近年來,人工智慧領域迎來一波重大突破——模型開始能夠根據人類的喜好主動生成內容。
相較於傳統的機器學習與深度學習,這類模型不再只是進行單一任務的預測,而是具備理解上下文並產生新內容的能力。這樣的飛躍,正是建立在硬體加速與大型模型(Large Models)的基礎之上。
而這一切的核心,可以從「大型語言模型」(Large Language Models, LLMs)說起。
LLM 可視為生成式 AI 的基石,或稱為 backbone model。它承擔著人類賦予任務時的主要運算角色。
📖 推薦閱讀:A Survey of Large Language Models
文中對 LLM 的發展脈絡與模型架構有清晰圖示,涵蓋了從 Google 的 T5、Bard 到 OpenAI 的 ChatGPT,展示出全球大型企業在語言模型領域的佈局。
雖然生成式 AI 給人耳目一新的感受,但實際上,它的訓練方式與傳統的深度學習並無本質差異。這類語言模型的核心目標,是「預測下一個字元或單詞」。
根據前面的文字,預測下一個詞出現的機率。
數學上可表示為:
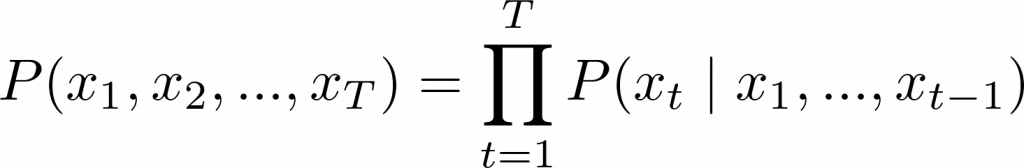
模型會依序讀取文字,學習每個詞出現的條件機率,並透過大量資料不斷優化,讓預測越來越準確。
而透過大量來自網路的文本資料,模型學習不同情境下文字的排列模式。接著,研究者再加入人類偏好來微調模型,使其學會「什麼是好的回答、什麼是錯誤的回應」。
📘 延伸閱讀:Training language models to follow instructions with human feedback
這篇論文詳細說明了透過人類回饋(Human Feedback)進行強化學習來優化模型的過程,也就是我們熟知的 RLHF(Reinforcement Learning with Human Feedback)技術。
✅ 優勢
⚠️ 挑戰
因此,如何有效且正確地使用 LLM,便成為我們這個時代不可忽視的一門新課題。
接下來我們將以「大型語言模型」為起點,逐步探討生成式 AI 的應用現況與實作技術,邀請你一起走進這個令人興奮的新世界。
感謝版主這篇精彩的分享!文章將LLM的發展背景、核心訓練原理,特別是「預測下一個字元或單詞」這一基石,以及其優劣勢解析得非常到位,對於想深入了解生成式AI的讀者而言,是個極佳的入門引導。
我很欣賞文中對於LLM挑戰的闡述,像是模型缺乏真正理解能力與幻覺問題,都點出了目前應用上的關鍵痛點。確實,幻覺問題是我們在應用LLM時必須謹慎面對的挑戰,這也突顯了Prompt Engineer這類新興角色的重要性。
非常期待後續能看到更多關於生成式AI應用與實作技術的深入探討!也歡迎版主有空參考我的系列文「南桃AI重生記」:
https://ithelp.ithome.com.tw/users/20046160/ironman/8311

