重複不是省事,是技術債。
在第二個地方貼上相似度 90% 以上程式碼時,就創造了一個混亂區。
讓程式碼庫假裝有兩段獨立的邏輯,而事實上它們是應該永遠保持同步的雙胞胎。
人的記性沒那麼好。
總有一天會修好 A 點的 bug,卻完全忘了 B 點的存在。
同樣的東西寫兩次,就是在養 Bug。
辨識重複的四種類型
抽取步驟
// 🔴 臭味 同樣的邏輯重複了三次。下一個接手的人祝你好運。
function createUser(u){ if(!u.email) throw Error('bad'); return { id:u.id, email:u.email.trim().toLowerCase() }; }
function updateUser(u){ if(!u.email) throw Error('bad'); return { id:u.id, email:u.email.trim().toLowerCase() }; }
function importUser(u){ if(!u.email) throw Error('bad'); return { id:u.id, email:u.email.trim().toLowerCase() }; }
Write Everything Twice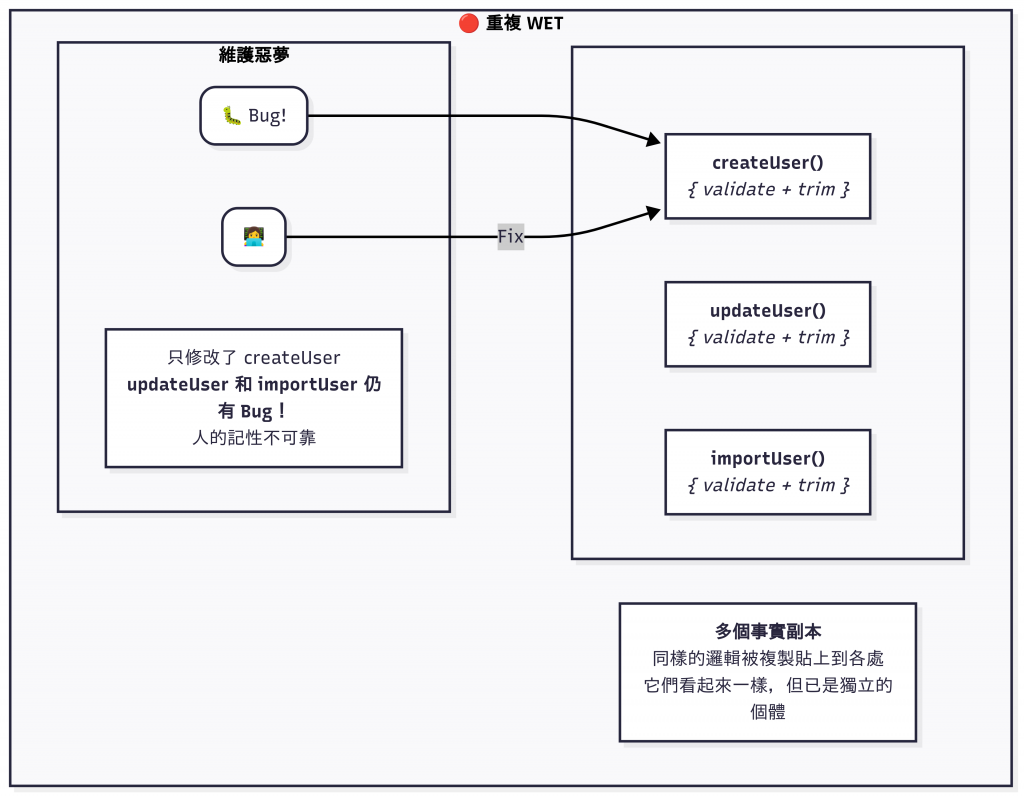
好的工程師會看到重複,然後停下來,他們會問:「這個重複的模式代表了什麼概念?」
然後,他們會給這個概念一個名字,這個概念叫 normalizeUser,專門定義一個專門的流程,來接收各式各樣可能不標準的使用者資料,並將其清理、轉換成我們系統內部統一的標準格式。
// 🟢 好品味:一次定義,到處引用。
// 這是一個「單一事實來源」(Single Source of Truth)。
// 關於使用者資料如何標準化的所有規則,都只存在於這裡。
function normalizeUser(u) {
if (!u.email) throw Error('email is required'); // 錯誤訊息也應該清晰
return { id: u.id, email: u.email.trim().toLowerCase() };
}
// 現在,這些函式變得誠實了。它們清晰地表達了自己的意圖:
// 它們的核心工作,就是執行「使用者資料標準化」。
function createUser(u){ return normalizeUser(u); }
function updateUser(u){ return normalizeUser(u); }
function importUser(u){ return normalizeUser(u); }
Don't Repeat Yourself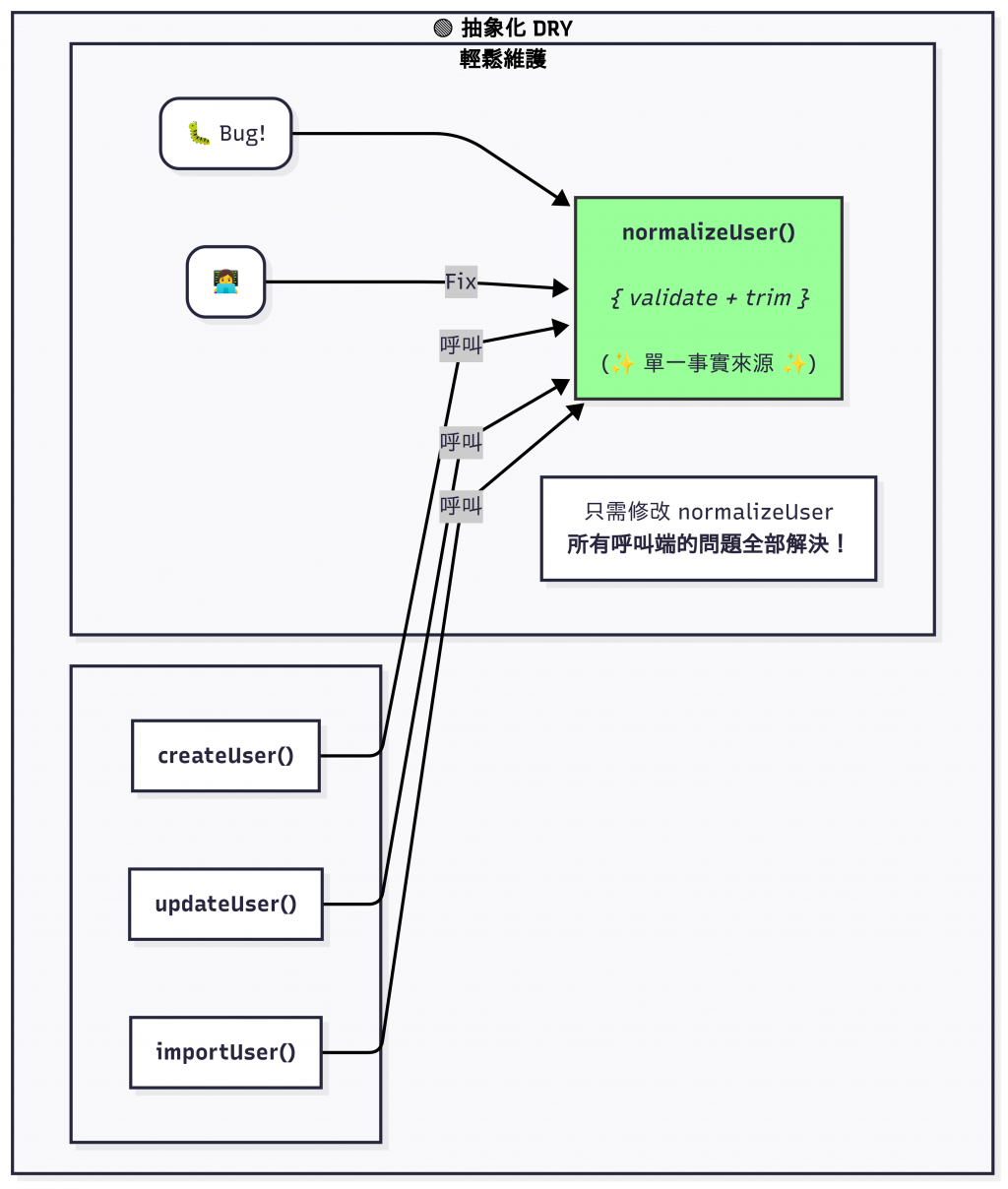
維護的單點: 現在,所有關於使用者標準化的規則都集中在一個地方。任何修改,一次完成,全局生效。沒有猜測,沒有遺漏。
意圖的彰顯: normalizeUser 這個名字本身就是文件。它告訴了所有人這段程式碼的目的。而之前那三段重複的程式碼,它們的意圖是模糊且隱含的。
這才是真正的「重用」: 不是複製貼上,而是透過一個定義良好的函式來重用一個穩定的邏輯單元。
重複一次是偶然,重複兩次是巧合,重複三次才是模式。
當你第二次寫下相似的程式碼時,要警覺。
當你準備第三次貼上時,必須停下來重構。在那之前,過早的抽象可能會讓你陷入錯誤的設計。
錯誤的抽象比重複更糟。
if 判斷和複雜參數的函式,那麼製造的問題會比解決的還多。有時候,一點點重複是可以接受的,它比一個糟糕的、扭曲的抽象要好。保持務實。一個函式是一個承諾。
它承諾一段特定的邏輯會以一種可預測且一致的方式被處理。
停止複製臭味與 Bug,開始設計可靠的函式。

