昨天我們開啟了一個新的系列文章,是希望從攻擊者的視角帶大家了解攻擊背後的原理,以建立好的 ethical hacking 的認知、了解如何防禦,防禦的重要性。今天我們就從最一開始「資訊搜集(Reconnaissance)」開始,去了解 Hacker 是如何從手上的資源去搜集資料。
注意,今天以及後續的系列文章僅會 cover ethical hacking 的部分,且所有類型的攻擊都會通過 VM、內部去做測試。要知道模擬攻擊是為了更好地捕捉漏洞,進而針對那些弱點去優化以及改進,而不是為了攻擊而攻擊!
當一名駭客準備發動攻擊時,第一步並不是直接敲鍵盤「駭進去」,而是像偵探一樣,會先把所有能找到的線索一一拼湊起來。這個過程叫做「資料搜集」(Reconnaissance)。而這一步為什麼這麼重要?萬事起頭難,但有了頭之後,一切就會簡單許多;而掌握越多資訊,後續的攻擊就越精準、成功率越高。
想像你要打開一扇陌生的門,如果你手上有門的照片、鑰匙形狀,甚至知道主人什麼時候會不在家,是不是比盲目亂撞容易得多?對駭客來說也是如此——他們會從網路、社群、公司官網、甚至公開的原始碼裡,悄悄地收集一切有用的線索,為後續的滲透和攻擊做好萬全準備。
所以,資料搜集不只是攻擊的開始,更是決定成敗的關鍵。
以上都是常見的分析工具,像 Shodan 索引平台,就是一個「針對公開網際網路設備/服務的搜尋引擎」,專門用來掃描 IP 範圍上的「開放埠、網路服務與其 banner」,把結果做索引,讓你可以查到各式各樣的連網裝置(伺服器、IoT 裝置、工控設備、路由器、資料庫、攝影機……)。
Web UI 使用範例:
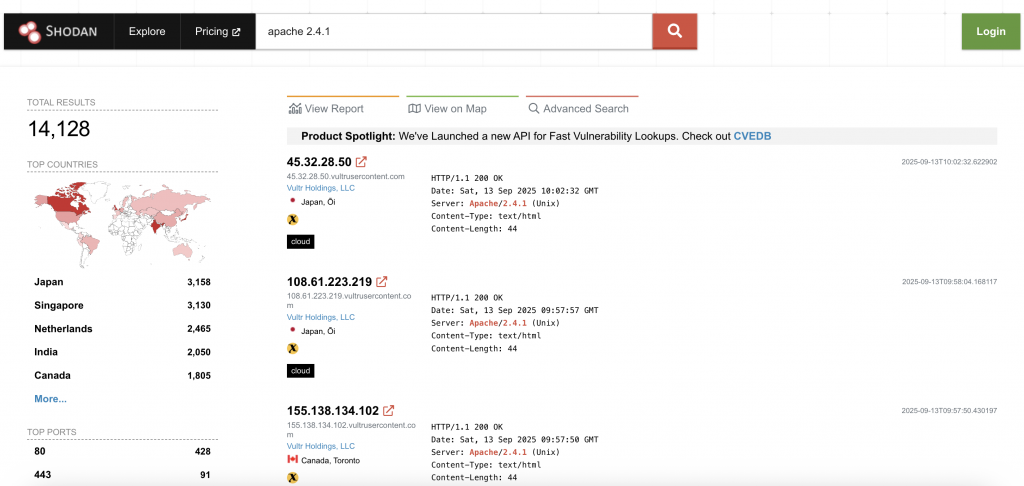
手動實際操作 shodan 示例圖
apache 與 2.4.1 的主機(Host)。注意:這不是嚴格的「產品/版本欄位精確比對」,而是對掃描到的資料做文字索引搜尋(除非使用更精確的過濾語法,要註冊登入~)。
Shodan 會顯示那些能從公網連到並回應的服務 banner;雖然會暴露資訊被第三方利用,但同時也是防守方足以識別與修補網路暴露的重要工具!
簡單程式範例:
import requests
from bs4 import BeautifulSoup
import re
# 如果沒有 headers 沒有設定 User-Agent,很容易會被系統自動阻擋!我們上個系列防火牆文章有說明!
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
}
def extract_emails(url):
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
text = soup.get_text()
# Regex 正則表達式搜尋 email
email_pattern = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
emails = re.findall(email_pattern, text)
return set(emails)
if __name__ == '__main__':
url = "請貼上你想要抓取 email 的網站網址"
emails = extract_emails(url)
print("該頁面找到的 emails:")
for email in emails:
print(email)
python-requests/X.Y.Z → X.Y.Z 是你的 python version)去發送請求的話,會無法連線成功!因為會被 WAF 或資安設備偵測到是「非正常瀏覽器的 user-agent」,或者是 HTTP/HTTPS protocol 會因為沒有正確的 header 就直接拒絕回應、關閉連線。上述程式僅為學習、合法用途示範,請勿用於未經授權的網站!且不是每個網站都允許你自動化存取,請注意合法合規哦~!
今天的內容就先到這邊,明天會分享攻擊者會怎麼運用這些資料、如何不被發現(了解攻擊方的想法才能更好的做出防禦)?以及如何預防、減少被資料搜集的風險!
再次強調!今後的所有內容,都會符合 ethical hacking 合法合規,所以在練習攻擊的同時,記得要再三確定現在做的事情是 OK 的喔!當然為了避免發生問題,我的例子都不會深入到太多太複雜(會知識、概念分享但可能不會有實際操作的部分,或者都會在 VM、內網上執行!)
我們明天見啦!👋

