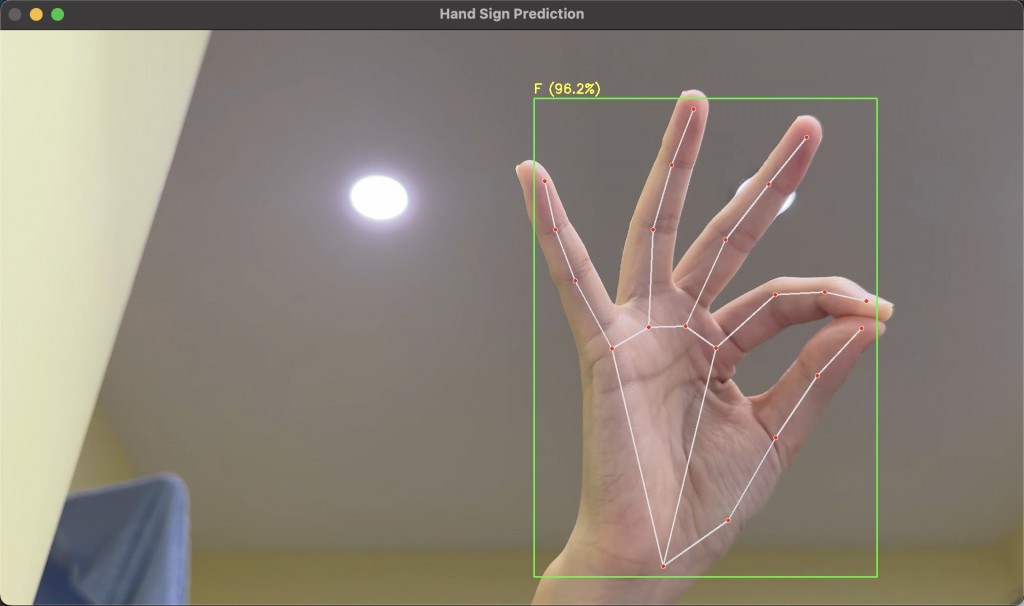

過濾機制:
使用者友善:讓整個辨識系統更穩定,避免「誤判字母跳來跳去」的情況。
手勢識別系統不僅能 即時辨識,還能透過 即時回饋機制 提升穩定性與可靠性。透過這些設計,我們離一個真正實用的「即時手勢互動系統」又更進一步。

